防伪码:去时风雨锁寒江 归来落樱染轻裳 山河无恙在我胸 愿君归来若春风
将近两年多没给大家更新文章了,今天晚上来点干货。总体来说19年到现在大环境不太好,各行各业都受影响,前段时间听说苏宁开启全员卖货模式 连副总裁都开始在朋友圈卖内裤了,哈哈哈,真是患难见忠臣啊,当然也听说xx二手车强制转岗、降薪,变相裁员。疫情期间威胁员工主动离职,不给赔偿,更可恶的是HR私自登录员工系统提交离职报告。我微信里的一个做二手服务器回收的老哥,18年收了两千多万的服务器,去年一半都不到;还有的朋友,单位开不出来工资,生活也受到很大的影响。总而言之,我是比较幸运的,有稳定的工作,有时候也会做一些游戏代练挣一些外快,反正吃饱饭是没问题了,哈哈。
来说说自己的情况吧,2.3号回来就一直在工作,偶尔也会登录Boss直聘投投简历,看看用人单位有哪些技能要求,但是很无奈,要么多半是外包,要么就是已读不回,还有的拿了你的简历就没影了,曾经我手机上唯一的求职软件,我也要卸载了。想想这些年,3584次沟通,投递779份简历,也算是给我的运维经历画上完美的句号了,如图所示:

前一段时间正式开始启用智联招聘,哇,真的是让我眼前一亮,以前不可以和HR沟通,现在也可以沟通了,而且每日签到功能还有各种福利,例如简历超级曝光、优先推荐、offer迷你吸铁石、精美简历模板、超级面霸养成,而且你一投递简历,很快就有HR联系你,总体体验感是非常棒的,我也来说说我找工作的要求吧:1、距离超过35km不考虑(时间成本)2、外包不考虑(无归属感,福利待遇得不到保障)3、规模比较小的不考虑(有可能发不出工资,或者掐网线也是你负责哈哈)4、第一轮去直接技术面试,否则免谈,跟你扯半天还不如实打实的来一场技术的碰撞。下图是我在智联招聘盲投5天的结果。

接下来咱们就开始聊技术吧,我把面试题发出来,大家参考一下:
**1、git和svn 的区别**Git是分布式的,而Svn不是分布的
Git把内容按元数据方式存储,而SVN是按文件
Git没有一个全局版本号,而SVN有:目前为止这是跟SVN相比Git缺少的最大的一个特征
Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏
Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以
SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况。
克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的 元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。或者,更正确的说法,每一个Git都是一个版本库,区别是它们是否拥有活跃目录(Git Working Tree)。如果主要版本库(例如:置於GitHub的版本库)发生了什麼事,工作成员仍然可以在自己的本地版本库(local repository)提交,等待主要版本库恢复即可。工作成员也可以提交到其他的版本库!
分支(Branch)在SVN,分支是一个完整的目录。且这个目录拥有完整的实际文件。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。
Git的分支名是可以使用不同名字的。例如:我的本地分支名为OK,而在主要版本库的名字其实是master。
提交(Commit)在SVN,当你提交你的完成品时,它将直接记录到中央版本库。当你发现你的完成品存在严重问题时,你已经无法阻止事情的发生了。如果网路中断,你根本没办法提交!而Git的提交完全属於本地版本库的活动。而你只需“推”(git push)到主要版本库即可。Git的“推”其实是在执行“同步”(Sync)。
总结:SVN的特点是简单,只是需要一个放代码的地方时用是OK的。
Git的特点版本控制可以不依赖网络做任何事情,对分支和合并有更好的支持(当然这是开发者最关心的地方),不过想各位能更好使用它,需要花点时间尝试一下。
2、mysql主从原理?主从不同步怎么办?主从慢,差的多咋办?
master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events)
slave将master的binary log events拷贝到它的中继日志(relay log)
slave重做中继日志中的事件,将改变反映它自己的数据。
或
从库生成两个线程,一个I/O线程,一个SQL线程;
i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
先上Master库:
mysql>show processlist; 查看下进程是否Sleep太多。发现很正常。
show master status; 也正常。
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
再到Slave上查看
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
可见是Slave不同步
下面介绍两种解决方法:
方法一:忽略错误后,继续同步
该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
之后再用mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,现在主从同步状态正常了。。。
方式二:重新做主从,完全同步
该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
解决步骤如下:
1.先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
2.进行数据备份
#把数据备份到mysql.bak.sql文件
[root@server01 mysql]#mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据万无一失
3.查看master 状态
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
4.把mysql备份文件传到从库机器,进行数据恢复
#使用scp命令
[root@server01 mysql]# scp mysql.bak.sql [email protected]:/tmp/
5.停止从库的状态
mysql> stop slave;
6.然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
7.设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = '192.168.128.100', master_user = 'rsync', master_port=3306, master_password='', master_log_file = 'mysqld-bin.000001', master_log_pos=3260;
8.重新开启从同步
mysql> start slave;
9.查看同步状态
mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
好了,同步完成啦。
如果延迟比较大,就先确认以下几个因素:
1.?从库硬件比主库差,导致复制延迟
2.?主从复制单线程,如果主库写并发太大,来不及传送到从库,就会导致延迟。更高版本的mysql可以支持多线程复制
3.?慢SQL语句过多
4.?网络延迟5.?master负载
主库读写压力大,导致复制延迟,架构的前端要加buffer及缓存层6.?slave负载
一般的做法是,使用多台slave来分摊读请求,再从这些slave中取一台专用的服务器,只作为备份用,不进行其他任何操作.
另外,?2个可以减少延迟的参数:
–slave-net-timeout=seconds?单位为秒?默认设置为?3600秒
#参数含义:当slave从主数据库读取log数据失败后,等待多久重新建立连接并获取数据
–master-connect-retry=seconds?单位为秒?默认设置为?60秒
#参数含义:当重新建立主从连接时,如果连接建立失败,间隔多久后重试。
通常配置以上2个参数可以减少网络问题导致的主从数据同步延迟
MySQL数据库主从同步延迟解决方案
最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit
=?1?之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。
3、kafka 和 mq 的区别
作为消息队列来说,企业中选择mq的还是多数,因为像Rabbit,Rocket等mq中间件都属于很成熟的产品,性能一般但可靠性较强,
而kafka原本设计的初衷是日志统计分析,现在基于大数据的背景下也可以做运营数据的分析统计,而redis的主要场景是内存数据库,作为消息队列来说可靠性太差,而且速度太依赖网络IO,在服务器本机上的速度较快,且容易出现数据堆积的问题,在比较轻量的场合下能够适用。
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上。
4、k8s service类型?
ClusterIP
集群内部容器访问地址,会生成一个虚拟IP 与pod不在一个网段。
NodePort
会在宿主机上映射一个端口,供外部应用访问模式。
Headless CluserIP
无头模式,无serviceip,即把spec.clusterip设置为None 。
LoadBalancer
使用外部负载均衡。
5、pod之间如何通信?
pod内部容器之间
这种情况下容器通讯比较简单,因为k8s pod内部容器是共享网络空间的,所以容器直接可以使用localhost访问其他容器。
k8s在启动容器的时候会先启动一个pause容器,这个容器就是实现这个功能的。
pod 与 pod 容器之间
这种类型又可以分为两种情况:
两个pod在一台主机上面
两个pod分布在不同主机之上
针对第一种情况,就比较简单了,就是docker默认的docker网桥互连容器。
第二种情况需要更为复杂的网络模型了,k8s官方推荐的是使用flannel组建一个大二层扁平网络,pod的ip分配由flannel统一分配,通讯过程也是走flannel的网桥。
6、k8s健康检查方式
存活性探针(liveness probes)和就绪性探针(readiness probes)
用户通过 Liveness 探测可以告诉 Kubernetes 什么时候通过重启容器实现自愈;Readiness 探测则是告诉 Kubernetes 什么时候可以将容器加入到 Service 负载均衡池中,对外提供服务。语法是一样的。
7、k8s pod状态
Pod --Pending状态
Pending 说明 Pod 还没有调度到某个 Node 上面。可以通过
kubectl describe pod <pod-name> 命令查看到当前 Pod 的事件,进而判断为什么没有调度。可能的原因包括
资源不足,集群内所有的 Node 都不满足该 Pod 请求的 CPU、内存、GPU 等资源
HostPort 已被占用,通常推荐使用 Service 对外开放服务端口
Pod --Waiting 或 ContainerCreating状态
首先还是通过 kubectl describe pod <pod-name> 命令查看到当前 Pod 的事件。可能的原因包括
镜像拉取失败,比如配置了镜像错误、Kubelet 无法访问镜像、私有镜像的密钥配置错误、镜像太大,拉取超时等
CNI 网络错误,一般需要检查 CNI 网络插件的配置,比如无法配置 Pod 、无法分配 IP 地址
容器无法启动,需要检查是否打包了正确的镜像或者是否配置了正确的容器参数
Pod -- ImagePullBackOff状态
这也是我们测试环境常见的,通常是镜像拉取失败。这种情况可以使用 docker pull <image> 来验证镜像是否可以正常拉取。
或者docker images | grep <images>查看镜像是否存在(系统有时会因为资源问题自动删除一部分镜像),
Pod -- CrashLoopBackOff状态
CrashLoopBackOff 状态说明容器曾经启动了,但可能又异常退出了。此时可以先查看一下容器的日志
kubectl logs <pod-name> kubectl logs --previous <pod-name>
这里可以发现一些容器退出的原因,比如
容器进程退出
健康检查失败退出
Pod --Error 状态
通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括
依赖的 ConfigMap、Secret 或者 PV 等不存在
请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
违反集群的安全策略,比如违反了 PodSecurityPolicy 等
容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
Pod --Terminating 或 Unknown 状态
从 v1.5 开始,Kubernetes 不会因为 Node 失联而删除其上正在运行的 Pod,而是将其标记为 Terminating 或 Unknown 状态。想要删除这些状态的 Pod 有三种方法:
从集群中删除该 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。而在物理机部署的集群中,需要管理员手动删除 Node(如 kubectl delete node <node-name>。
Node 恢复正常。Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。
用户强制删除。用户可以执行 kubectl delete pods <pod> --grace-period=0 --force 强制删除 Pod。除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。
特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
Pod -- Evicted状态
出现这种情况,多见于系统内存或硬盘资源不足,可df-h查看docker存储所在目录的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
8、k8s资源限制
对于一个pod来说,资源最基础的2个的指标就是:CPU和内存。
Kubernetes提供了个采用requests和limits 两种类型参数对资源进行预分配和使用限制。
limit 会限制pod的资源利用:
当pod 内存超过limit时,会被oom。
当cpu超过limit时,不会被kill,但是会限制不超过limit值。
9、软链接和硬链接区别
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的(那就和windows 下的快捷方式的那个文件有很接近的意味)。软链接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用(cat那个软链接文件,则提示“没有该文件或目录“)
硬连接是不会建立inode的,他只是在文件原来的inode link count域再增加1而已,也因此硬链接是不可以跨越文件系统的。相反是软连接会重新建立一个inode,当然inode的结构跟其他的不一样,他只是一个指明源文件的字符串信息。一旦删除源文件,那么软连接将变得毫无意义。而硬链接删除的时候,系统调用会检查inode link count的数值,如果他大于等于1,那么inode不会被回收。因此文件的内容不会被删除。
硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件。可以通过ls -i来查看一下,这两个文件的inode号是同一个,说明它们是同一个文件;而软链接建立的是一个指向,即链接文件内的内容是指向原文件的指针,它们是两个文件。
软链接可以跨文件系统,硬链接不可以;
软链接可以对一个不存在的文件名(filename)进行链接(当然此时如果你vi这个软链接文件,linux会自动新建一个文件名为filename的文件),硬链接不可以(其文件必须存在,inode必须存在);
软链接可以对目录进行连接,硬链接不可以。
两种链接都可以通过命令 ln 来创建。ln 默认创建的是硬链接。
使用 -s 开关可以创建软链接
10、mount永久挂载
vi /etc/fstab
UUID=904C23B64C23964E /media/aborn/data ntfs defaults 0 2
其中第一列为UUID, 第二列为挂载目录(该目录必须为空目录,必须存在),第三列为文件系统类型,第四列为参数,第五列0表示不备份,最后一列必须为2或0(除非引导分区为1)
11、打印一个目录下所有包含字符串A的行
例如/目录
grep -rn "A" ./
或
find ./ -name "." | xargs grep "A"
12、Kill掉所有包含服务名a的进程(xargs命令)
例如a进程
ps -ef | grep "^a" | grep -v grep | cut -c 9-15 | xargs kill -9
或
ps x | grep a | grep -v grep | awk '{print $1}' | xargs kill -9
13、谈下对systemctl理解
Linux 服务管理两种方式service和systemctl
systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动。
systemd对应的进程管理命令是systemctl
systemctl命令兼容了service, systemctl命令管理systemd的资源Unit
14、谈下对IPtables的了解
iptables其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过iptables这个代理,将用户的安全设定执行到对应的"安全框架"中,这个"安全框架"才是真正的防火墙,这个框架的名字叫netfilter
iptables其实是一个命令行工具,位于用户空间,我们用这个工具操作真正的框架。
所以说,虽然我们使用service iptables start启动iptables"服务",但是其实准确的来说,iptables并没有一个守护进程,所以并不能算是真正意义上的服务,而应该算是内核提供的功能。
iptables有4表5链:
filter表——过滤数据包
Nat表——用于网络地址转换(IP、端口)
Mangle表——修改数据包的服务类型、TTL、并且可以配置路由实现QOS
Raw表——决定数据包是否被状态跟踪机制处理
INPUT链——进来的数据包应用此规则链中的策略
OUTPUT链——外出的数据包应用此规则链中的策略
FORWARD链——转发数据包时应用此规则链中的策略
PREROUTING链——对数据包作路由选择前应用此链中的规则(所有的数据包进来的时侯都先由这个链处理)
POSTROUTING链——对数据包作路由选择后应用此链中的规则(所有的数据包出来的时侯都先由这个链处理)
15、给做好的镜像添加一个文件
用UltraISO PE (光软碟通)软件打开iso镜像文件就可以填加了
16、页面无法访问排查思路
场景一:无错误状态码
无错误状态码,多数情况下是“ERR_CONNECTION_TIMED_OUT”问题。
出现ERR_CONNECTION_TIMED_OUT错误原因,可以总结为以下5点:
服务器带宽跑满、存在***
若是云服务器可能存在账号处于欠费状态
服务没有启动
端口没有正常监听
防火墙或者防火墙策略限制
排查思路说明:
1、使用命令telnet IP Port 进行测试
2、如果端口是通的,则排查
查看服务器带宽是否跑满、是否有***
是否使用的账号处于欠费状态
3、如果端口不通,则排查
web服务没有正常启动
端口没有正常监听
防火墙/安全组拦截
若是web服务没有正常启动,需要启动服务
若是端口没有正常监听,需要修改配置文件
若是防火墙拦截,需要关闭防火墙进行测试,或者找到相关限制规则进行修改。
场景二:网站访问异常代码4XX。
排查思路:
通过查看其配置文件,并检测其配置文件语法,发现语法正常;
通过命令行查看其web服务端口运行正常,没有进程僵尸状况;
具体读配置文件,然后再查找客户客户配置文件所指定的具体目录;例如:网站数据目录等(本案例是客户机器迁移之后,由于阿里磁盘的特性导致盘符改变,客户的数据盘挂载不上,etcfstab和盘符不匹配)
问题定位到之后,重新以正确的方式挂载客户网站数据;重启服务,问题得以圆满解决;
基于类似问题还可以关注下目录权限等问题。
经验汇总:
针对网站访问报错问题几点排查建议:
服务器配置文件权限,以及语法的正确性;
配置文件中指定的网站相关目录存在问题,及相关权限问题;
运行web服务的用户和相关权限问题;
防火墙的设置问题,导致服务不可达;
服务器服务进程僵死问题;
配置文件中的非法字符问题;(特别是从windows平台直接cp过来的配置文件容易报错)这样的问题较难排查,可以通过type 命令或者 file 命令查看文件类型;最好是二进制格式或者 ascii 码,linux平台可以安装 dos2unix 解决;
服务器的错误日志亦是非常关键的问题突破口;
案例:报错“404 Not Found”
问题原因:
404报错的具体原因是访问的路径url目录在服务上没有找到,如果直接使用ip或者域名访问,那么实际访问的页面是站点根目录下的默认文件(配置文件中index后指定的文件),如果服务器上站点根目录上没有这个文件,则会出现404错误。
排查步骤:
测试环境:Nginx环境
站点跟目录/www/下没有默认index.html文件,访问ip/inde.html,会报Not Found错误。
备注:Apache环境下,404错误也是同样的原理进行排查。
17、k8s中service什么含义,怎么用
Service是一种抽象的对象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。假如我们后端运行了3个副本,这些副本都是可以替代的,因为前端并不关心它们使用的是哪一个后端服务。尽管由于各种原因后端的Pod集合会发生变化,但是前端却不需要知道这些变化,也不需要自己用一个列表来记录这些后端的服务,Service的这种抽象就可以帮我们达到这种解耦的目的。
service 为后端pod提供一组负载均衡代理
三种IP:
Node IP:Node节点的IP地址
Pod IP:Pod的IP地址
Cluster IP:Service的IP地址
首先,Node IP是Kubernetes集群中节点的物理网卡IP地址(一般为内网),所有属于这个网络的服务器之间都可以直接通信,所以Kubernetes集群外要想访问Kubernetes集群内部的某个节点或者服务,肯定得通过Node IP进行通信(这个时候一般是通过外网IP了)
然后Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的(我们这里使用的是flannel这种网络插件保证所有节点的Pod IP不会冲突)
最后Cluster IP是一个虚拟的IP,仅仅作用于Kubernetes Service这个对象,由Kubernetes自己来进行管理和分配地址,当然我们也无法ping这个地址,他没有一个真正的实体对象来响应,他只能结合Service Port来组成一个可以通信的服务。
定义Service
定义Service的方式和各种资源对象的方式类型一样,假定我们有一组Pod服务,它们对外暴露了 80 端口,同时都被打上了app=myapp这样的标签,那么我们就可以像下面这样来定义一个Service对象:
pod示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app: myapp
replicas: 3
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:- containerPort: 80
service基于pod的示例:
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
然后通过的使用kubectl create -f myservice.yaml就可以创建一个名为myservice的Service对象,它会将请求代理到使用 TCP 端口为 80,具有标签app=myapp的Pod上,这个Service会被系统分配一个我们上面说的Cluster IP,该Service还会持续的监听selector下面的Pod,会把这些Pod信息更新到一个名为myservice的Endpoints对象上去,这个对象就类似于我们上面说的Pod集合了。
需要注意的是,Service能够将一个接收端口映射到任意的targetPort。 默认情况下,targetPort将被设置为与port字段相同的值。 可能更有趣的是,targetPort 可以是一个字符串,引用了 backend Pod 的一个端口的名称。 因实际指派给该端口名称的端口号,在每个 backend Pod 中可能并不相同,所以对于部署和设计 Service ,这种方式会提供更大的灵活性。
另外Service能够支持 TCP 和 UDP 协议,默认是 TCP 协议。
kube-proxy
在Kubernetes集群中,每个Node会运行一个kube-proxy进程, 负责为Service实现一种 VIP(虚拟 IP,就是我们上面说的clusterIP)的代理形式,现在的Kubernetes中默认是使用的iptables这种模式来代理。这种模式,kube-proxy会监视Kubernetes master对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend Pod。
默认的策略是,随机选择一个 backend。 我们也可以实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
另外需要了解的是如果最开始选择的 Pod 没有响应,iptables 代理能够自动地重试另一个 Pod,所以它需要依赖 readiness probes。
Service 类型
在定义Service的时候可以指定一个自己需要的类型的Service,如果不指定的话默认是ClusterIP类型。
可以使用的服务类型如下:
1、ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。
2、NodePort:通过每个 Node 节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 :,可以从集群的外部访问一个 NodePort 服务。
3、LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,这个需要结合具体的云厂商进行操作。
4、ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
NodePort 类型
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定,如果不指定的话会自动生成一个端口。
需要注意的是,Service 将能够通过 :spec.ports[].nodePort 和 spec.clusterIp:spec.ports[].port 而对外可见。
接下来创建一个NodePort的服务
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
type: NodePort
ports: - protocol: TCP
port: 80
targetPort: 80
name: myapp-http
nodePort: 32560
创建该Service:
$ kubectl create -f service-demo.yaml
然后我们可以查看Service对象信息:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 27d
myservice NodePort 10.104.57.198 <none> 80:32560/TCP 14h
可以看到myservice的 TYPE 类型已经变成了NodePort,后面的PORT(S)部分也多了一个 32560 的随机映射端口。
ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。 对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当查询主机 my-service.prod.svc.cluster.local 时,集群的 DNS 服务将返回一个值为 my.database.example.com 的 CNAME 记录。 访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。 如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应**的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
18、和K8s服务端口冲突了怎么处理
k8s端口被占用报错执行以下命令:
kubeadm reset
19、redhat 6.X版本系统 和 centos 7.X版本有啥区别?
笔者回答:桌面系统(6/GNOE2.x、7/GNOME3.x)、文件系统(6/ext4、7/xfs)、内核版本(6/2.6x、7/3.10x)、防火墙(6/iptables、7/firewalld)、默认数据库(6/mysql、7/mariadb)、启动服务(6/service启动、7/systemctl启动)、网卡(6/eth0、7/ens192)等。
20、说一下你们公司怎么发版的(代码怎么发布的)?**
jenkins配置好代码路径(SVN或GIT),然后拉代码,打tag。需要编译就编译,编译之后推送到发布服务器(jenkins里面可以调脚本),然后从分发服务器往下分发到业务服务器上。如果是php的项目,可以rsync上线,但是php也可以用Jenkins来操作,php7之后也是支持编译运行,这样上线之后运行效率更快,而且一定程度上保证了代码的安全。
前段时间,已经确定入职单位了,然后XX文档给我发来入职邀请,我何德何能啊,真的是很感动,以下是他们技术面试官对我的评价,哈哈,装个13。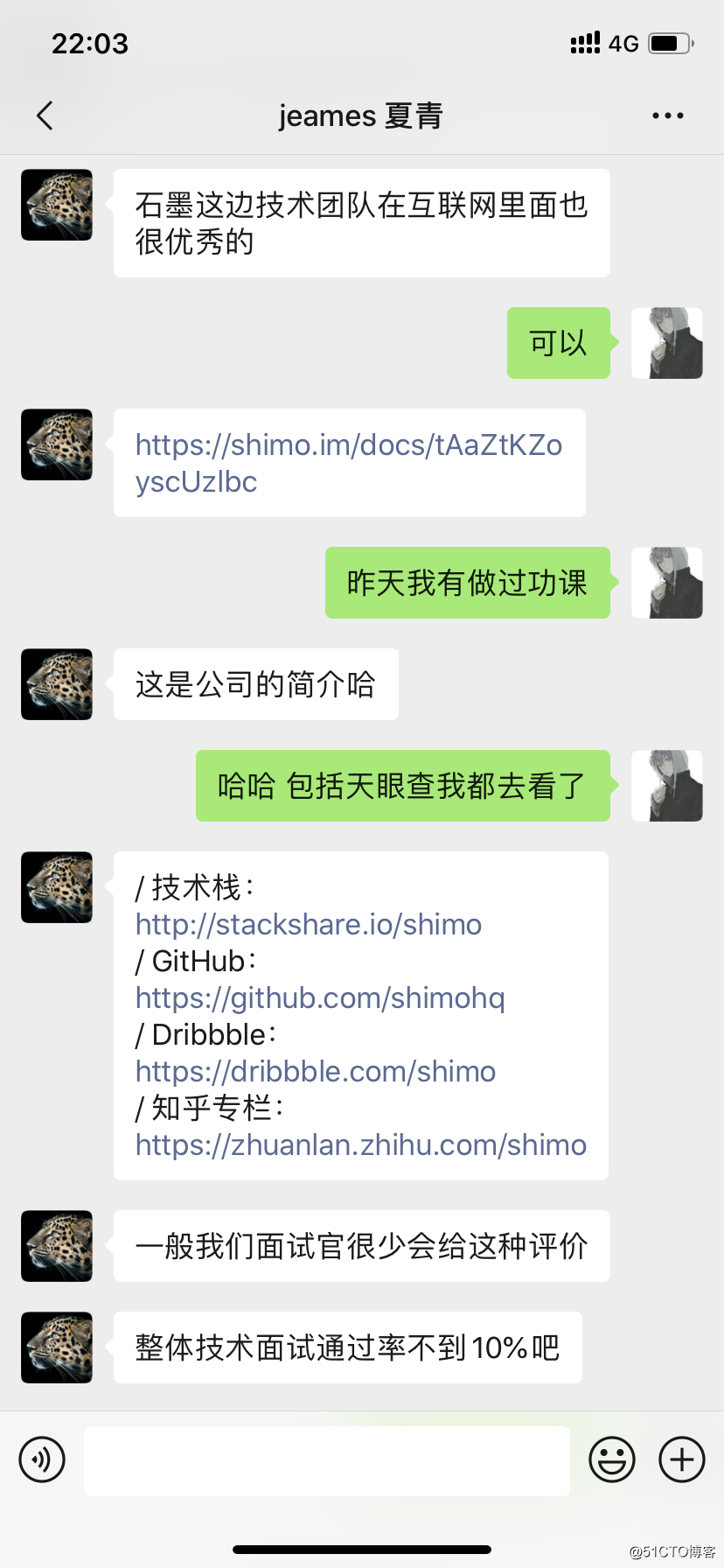
最后,想用士兵突击里的一句话激励所有朋友们:其实,你们大多数人到不了7连,更进不了老A。所以5班才是人生的标配,那么在这个饱含着希望与迷茫,掺杂着奋斗与颓废的人生草原上,你们该如何继续自己的人生,是否有勇气和毅力,修出一条属于自己的路!