解决VQA(Visual Question Answering)问题的关键在于如何从图片和问题中提取有用的特征, 并将二者进行有效地融合。目前对于VQA问题的研究路线分为两个主要部分, 一是更好的attention机制, 二是改进的特征融合方式。一般而言这两部分属于模型独立模块, 而本文认为两者是有联系的, 应该进行有机的结合, 因而提出了一种新的co-attention机制来改善视觉特征与语言特征的融合。
我们展示了一种能够在两种模式之间实现密集的双向交互的注意机制,具体而言,我们提出了一个简单的体系结构,在视觉和语言表示之间完全对称,其中每个问题单词出现在图像区域上,每个图像区域出现在问题单词上。可以堆叠它以形成图像问题对之间的多步交互的层次结构。
模型概况
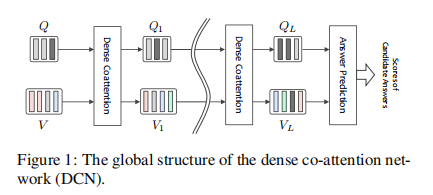
模型大致分为三个部分, 特征提取模块, 级联的Dense Co-attention模块, 以及分类器。
特征提取
1)Question and Answer Representation
问题与答案的特征提取都采用双向LS TM进行编码。具体地说,由N个单词组成的问题首先被转换成一个Glove向量序列{e1Q,…,eNQ},然后将其输入到具有剩余连接的单层双向LS TM(Bi-LSTM)中
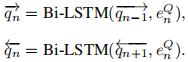
然后,我们创建了一个矩阵Q=[q1,…,qN]∈Rd×N,其中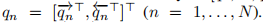 ,用
,用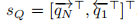 将两条路径中的最后隐藏状态串联起来,以获得输入图像的表示形式(提取图片特征要用到的)。
将两条路径中的最后隐藏状态串联起来,以获得输入图像的表示形式(提取图片特征要用到的)。
对于答案的编码: 假设有一个答案有M个词, word embedding为 {e1A,…,eNA},然后输入到相同的Bi-LSTM中,产生隐藏状态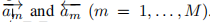 ,所以答案的表现形式为
,所以答案的表现形式为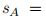
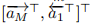
2)Image Representation
我们使用预先训练的CNN(即在Image Net上预先训练了152层的ResNet[9])来提取多个图像区域的视觉特征,但我们的提取方法略有不同。我们从四个conv中提取特征。然后在这些层上使用一个问题引导的注意力来融合它们的特征。这样做是为了利用随后密集的共同注意层的最大潜力。作者猜想,在视觉表现的层次结构中,不同层次的特征对于正确回答广泛的问题是必要的。
具体来说,就是从四个卷积中提取输出,对应的尺寸分别为(256x112x112, 512x56x56, 1024x28x28, 2048x14x14)。再采用不同的max pooling尺寸和卷积层将4种尺寸的特征,转换为统一的d×T, 其中T=14×14。对这四个层的注意是从SQ创建的,使用一个包含724个隐藏单元具有ReLU非线性的的两层神经网络,将SQ投影到四个层的分数

然后由Softmax归一化,得到四个注意权重α1…α4,通过权重对得到特征进行加权和得到矩阵V=[v1,…,vT]∈Rd×T,即对输入图像的表示。
Dense Co-Attention Module
1)框架概述
模块结构如下图所示:
输入:
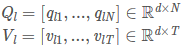
输出:
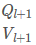
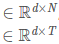

所提出的体系结构具有以下属性:
1、是一种共同注意机制
2、注意是密集的,因为它考虑到任何单词和任何区域之间的每一个相互作用。具体来说,我们的机制每个单词创建一个关于区域的注意映射,每个区域创建一个关于单词的注意映射,如2)密集的共同注意机制
3、它可以被堆叠如图一
2)Dense Co-attention Mechanism
Dense Co-attention Mechanism为上图红框部分, 结构如下图所示.

给定Ql和Vl,创建两个注意图,如图上图所示。常规的Co-attention一般分为以下几个步骤:
首先它们的计算从亲和矩阵开始

其中Wl 是一个可学习的权重矩阵,我们将Al按行归一化,以导出由每个图像区域作为条件的问题词的注意图:

还将Al按列规范化,以导出由每个问题词作为条件的图像区域上的注意图,即:

注意,AQL和AVL的每一行都包含一个注意图。

Nowhere-to-attend and memory 对于解答某一个问题, 如果没有图像框值得去注意(依靠常识或者猜测就可以回答?), 可以通过加入一些可训练的参数作为额外信息的来源. 具体做法如下: 在图像特征和文句特征,上增加K个words或是regions的特征作为可训练参数,我们发现使用K>1是有效的,这有望作为存储有用信息的内存。更具体地说,我们在行方向上增加矩阵Ql和VL,
 ·
·
这种Ql和Vl的增强使得了Al的尺寸变为(T+ K)×(N+ K),AQl和AVl的尺寸分别为(T+ K)×(N+ K)和(N+ K)×(T+ K)
Parallel attention 在这里多个注意图,我们使用平均值而不是级联来融合多个被关注的特征。设h为低维空间的个数,dh(≡d/h)是它们的维度,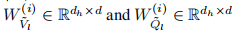 (i = 1, . . . , h)是线性投影矩阵。
(i = 1, . . . , h)是线性投影矩阵。
然后给出在第i空间中投影特征的亲和矩阵:

亲和矩阵通过列向和行向归一化得到注意图:

多个出席特征的再平均融合:

由于AQL和AVL将注意力图存储在它们的行,它们的最后K行对应于“无处可去”或内存,当我们将它们应用于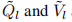 时,我们把它们丢弃,
时,我们把它们丢弃,

他们的尺寸大小分别为d×T和d × N。(表示法(1:T,:)表示第一个T行中的子矩阵,如Python中的子矩阵。
3)Fusing Image and Question Representations
特征融合在Co-attention模块中, 如下图的红绿框所示,图中也体现了dense连接, 以及标题中的Symmetric
矩阵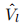 在其第n列中存储了以第n个问题字为条件的整个图像的出席表示,第n列向量
在其第n列中存储了以第n个问题字为条件的整个图像的出席表示,第n列向量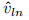 和第n个问题词的表示式qln融合,形成2d向量
和第n个问题词的表示式qln融合,形成2d向量![[q偶氮,v偶氮]](https://img-blog.csdnimg.cn/20200117151838521.png) 然后在经过ReLU激活和剩余连接:
然后在经过ReLU激活和剩余连接:

对每个问题词(n=1…N)分别应用相同的网络(具有相同的权重和偏差),产生 Ql+1 = [q(l+1)1, . . . , q(l+1)N] ∈ Rd×N .
同样的,
 对每个图像区域的应用(t=1…T)分别应用相同的网络(具有相同的权重和偏差),产生 Vl+1 = [v(l+1)1, . . . , v(l+1)T] ∈ Rd×T .
对每个图像区域的应用(t=1…T)分别应用相同的网络(具有相同的权重和偏差),产生 Vl+1 = [v(l+1)1, . . . , v(l+1)T] ∈ Rd×T .
应该注意的是,上述两个完全连接的网络有不同的参数(即WQl、WVl等)
Answer Prediction
给定最后一个密集共同注意层的最终输出QL和VL,因为它们包含N个问题词和T个图像区域的表示,我们首先对它们执行自我注意函数,以获得整个问题和图像的聚合表示。这是对QL的如下操作:
1)通过在其隐层中应用具有ReLU非线性的两层MLP计算“分数”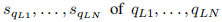
2)通过Softmax导出注意权重α1Q,…,αNQ;
3)通过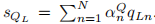 计算聚合表示
计算聚合表示
同样的,用相同的步骤采用不同的MLP可以算出注意权重α1V,…,αNV,然后从vL1,…vLT中计算聚合表示SVL。
利用SQL和SVL进行计算来预测答案,我们考虑三种方法来做到这一点。
第一种是计算SQL和SVL和SA之间的内积(SA在第1)Question and Answer Representation这部分讲过),
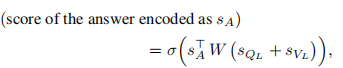
第二种和第三种是使用MLP计算一组预定义答案的分数,这是最近研究中广泛使用的方法。分别是:
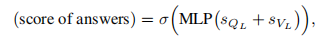
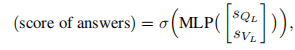
第一个是最灵活的,因为它允许我们处理在训练整个网络时没考虑的任何答案。
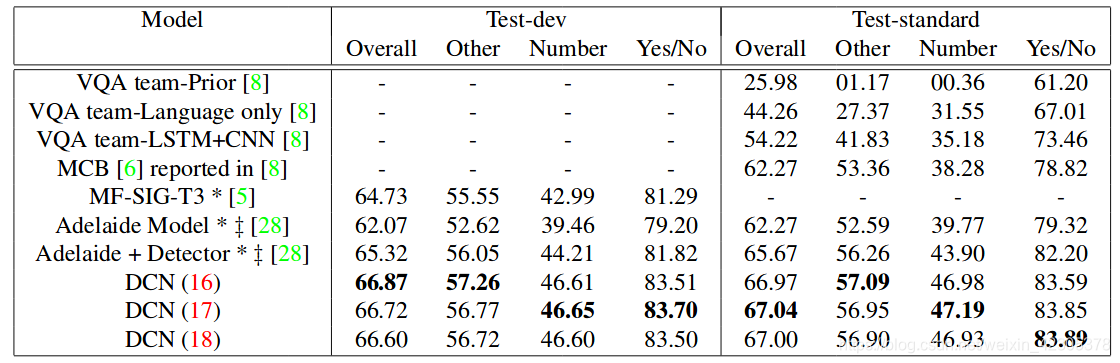
实验结果VQA2.0
小结
(1)提出可堆叠执行的Dense Co-Attention的结构
(2)针对Co-Attention结构进行改进的操作,该层结构结合初始特征提取步骤和最终答案预测层,都具有他们自己的注意力机制,形成密集的共同注意网络
