Milvus 发布了 0.71 版本。Milvus 向量搜索引擎能够帮助用户轻松应对海量非结构化数据(图片/视频/语音/文本)检索。单节点 Milvus 可以在秒内完成十亿级的向量搜索,分布式架构亦能满足用户的水平扩展需求。
| 版本兼容

| 新增功能
针对 FLAT 索引类型,新增子结构(substructure)和超结构(superstructure)距离计算方式。这两种距离计算方式常用于化学分子式的子结构和超结构搜索。
https://github.com/milvus-io/milvus/issues/1603
| 主要改进
-
改善了 Compact 操作的性能。issue# 1619
-
改善了 Milvus 使用 CPU 进行查询的性能,特别是提高了在多连接并发场景下的
查询性能。issue#267
-
改善了 nq 小于 CPU 线程数时 Milvus 的搜索性能。pull#1690
-
对于多个客户端的相同查询请求,Milvus 会将进行合并查询,从而显著提高查询
速度。issue#1728
扫描二维码关注公众号,回复: 10402545 查看本文章
-
Mishards 同步升级到 0.7.1。issue#1698
| Bug 修复
-
详情请参考 CHANGELOG。
https://github.com/milvus-io/milvus/blob/master/CHANGELOG.md
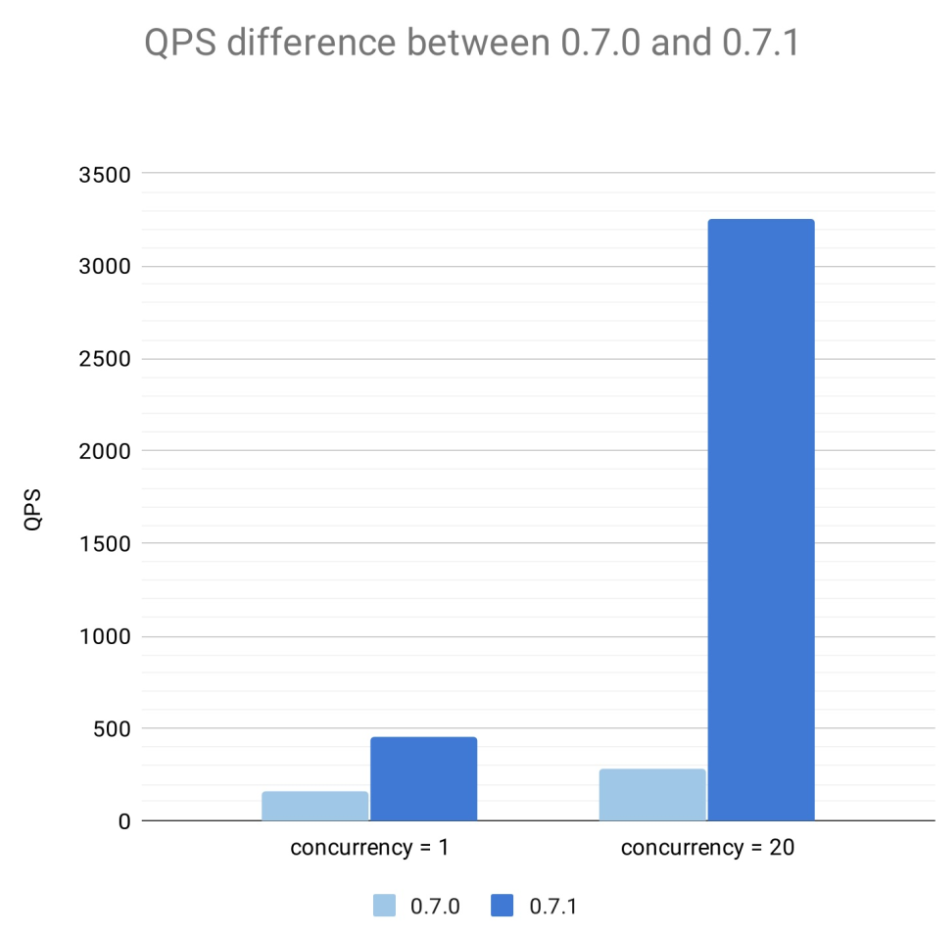
| 与0.7.0版本的性能对比
我们对 0.7.0 版本与 0.7.1 版本在单进程和多并发情况下的 QPS (Queries per Second,每秒钟查询数)进行了测试。结果表明,0.7.1 版本无论在单进程还是多并发情况下都有较大的性能提升,在多并发条件下的性能提升尤其显著。
测试条件
| CPU |
Intel i7-8700 3.20GHz 12 core |
| GPU |
GeForce GTX 1660 6GB |
| 内存 |
32 GB |
| Milvus 元数据管理数据库 |
MySQL |
| Milvus 类型 |
支持 GPU 的 Milvus |
| 客户端 |
C++ SDK |
| 查询数据集规模 |
1,000,000 |
| 索引类型 |
IVFSQ8 |
| 向量距离 |
欧氏距离(L2) |
| 向量维度 |
128 |
| nq (目标向量个数) |
1 |
| topk(查询结果中作为结果的向量个数) |
10 |
| nprobe(查询时所涉及的向量类的个数) |
16 |
| nlist(建立索引时对向量数据文件进行聚类运算的分簇数) |
16384 |
| index_file_size(自动创建索引的数据文件大小) |
1024 MB |
| 查询次数 |
1000 |
性能对比
有任何问题吗?可以来 GitHub 帮我们提个 issue 或是加入 Milvus 线上交流群。你们的反馈是社区不断进步的动力!
| 欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码
milvus.io | 官网
milvusio.slack.com | Slack 社区
zhihu.com/org/zilliz-11/columns | 知乎
zilliz.blog.csdn.net | CSDN 博客