性能指标:
高并发和响应快 对应着性能优化的两个核心指标 吞吐 和 延迟。这两个指标是从应用负载的视角来考察性能,直接影响产品终端用户体验。跟他们对应的是从系统资源的视角触发的指标,比如资源使用率、饱和度等
随着应用负载的增加,系统资源使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
性能分析:找出应用或者系统的瓶颈,并设法避免或者缓解它们,从而高效地利用系统资源处理更多请求

关于性能领域大师布伦丹·格雷格他的Linux性能工具图谱:

怎么理解平均负载?
当系统变慢的时候,我们经常使用top或者uptime的时候

其中参数为 当前时间,系统运行时间,正在登陆的用户数,还有1m,5m,15m的平均负载
平均负载:是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。
可运行状态的进程:是指正在使用CPU或者等待CPU的进程,也就是ps命令可以看到的处于R(running)状态的进程
不可中断状态的进程:是指正处于内核态关键流程中的进程,并且这些流程不可打断,比如常见的I/O响应,也就是我们PS命令中看到的D(Disk sleep)状态的进程

S休眠状态,Z僵尸进程
比如:当一个进程向磁盘读写数据时为了保证数据一致性,在得到磁盘恢复前,它是不能被其他进程中断打断的,这个进程处于不可中断进程。
不可中断状态实际上是系统对进程和硬件设备的一种保护机制
当CPU平均负载为2时, 1>只有2个CPU的系统,意味着CPU刚好被完全占用 2>在4个CPU的系统上,意味着CPU有50%空闲3> 1个CPU的系统上,意味着一半的进程竞争不到CPU
平均负载多少为合理:
首先要知道系统有几个CPU,可以通过top或者从文件/proc/cpuinfo中读取,其中model name
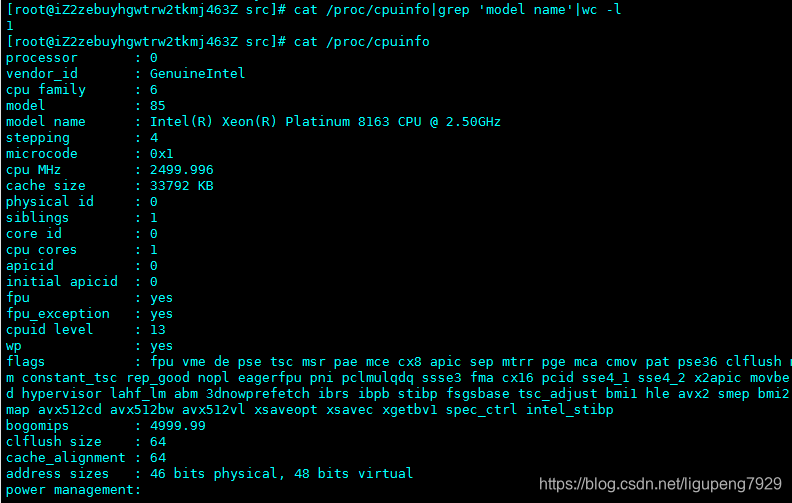
一般当平均负载高于CPU数量70%的时候,就应该排查负载高的问题,一旦负载过高可能导致进程响应变慢,进而影响服务的正常功能
平均负载与CPU使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数,所以不仅包括了正在使用CPU的进程,还包括等待CPU和等待I/O的进程。而CPU使用率是单位时间内CPU繁忙情况的统计,跟平均负载并不一定完全对应。
比如: CPU密集型服务,使用大量CPU会导致平均负载升高,此时两者一致
I/O密集型进程,等待I/O也会导致平均负载升高,但CPU使用率不一定很高。
大量等待CPU的进程调度也会导致平均负载升高,此时CPU使用率也会比较高
平均负载案例分析
场景一:CPU密集型进程
在第一个终端运行stress命令,模拟CPU使用率100%的场景
![]()
第二个终端运行uptime查看平均负载的变化情况,watch -d uptime

第三个终端运行mpstat 查看cpu使用率变化情况
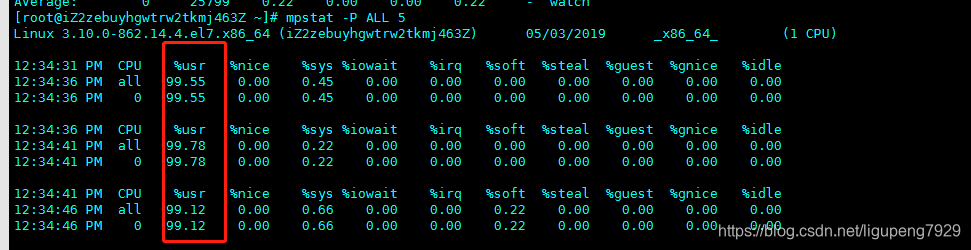
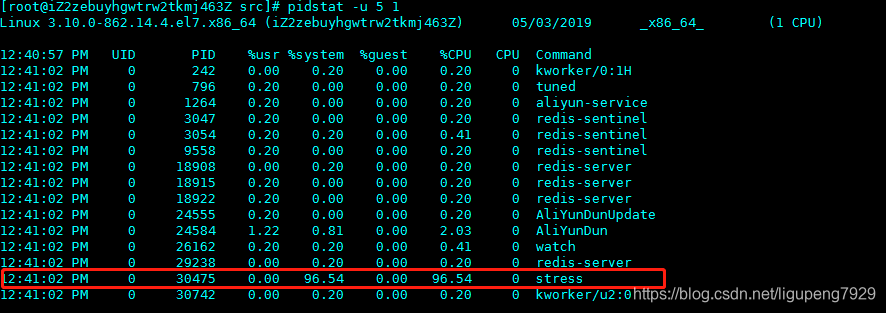
怎么查看是哪个进程导致CPU使用率为100%呢?通过pidstat来查看 执行pidstat,将输出系统启动后所有活动进程的cpu统计信息

明显看到stress进程CPU使用率为100%
场景二:I/O密集型进程
运行stress命令,模拟I/O压力,即不停地运行sync:

此时cpu的使用率变化:

而平均负载:

说明平均负载的升高是由于iowait的升高,查看哪个进程导致的iowait这么高呢?运行pidstat来查询:
大量进程的场景:
当系统中运行进程超过CPU运行能力,就会出现等待CPU的进程
stress模拟4个进程
![]()
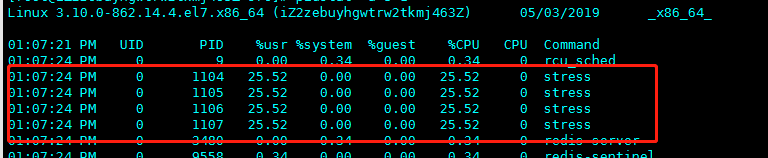
这个时候系统只有1个CPU,明显比4个进程少很多,因此系统CPU处于严重过载状态,平均负载为3.71

使用pidstat可以查看到进程情况,4个进程在争夺1一个CPU,每个进程等待CPU时间在%wait列高达75%
总结:
平均负载提供了一个快速查看整体性能的手段,反应了整体的负载情况,但只看平均负载本身,我们并不能直接发现,到底哪里出现了平均,所以在理解平均负载时也要注意:
平均负载有可能是CPU密集型进程导致的; 平均负载高并不一定代表CPU使用率高,还有可能是I/O更繁忙了;当发现负载高的时候,你可以使用mpstat、pidstat等工具分析负载的来源。
补充: pidstat -u 查看将显示各活动进程cpu使用统计。 -d可以查看进程IO的统计信息。有每秒从磁盘读取和写入的数据量以kb单位,和拉起进程对呀的命令
CPU上下文切换是什么意思?
Linux是一个多任务操作系统,支持远大于CPU数量的任务同时运行。实际上它们不是真的同时运行,而是因为系统在很短时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉
CPU上下文切换就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务,而这些保存下来的上下文会存储在系统内核中,并在任务重新调度执行时再次加载进来,这就保证任务原来状态不受影响,任务看起来还是连续运行的
CPU寄存器:CPU内置容量小、但速度极快的内存。
程序计数器:用来存储CPU正在执行的指令位置、或者即将执行的下一条指令位置。
它们都是CPU在运行任何任务前,必须的依赖环境,因此也被叫做CPU上下文,CPU上下文切换分为几个不同场景,进程上下文切换、线程上下文切换以及中断上下文切换(硬件通过出发信号,会导致中断处理程序的调用,也是场景的任务)进程和线程是常见的任务。
进程:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位.
线程:是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
一个线程可以创建和撤销另一个线程; 同一个进程中的多个线程之间可以并发执行.
1、进程上下文切换
Linux按照特权等级把进程的运行空间分为内核空间和用户空间。内核空间:具有最高权限,可以直接访问所有资源 用户空间:只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些资源(内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, intel cpu提供Ring0-Ring3三种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。Ring3状态不能访问Ring0的地址空间,包括代码和数据。)
进程在用户空间运行时被称为进程的用户态。而陷入内核空间的时候被称为进程的内核态。从用户态到内核态的转变就是通过系统调用来完成的。例如:查看文件内容就要多次系统调用:调用open()还有read()读取文件内容,并调用write()写入标准输出以及调用close()关闭文件。这里发生的CPU上下文切换时CPU寄存器原来用户态的指令位置,先保存起来,接着执行内核态代码,CPU寄存器需要更新为内核态执行新位置,最后跳转到内核态运行内核任务,最后调用结束,再次CPU寄存器切换到用户空间。
所以,一次系统调用的过程其实发生了两次CPU上下文切换。
系统调用过程并不会设计到虚拟内存等进程用户态的资源,也不会切换进程,这跟我们通常所说的进程上下文切换不同,一个是从一个进程切换到另一个进程,一个是一直在同一个进程运行。所以,系统调用通常称为特权模式切换,而不是上下文切换。但是系统调用CPU上下文切换还是无法避免的
进程的上下文切换:进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
所以切换的时候比系统调用多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存起来;而加载下一个进程的内核态后,需要刷新进程的虚拟内存和用户栈
每次上下文切换需要几十纳秒到数微秒的CPU时间,如果频繁的话很容易导致CPU大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,大大缩短了真真运行进程的时间,也是导致平均负载升高的一个重要因素。Linux通过TLB来管理虚拟内存到物理内存的映射关系,当虚拟内存更新后,TLB也需要刷新,内存访问页随之变慢,特别是多处理器系统上,缓存被多个处理器共享的,刷新缓存影响当前还有其他处理器的进程。
什么时候会切换进程上下文?只有在进程调度的时候才需要,Linux为每个CPU都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待CPU的时间排序,然后选择最需要CPU也就是优先级最高和等待CPU时间最长的进程执行
进程什么时候被调到CPU上运行?进程执行完终止了,它之前使用的CPU会释放,这个时候再从就绪队列里,拿一个新的进程来运行。
其实还有很多其他场景比如:1、进程内的时间片消耗完被系统挂起,切换进程 2、内存不足先被挂起然后调度其他进程运行 3、进程通过sleep让自己主动挂起 4、优先级更高的进程运行时 5、硬件中断,CPU进程会被中断挂起,执行内核中的中断服务程序
2、 线程的上下文切换:
区别:线程是调度的基本单位,而进程则是资源拥有的基本单位。所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源,所以对于线程和进程:
当进程只有一个线程,可以认为进程就等于线程
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时不需要修改的,需要修改的是线程的私有数据,比如栈和寄存器这些需要在上下文切换保存的。
所以线程上下文切换分为两种:
第一种:不是同进程,因为资源部共享,所以切换过程跟进程上下文切换是一样
第二种:同进程,因为虚拟内存共享所在切换时这些资源不动,主需要切换线程私有数据、寄存器等不共享的数据。
所以同为上下文切换,同进程内的线程切换,要比多进程间的切换消耗更少的资源,正是多线程代替多进程的一个优势。
3、中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调用和执行,转而调用中断处理程序,响应设备事件。而被打断的其他进程就需要将进程当前状态保存,然后就中断结束,进程仍然可以从原来的状态恢复运行
中断上下文切换并不涉及进程用户态,所以即便中断进程打断一个正处于用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户资源。只包括内核态中断服务程序执行所必需的状态包括CPU寄存器、内存堆栈、硬件中断参数等。
对于同一个CPU,中断处理比进程拥有更高的优先级,所以不会与进程上下文切换同时发生,但也需要消耗CPU,切换果断会耗费大量CPU,甚至严重降低系统整体性能。
总结:
1>CPU上下文切换时保证Linux系统正常工作的核心功能之一,一般不需要我们特别关注
2>过多的上下文切换会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统整体性能大幅下降
扩展:
【同一进程间的线程共享的资源有】
堆: 是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。
全局变量 它是与具体某一函数无关的,所以也与特定线程无关;因此也是共享的
文件等公用资源 :这个是共享的,使用这些公共资源的线程必须同步。Win32 提供了几种同步资源的方式,包括信号、临界区、事件和互斥体。
静态变量:虽然对于局部变量来说,它在代码中是“放”在某一函数中的,但是其存放位置和全局变量一样,存于堆中开辟的.bss和.data段,是共享的
【独享的资源有】
栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。操作系统在切换线程的时候会自动的切换栈,就是切换 SS/ESP寄存器。栈空间不需要在高级语言里面显式的分配和释放。
寄存器 :这个可能会误解,因为电脑的寄存器是物理的,每个线程去取值难道不一样吗?其实线程里存放的是副本,包括程序计数器PC
进程拥有这许多共性的同时,还拥有自己的个性,才能实现并发性
1.线程ID
每个线程都有自己的线程ID,这个ID在本进程中是唯一的。进程用此来标识线程。
2.寄存器组的值
由于线程间是并发运行的,每个线程有自己不同的运行线索,当从一个线程切换到另一个线程上 时,必须将原有的线程的寄存器集合的状态保存,以便将来该线程在被重新切换到时能得以恢复。
3.线程的堆栈
堆栈是保证线程独立运行所必须的。线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈, 使得函数调用可以正常执行,不受其他线程的影响。
4.错误返回码
由于同一个进程中有很多个线程在同时运行,可能某个线程进行系统调用后设置了errno值,而在该 线程还没有处理这个错误,另外一个线程就在此时被调度器投入运行,这样错误值就有可能被修改。所以,不同的线程应该拥有自己的错误返回码变量。
5.线程的信号屏蔽码
由于每个线程所感兴趣的信号不同,所以线程的信号屏蔽码应该由线程自己管理。但所有的线程都 共享同样的信号处理器。
6.线程的优先级
由于线程需要像进程那样能够被调度,那么就必须要有可供调度使用的参数,这个参数就是线程的优先级。
CPU上下文切换时什么意思(下)
怎么查看系统的上下文切换情况:
使用vmstat,主要用来分析系统的内存使用情况,也常用来分析CPU上下文切换和中断的次数。包括内核进程、虚拟内存、磁盘和 CPU 活动的统计信息。


vmstat只给了系统总体的上下文切换情况,想要查看每个进程的详细情况,就需要使用pidstat,加上-w,就可以查看每个进程上下文切换的情况。

cswch:每秒自愿上下文切换次数
nvcswch:每秒非自愿上下文切换次数
自愿上下文切换是指进程无法获取所需资源导致的上下文切换,比如IO、内存等资源不足,而非自愿上下文切换是指进程由于时间片已经到了原因强制被系统调度进而发生的上下文切换,比如大量进程争抢CPU时就发生非自愿上下文切换
案例:使用sysbench来模拟多线程调度切换的情况。
sysbench 可以进行以下测试:
CPU 运算性能测试
磁盘 IO 性能测试
调度程序性能测试
内存分配及传输速度测试
POSIX 线程性能测试
数据库性能测试(OLTP 基准测试,需要通过 /usr/share/sysbench/ 目录中的 Lua 脚本执行,例如 oltp_read_only.lua 脚本执行只读测试)
另外,sysbench 还可以通过运行命令时指定自己的 Lua 脚本来自定义测试。
首先,在第一个中断允许sysbench,模拟系统多线程调度的瓶颈
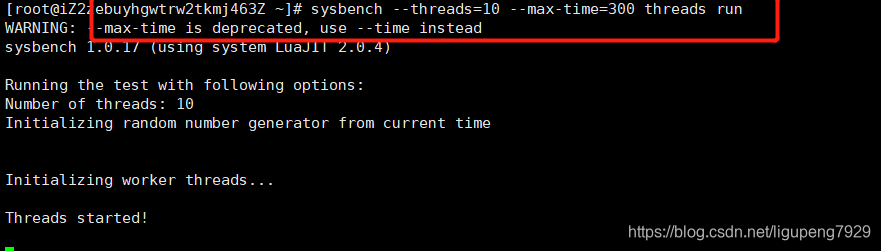
接着在第二个终端允许vmstat,观察:
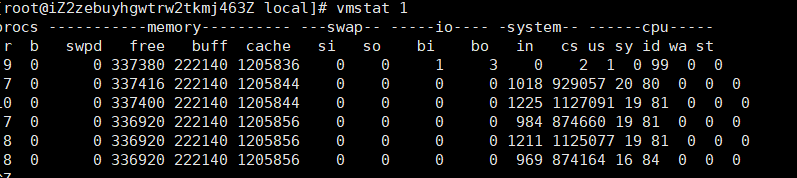
cs:上下文从35升到92万。在r列:就绪队列长度以及到了8,远远超过系统CPU的个数1,会有大量的CPU竞争
us(usr)和sy(system)列:这两列的CPU使用率加起来上升到了100%,其中系统CPU,sy高达84%,说明CPU主要被内核占用了
in列:中断次数页上升到1万左右,说明中断处理也是个潜在问题
综合这几个指标,系统的就绪队列过长,也就是正在运行和等待CPU的进程数过多,导致大量的上下文切换,而上下文切换又导致了系统的CPU占用率升高。
在第三个中断再用pidstat来看一下,CPU和进程上下文切换情况
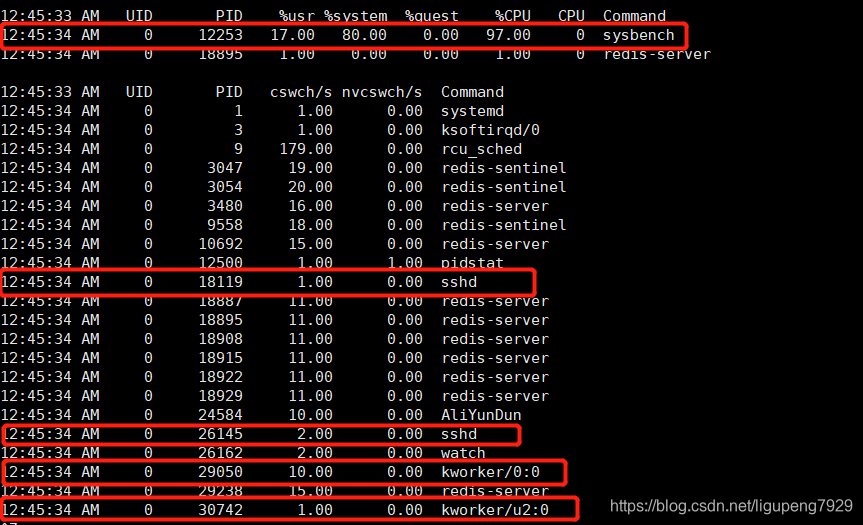
从pidstat输出可以看出来,CPU使用率升高果然是sysbench导致的,它的CPU快达到100%,但是pidstat输出上下文切换次数也就是几百,比vmstat的139万差太多。主要原因是:Linux调度的基本单位实际上是线程,sysbench模拟的也是线程的调度问题,所以的话pidstat 再加上-t参数表示输出线程的
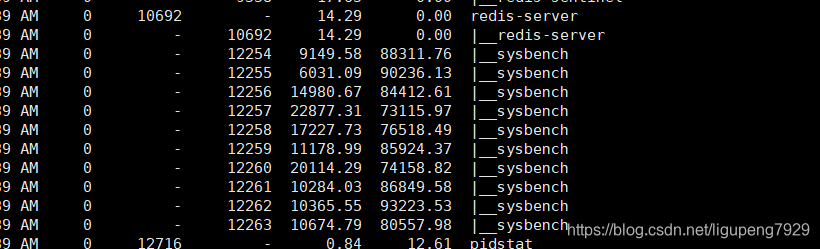
虽然sysbench进程(主线程)的上下文切换次数看起来并不多,但是它的子线程的上下文切换次数却很多。
/proc实际上是Linux的一个虚拟文件系统,用于内核空间与用户空间自己的通信
每秒上下文切换多少次才算正常?
这个数值其实取决于系统本身的CPU性能,如果系统上下文切换次数比较稳定,那么从数百到一万以内都比较正常,如果超过一万次或者出现数量级增长就出现了性能问题

