原文地址:https://blog.csdn.net/u011665991/article/details/89206148
目录
这篇文章多数答案都是出自网上,同时对很多文章进行阅读和拼接,所以没有写明出处,有些感觉写的不错或者比较好理解的文章就附了一个连接,有很多答案不是很细致,如果想细致研究,每个问题可以延伸一篇篇幅很长的文章,所以需要单独花时间去了解学习。其实面试题很多技术也没有用过,从网上看一些文章,大体写一下,可能会存在问题,后面有时间,我会将知识点系统看一篇,完善和补充,欢迎大家提意见
本文的主题,我们这份面试题,包含的内容了十九了模块:Java 基础、容器、多线程、反射、对象拷贝、Java Web 模块、异常、网络、设计模式、Spring/Spring MVC、Spring Boot/Spring Cloud、Hibernate、Mybatis、RabbitMQ、Kafka、Zookeeper、MySql、Redis、JVM 。如下图所示:

适宜阅读人群
需要面试的初/中/高级 java 程序员
想要查漏补缺的人
想要不断完善和扩充自己 java 技术栈的人
java 面试官
下面一起来看 208 道面试题,具体的内容。
一、Java 基础
1.JDK 和 JRE 有什么区别?
- JDK:Java Development Kit 的简称,Java 开发工具包,提供了 Java 的开发环境和运行环境。
- JRE:Java Runtime Environment 的简称,Java 运行环境,为 Java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 Java 源码的编译器 Javac,还包含了很多 Java 程序调试和分析的工具。简单来说:如果你需要运行 Java 程序,只需安装 JRE 就可以了,如果你需要编写 Java 程序,需要安装 JDK
2.== 和 equals 的区别是什么?
== 的作用
- 基本类型:比较的是值是否相同。
- 引用类型:比较的是引用是否相同。
equals 的作用:比较的都是值是否相同。
【代码示例】
String x = "string";
String y = "string";
String z = new String("string");
System. out. println(x==y); // true
System. out. println(x==z); // false
System. out. println(x. equals(y)); // true
System. out. println(x. equals(z)); // true
【代码解读】
因为 x 和 y 指向的是同一个引用,所以 == 也是 true,而 new String() 方法则重写开辟了内存空间,所以 == 结果为 false,而 equals 比较的一直是值,所以结果都为 true。
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不对,两个对象的 hashCode() 相同,equals() 不一定 true。
【代码示例】
String str1 = "通话";
String str2 = "重地";
System. out. println(String. format("str1:%d | str2:%d", str1. hashCode(),str2. hashCode()));
System. out. println(str1. equals(str2));【代码结果】
str1:1179395 | str2:1179395
false【代码解读】
很显然“通话”和“重地”的 hashCode() 相同,然而 equals() 则为 false,因为在散列表中,hashCode() 相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
4.final 在 java 中有什么作用?
- final 修饰的类叫最终类,该类不能被继承。
- final 修饰的方法不能被重写。
- final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
5.java 中的 Math.round(-1.5) 等于多少?
等于 -1,Math. round 四舍五入大于 0. 5 向上取整的。
6.String 属于基础的数据类型吗?
String 不属于基础类型,基础类型有 8 种:byte、boolear、char、short、int、float、long、double,String 属于对象。
7.java 中操作字符串都有哪些类?它们之间有什么区别?
操作字符串的类有:String、StringBuffer、StringBuilder。
String 和 StringBuffer、StringBuilder 的区别在于 :
String 声明的是不可变的对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象,
而 StringBuffer、StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
StringBuffer 和 StringBuilder 最大的区别在于:
| 线程是否安全 | 性能 | 推荐使用场景 | |
| StringBuffer | 线程安全 | 低 | 多线程环境 |
| StringBuilder | 非线程安全 | 高 | 单线程环境 |
8.String str="i"与 String str=new String(“i”)一样吗?
不一样,因为内存的分配方式不一样。String str="i"的方式,Java 虚拟机会将其分配到常量池中;而 String str=new String("i") 则会被分到堆内存中。
9.如何将字符串反转?
【代码示例】
使用 StringBuilder 或者 stringBuffer 的 reverse() 方法。
// StringBuffer reverse
StringBuffer stringBuffer = new StringBuffer();
stringBuffer. append("abcdefg");
System. out. println(stringBuffer. reverse()); // gfedcba
// StringBuilder reverse
StringBuilder stringBuilder = new StringBuilder();
stringBuilder. append("abcdefg");
System. out. println(stringBuilder. reverse()); // gfedcba10.String 类的常用方法都有那些?
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
11.抽象类必须要有抽象方法吗?
不需要,抽象类不一定非要有抽象方法。
【代码示例】
abstract class Cat {
public static void sayHi() {
System. out. println("hi~");
}
}12.普通类和抽象类有哪些区别?
- 普通类不能包含抽象方法,抽象类可以包含抽象方法。
- 抽象类不能直接实例化,普通类可以直接实例化。
13.抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类
14.接口和抽象类有什么区别?
- 默认方法实现:抽象类可以有默认的方法实现;接口不能有默认的方法实现。
- 实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
- 构造函数:抽象类可以有构造函数;接口不能有。
- main 方法:抽象类可以有 main 方法,并且我们能运行它;接口不能有 main 方法。
- 实现数量:类可以实现很多个接口;但是只能继承一个抽象类。
- 访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符。
15.java 中 IO 流分为几种?
- 按功能来分:输入流(input)、输出流(output)
- 按类型来分:字节流和字符流。
- 字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
16.BIO、NIO、AIO 有什么区别?
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
17.Files的常用方法都有哪些?
- Files. exists():检测文件路径是否存在。
- Files. createFile():创建文件。
- Files. createDirectory():创建文件夹。
- Files. delete():删除一个文件或目录。
- Files. copy():复制文件。
- Files. move():移动文件。
- Files. size():查看文件个数。
- Files. read():读取文件。
- Files. write():写入文件。
二、容器
18.java 容器都有哪些?
- Collection
- List
- ArrayList
- LinkedList
- Vector
- Stack
- Set
- HashSet
- LinkedHashSet
- TreeSet
- List
- Map
- HashMap
- LindedHashMap
- TreeMap
- ConcurrentHashMap
- Hashtable
- HashMap
19.Collection 和 Collections 有什么区别?
- Collection 是一个集合接口,提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
- Collections 是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法: Collections. sort(list)
20.List、Set、Map 之间的区别是什么?
List、Set、Map 的区别主要体现在两个方面:元素是否有序、是否允许元素重复。
具体可以参考这篇文章:https://www.cnblogs.com/IvesHe/p/6108933.html
21.HashMap 和 Hashtable 有什么区别?
- 存储:HashMap 运行 key 和 value 为 null,而 Hashtable 不允许。
- 线程安全:Hashtable 是线程安全的,而 HashMap 是非线程安全的。
- 推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
22.如何决定使用 HashMap 还是 TreeMap?
对于在 Map 中插入、删除、定位一个元素这类操作,HashMap 是最好的选择,因为相对而言 HashMap 的插入会更快,但如果你要对一个 key 集合进行有序的遍历,那 TreeMap 是更好的选择
23.说一下 HashMap 的实现原理?
HashMap 基于 Hash 算法实现的,我们通过 put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。
24.说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
25.ArrayList 和 LinkedList 的区别是什么?
- 数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
26.如何实现数组和 List 之间的转换?
- 数组转 List:使用 Arrays. asList(array) 进行转换。
- List 转数组:使用 List 自带的 toArray() 方法。
【代码示例】
// list to array
List<String> list = new ArrayList<String>();
list. add("王磊");
list. add("的博客");
list. toArray();
// array to list
String[] array = new String[]{"王磊","的博客"};
Arrays. asList(array);27.ArrayList 和 Vector 的区别是什么?
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector。
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
28.Array 和 ArrayList 有何区别?
- Array 可以存储基本数据类型和对象,ArrayList 只能存储对象。
- Array 是指定固定大小的,而 ArrayList 大小是自动扩展的。
- Array 内置方法没有 ArrayList 多,比如 addAll、removeAll、iteration 等方法只有 ArrayList 有。
29.在 Queue 中 poll()和 remove()有什么区别?
- 相同点:都是返回第一个元素,并在队列中删除返回的对象。
- 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
【代码示例】
Queue<String> queue = new LinkedList<String>();
queue. offer("string"); // add
System. out. println(queue. poll());
System. out. println(queue. remove());
System. out. println(queue. size());30.哪些集合类是线程安全的?
Vector、Hashtable、Stack 都是线程安全的,而像 HashMap 则是非线程安全的,不过在 JDK 1.5 之后随着 Java. util. concurrent 并发包的出现,它们也有了自己对应的线程安全类,比如 HashMap 对应的线程安全类就是 ConcurrentHashMap。
31.迭代器 Iterator 是什么?
Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。迭代器取代了 Java 集合框架中的 Enumeration,迭代器允许调用者在迭代过程中移除元素。
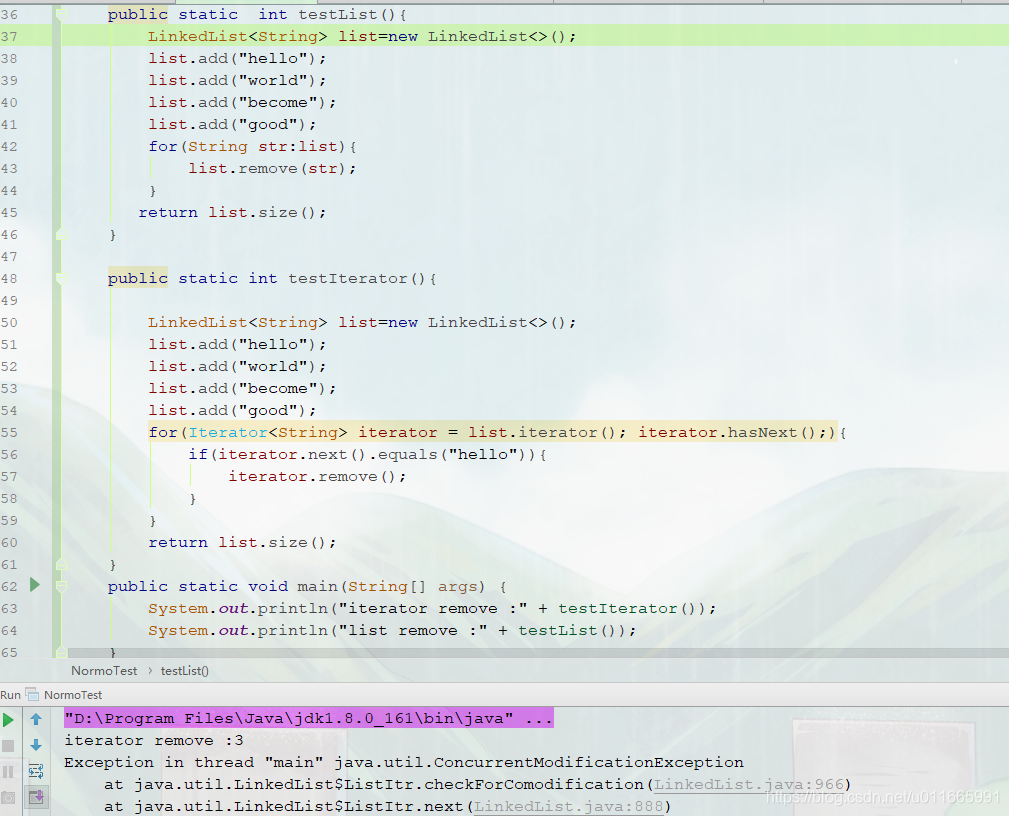
32.Iterator 怎么使用?有什么特点?
【代码示例】
List<String> list = new ArrayList<>();
Iterator<String> it = list. iterator();
while(it. hasNext()){
String obj = it. next();
System. out. println(obj);
}Iterator 的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
33.Iterator 和 ListIterator 有什么区别?
- Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。
- Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。
- ListIterator 从 Iterator 接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
34.怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
【代码示例】
List<String> list = new ArrayList<>();
list. add("x");
Collection<String> clist = Collections. unmodifiableCollection(list);
clist. add("y"); // 运行时此行报错
System. out. println(list. size());三、多线程
35.并行和并发有什么区别?
- 并行:一个处理器同时处理多个任务。
- 并发:多个处理器或多核处理器同时处理多个不同的任务。
36.线程和进程的区别?
一个程序下至少有一个进程,一个进程下至少有一个线程,一个进程下也可以有多个线程来增加程序的执行速度。
37.守护线程是什么?
守护线程是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。在 Java 中垃圾回收线程就是特殊的守护线程。
38.创建线程有哪几种方式?
创建线程有三种方式:
- 继承 Thread 重新 run 方法;
- 实现 Runnable 接口;
- 实现 Callable 接口。
39.说一下 runnable 和 callable 有什么区别?
runnable 没有返回值,callable 可以拿到有返回值,callable 可以看作是 runnable 的补充。
40.线程有哪些状态?
线程的状态:
- NEW 尚未启动
- RUNNABLE 正在执行中
- BLOCKED 阻塞的(被同步锁或者IO锁阻塞)
- WAITING 永久等待状态
- TIMED_WAITING 等待指定的时间重新被唤醒的状态
- TERMINATED 执行完成
41.sleep() 和 wait() 有什么区别?
- 类的不同:sleep() 来自 Thread,wait() 来自 Object。
- 释放锁:sleep() 不释放锁;wait() 释放锁。
- 用法不同:sleep() 时间到会自动恢复;wait() 可以使用 notify()/notifyAll()直接唤醒。
42.notify()和 notifyAll()有什么区别?
notifyAll()会唤醒所有的线程,notify()之后唤醒一个线程。notifyAll() 调用后,会将全部线程由等待池移到锁池,然后参与锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。而 notify()只会唤醒一个线程,具体唤醒哪一个线程由虚拟机控制。
43.线程的 run()和 start()有什么区别?
start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。run() 可以重复调用,而 start() 只能调用一次。
44.创建线程池有哪几种方式?
线程池创建有七种方式,最核心的是最后一种:
- newSingleThreadExecutor():它的特点在于工作线程数目被限制为 1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目;
- newCachedThreadPool():它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过 60 秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用 SynchronousQueue 作为工作队列;
- newFixedThreadPool(int nThreads):重用指定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有 nThreads 个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目 nThreads;
- newSingleThreadScheduledExecutor():创建单线程池,返回 ScheduledExecutorService,可以进行定时或周期性的工作调度;
- newScheduledThreadPool(int corePoolSize):和newSingleThreadScheduledExecutor()类似,创建的是个 ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程;
- newWorkStealingPool(int parallelism):这是一个经常被人忽略的线程池,Java 8 才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序;
- ThreadPoolExecutor():是最原始的线程池创建,上面1-3创建方式都是对ThreadPoolExecutor的封装
45.线程池都有哪些状态?
- RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
- SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
- TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
- TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。
46.线程池中 submit()和 execute()方法有什么区别?
- execute():只能执行 Runnable 类型的任务。
- submit():可以执行 Runnable 和 Callable 类型的任务。
Callable 类型的任务可以获取执行的返回值,而 Runnable 执行无返回值。
47.在 java 程序中怎么保证多线程的运行安全?
- 方法一:使用安全类,比如 Java. util. concurrent 下的类。
- 方法二:使用自动锁 synchronized。
- 方法三:使用手动锁 Lock。
【手动锁代码示例】
Lock lock = new ReentrantLock();
lock. lock();
try {
System. out. println("获得锁");
} catch (Exception e) {
// TODO: handle exception
} finally {
System. out. println("释放锁");
lock. unlock();
}48.多线程锁的升级原理是什么?
在锁对象的对象头里面有一个 threadid 字段,在第一次访问的时候 threadid 为空,JVM 让其持有偏向锁,并将threadid 设置为其线程 id,再次进入的时候会先判断 threadid 是否尤其线程 id 一致,如果一致则可以直接使用,如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁,不会堵塞,执行一定次数之后就会升级为重量级锁,进入堵塞,整个过程就是锁升级的原理。
锁的升级的目的:在 Java 6 之后优化 synchronized 的实现方式,使用了偏向锁升级为轻量级锁再升级到重量级锁的方式,减低了锁带来的性能消耗。
锁升级是为了减低了锁带来的性能消耗。
49.什么是死锁?
当线程 A 持有独占锁a,并尝试去获取独占锁 b 的同时,线程 B 持有独占锁 b,并尝试获取独占锁 a 的情况下,就会发生 AB 两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。
50.怎么防止死锁?
- 尽量使用 tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。
- 尽量使用 Java. util. concurrent 并发类代替自己手写锁。
- 尽量降低锁的使用粒度,尽量不要几个功能用同一把锁。
- 尽量减少同步的代码块。
51.ThreadLocal 是什么?有哪些使用场景?
ThreadLocal 为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal 的经典使用场景是数据库连接和 session 管理等。
52.说一下 synchronized 底层实现原理?
synchronized 是由一对 monitorenter/monitorexit 指令实现的,monitor 对象是同步的基本实现单元。在 Java 6 之前,monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作,性能也很低。但在 Java 6 的时候,Java 虚拟机 对此进行了大刀阔斧地改进,提供了三种不同的 monitor 实现,也就是常说的三种不同的锁:偏向锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。
53.synchronized 和 volatile 的区别是什么?
- volatile 是变量修饰符;synchronized 是修饰类、方法、代码段。
- volatile 仅能实现变量的修改可见性,不能保证原子性;而 synchronized 则可以保证变量的修改可见性和原子性。
- volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
54.synchronized 和 Lock 有什么区别?
- synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
55.synchronized 和 ReentrantLock 区别是什么?
synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大,但是在 Java 6 中对 synchronized 进行了非常多的改进。
主要区别如下:
- ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
- ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
- ReentrantLock 只适用于代码块锁,而 synchronized 可用于修饰方法、代码块等。
- volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化。
56.说一下 atomic 的原理?
atomic 主要利用 CAS (Compare And Wwap) 和 volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
四、反射
57.什么是反射?
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
58.什么是 java 序列化?什么情况下需要序列化?
Java 序列化是为了保存各种对象在内存中的状态,并且可以把保存的对象状态再读出来。
以下情况需要使用 Java 序列化:
- 想把的内存中的对象状态保存到一个文件中或者数据库中时候;
- 想用套接字在网络上传送对象的时候;
- 想通过RMI(远程方法调用)传输对象的时候。
59.动态代理是什么?有哪些应用?
动态代理是运行时动态生成代理类。
动态代理的应用有 spring aop、hibernate 数据查询、测试框架的后端 mock、rpc,Java注解对象获取等。
60.怎么实现动态代理?
JDK 原生动态代理和 cglib 动态代理。JDK 原生动态代理是基于接口实现的,而 cglib 是基于继承当前类的子类实现的。
五、对象拷贝
61.为什么要使用克隆?
克隆的对象可能包含一些已经修改过的属性,而 new 出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠克隆方法了。
62.如何实现对象克隆?
- 实现 Cloneable 接口并重写 Object 类中的 clone() 方法。
- 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
63.深拷贝和浅拷贝区别是什么?
- 浅克隆:当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
- 深克隆:除了对象本身被复制外,对象所包含的所有成员变量也将复制。
六、Java Web
64.jsp 和 servlet 有什么区别?
JSP 是 servlet 技术的扩展,本质上就是 servlet 的简易方式。servlet 和 JSP 最主要的不同点在于,servlet 的应用逻辑是在 Java 文件中,并且完全从表示层中的 html 里分离开来,而 JSP 的情况是 Java 和 html 可以组合成一个扩展名为 JSP 的文件。JSP 侧重于视图,servlet 主要用于控制逻辑。
65.jsp 有哪些内置对象?作用分别是什么?
JSP 有 9 大内置对象:
- request:封装客户端的请求,其中包含来自 get 或 post 请求的参数;
- response:封装服务器对客户端的响应;
- pageContext:通过该对象可以获取其他对象;
- session:封装用户会话的对象;
- application:封装服务器运行环境的对象;
- out:输出服务器响应的输出流对象;
- config:Web 应用的配置对象;
- page:JSP 页面本身(相当于 Java 程序中的 this);
- exception:封装页面抛出异常的对象。
66.说一下 jsp 的 4 种作用域?
- page:代表与一个页面相关的对象和属性。
- request:代表与客户端发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个 Web 组件;需要在页面显示的临时数据可以置于此作用域。
- session:代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的 session 中。
- application:代表与整个 Web 应用程序相关的对象和属性,它实质上是跨越整个 Web 应用程序,包括多个页面、请求和会话的一个全局作用域。
67.session 和 cookie 有什么区别?
- 存储位置不同:session 存储在服务器端;cookie 存储在浏览器端。
- 安全性不同:cookie 安全性一般,在浏览器存储,可以被伪造和修改。
- 容量和个数限制:cookie 有容量限制,每个站点下的 cookie 也有个数限制。
- 存储的多样性:session 可以存储在 Redis 中、数据库中、应用程序中;而 cookie 只能存储在浏览器中。
【分享】
cookie 的总数量没有限制,但是每个域名的COOKIE 数量和每个COOKIE 的大小是有限制的!
- IE 每个域名限制为50 个。
- Firefox 每个域名cookie 限制为50 个。
- Opera 每个域名cookie 限制为30 个。
- Safari/webkit 貌似没有cookie 限制。但是假如cookie 很多,则会使header 大小超过服务器的处理的限制,导致错误发生。
- 不同浏览器间每个cookie 文件大小也不同
- Firefox 和safari 是4097 个字节,包括名(name)、值(value)和等号。
- Opera 是4096 个字节,包括:名(name)、值(value)和等号。
- IE 是4095 个字节,包括:名(name)、值(value)和等号。
68.说一下 session 的工作原理?
session 的工作原理是客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务器拿到 sessionid 之后,在内存找到与之对应的 session 这样就可以正常工作了。
69.如果客户端禁止 cookie 能实现 session 还能用吗?
可以用,session 只是依赖 cookie 存储 sessionid,如果 cookie 被禁用了,可以使用 url 中添加 sessionid 的方式保证 session 能正常使用。
70.spring mvc 和 struts 的区别是什么?
- 拦截级别:struts2 是类级别的拦截;spring mvc 是方法级别的拦截。
- 数据独立性:spring mvc 的方法之间基本上独立的,独享 request 和 response 数据,请求数据通过参数获取,处理结果通过 ModelMap 交回给框架,方法之间不共享变量;而 struts2 虽然方法之间也是独立的,但其所有 action 变量是共享的,这不会影响程序运行,却给我们编码和读程序时带来了一定的麻烦。
- 拦截机制:struts2 有以自己的 interceptor 机制,spring mvc 用的是独立的 aop 方式,这样导致struts2 的配置文件量比 spring mvc 大。
- 对 ajax 的支持:spring mvc 集成了ajax,所有 ajax 使用很方便,只需要一个注解 @ResponseBody 就可以实现了;而 struts2 一般需要安装插件或者自己写代码才行。
71.如何避免 sql 注入?
- 使用预处理 PreparedStatement。
- 使用正则表达式过滤掉字符中的特殊字符。
72.什么是 XSS 攻击,如何避免?
XSS 攻击:即跨站脚本攻击,它是 Web 程序中常见的漏洞。原理是攻击者往 Web 页面里插入恶意的脚本代码(css 代码、Javascript 代码等),当用户浏览该页面时,嵌入其中的脚本代码会被执行,从而达到恶意攻击用户的目的,如盗取用户 cookie、破坏页面结构、重定向到其他网站等。
预防 XSS 的核心是必须对输入的数据做过滤处理。
73.什么是 CSRF 攻击,如何避免?
CSRF:Cross-Site Request Forgery(中文:跨站请求伪造),可以理解为攻击者盗用了你的身份,以你的名义发送恶意请求,比如:以你名义发送邮件、发消息、购买商品,虚拟货币转账等。
防御手段:
- 验证请求来源地址;
- 关键操作添加验证码;
- 在请求地址添加 token 并验证。
七、异常
74.throw 和 throws 的区别?
- throw:是真实抛出一个异常。
- throws:是声明可能会抛出一个异常。
75.final、finally、finalize 有什么区别?
- final:是修饰符,如果修饰类,此类不能被继承;如果修饰方法和变量,则表示此方法和此变量不能在被改变,只能使用。
- finally:是 try{} catch{} finally{} 最后一部分,表示不论发生任何情况都会执行,finally 部分可以省略,但如果 finally 部分存在,则一定会执行 finally 里面的代码。
- finalize: 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法。
76.try-catch-finally 中哪个部分可以省略?
try-catch-finally 其中 catch 和 finally 都可以被省略,但是不能同时省略,也就是说有 try 的时候,必须后面跟一个 catch 或者 finally。
77.try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
finally 一定会执行,即使是 catch 中 return 了,catch 中的 return 会等 finally 中的代码执行完之后,才会执行。
78.常见的异常类有哪些?
- NullPointerException 空指针异常
- ClassNotFoundException 指定类不存在
- NumberFormatException 字符串转换为数字异常
- IndexOutOfBoundsException 数组下标越界异常
- ClassCastException 数据类型转换异常
- FileNotFoundException 文件未找到异常
- NoSuchMethodException 方法不存在异常
- IOException IO 异常
- SocketException Socket 异常
八、网络
79.http 响应码 301 和 302 代表的是什么?有什么区别?
301:永久重定向。
302:暂时重定向。
它们的区别是,301 对搜索引擎优化(SEO)更加有利;302 有被提示为网络拦截的风险。
【分享】
其他的一些常见的响应码 可以参考之前的一篇文章:https://blog.csdn.net/u011665991/article/details/82458808
80.forward 和 redirect 的区别?
forward 是转发 和 redirect 是重定向:
- 地址栏 url 显示:foward url 不会发生改变,redirect url 会发生改变;
- 数据共享:forward 可以共享 request 里的数据,redirect 不能共享;
- 效率:forward 比 redirect 效率高。
81.简述 tcp 和 udp的区别?
tcp 和 udp 是 OSI 模型中的运输层中的协议。tcp 提供可靠的通信传输,而 udp 则常被用于让广播和细节控制交给应用的通信传输。
两者的区别大致如下:
- tcp 面向连接,udp 面向非连接即发送数据前不需要建立链接;
- tcp 提供可靠的服务(数据传输),udp 无法保证;
- tcp 面向字节流,udp 面向报文;
- tcp 数据传输慢,udp 数据传输快;
82.tcp 为什么要三次握手,两次不行吗?为什么?
如果采用两次握手,那么只要服务器发出确认数据包就会建立连接,但由于客户端此时并未响应服务器端的请求,那此时服务器端就会一直在等待客户端,这样服务器端就白白浪费了一定的资源。若采用三次握手,服务器端没有收到来自客户端的再此确认,则就会知道客户端并没有要求建立请求,就不会浪费服务器的资源
83.说一下 tcp 粘包是怎么产生的?
tcp 粘包可能发生在发送端或者接收端,分别来看两端各种产生粘包的原因:
- 发送端粘包:发送端需要等缓冲区满才发送出去,造成粘包;
- 接收方粘包:接收方不及时接收缓冲区的包,造成多个包接收。
84.OSI 的七层模型都有哪些?
- 物理层:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
- 数据链路层:负责建立和管理节点间的链路。
- 网络层:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。
- 传输层:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。
- 会话层:向两个实体的表示层提供建立和使用连接的方法。
- 表示层:处理用户信息的表示问题,如编码、数据格式转换和加密解密等。
- 应用层:直接向用户提供服务,完成用户希望在网络上完成的各种工作。
85.get 和 post 请求有哪些区别?
- get 请求会被浏览器主动缓存,而 post 不会。
- GET使用URL或Cookie传参,而POST将数据放在BODY中。
- get 传递参数有大小限制,而 post 没有。
- post 参数传输更安全,get 的参数会明文限制在 url 上,post 不会。
说到get 和 post 请求有哪些区别,大多数同学都会想到这几个标准答案,但是这三个答案是否是正确的还是有待商榷。
1. GET使用URL或Cookie传参,而POST将数据放在BODY中
GET和POST是由HTTP协议定义的。在HTTP协议中,Method和Data(URL, Body, Header)是正交的两个概念,也就是说,使用哪个Method与应用层的数据如何传输是没有相互关系的。
HTTP没有要求,如果Method是POST数据就要放在BODY中。也没有要求,如果Method是GET,数据(参数)就一定要放在URL中而不能放在BODY中。
那么,网上流传甚广的这个说法是从何而来的呢?我在HTML标准中,找到了相似的描述。这和网上流传的说法一致。但是这只是HTML标准对HTTP协议的用法的约定。怎么能当成GET和POST的区别呢?
而且,现代的Web Server都是支持GET中包含BODY这样的请求。虽然这种请求不可能从浏览器发出,但是现在的Web Server又不是只给浏览器用,已经完全地超出了HTML服务器的范畴了。
2. GET方式提交的数据有长度限制,则POST的数据则可以非常大
先说结论:HTTP协议对GET和POST都没有对长度的限制。HTTP协议明确地指出了,HTTP头和Body都没有长度的要求。
首先是"GET方式提交的数据有长度限制",如果我们使用GET通过URL提交数据,那么GET可提交的数据量就跟URL的长度有直接关系了。而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
注意这个限制是整个URL长度,而不仅仅是你的参数值数据长度。
POST也是一样,POST是没有大小限制的,HTTP协议规范也没有对POST数据进行大小限制,起限制作用的是服务器的处理程序的处理能力。
当然,我们常说GET的URL会有长度上的限制这个说法是怎么回事呢?虽然这个不是GET和POST的本质区别,但是我们也可以说说导致URL长度限制的两方面的原因:
1. 浏览器。早期的浏览器会对URL长度做限制。而现在的具体限制是怎么样的,我自己没有亲测过,就不复制网上的说法啦。
2. 服务器。URL长了,对服务器处理也是一种负担。原本一个会话就没有多少数据,现在如果有人恶意地构造几个M大小的URL,并不停地访问你的服务器。服务器的最大并发数显然会下降。另一种攻击方式是,告诉服务器Content-Length是一个很大的数,然后只给服务器发一点儿数据,服务器你就傻等着去吧。哪怕你有超时设置,这种故意的次次访问超时也能让服务器吃不了兜着走。有鉴于此,多数服务器出于安全啦、稳定啦方面的考虑,会给URL长度加限制。但是这个限制是针对所有HTTP请求的,与GET、POST没有关系。
3. POST比GET安全,因为数据在地址栏上不可见
这个说法其实也是基于上面的1,2两点的基础上来说的,我觉得没什么问题,但是需要明白为什么使用GET在地址栏上就不安全了,以及还有没有其他原因说明“POST比GET安全”。
通过GET提交数据,用户名和密码将明文出现在URL上,因为登录页面有可能被浏览器缓存,其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
三、我的理解
“1. GET使用URL或Cookie传参,而POST将数据放在BODY中”,这个是因为HTTP协议用法的约定。并非它们的本身区别。
“2. GET方式提交的数据有长度限制,则POST的数据则可以非常大”,这个是因为它们使用的操作系统和浏览器设置的不同引起的区别。也不是GET和POST本身的区别。
“3. POST比GET安全,因为数据在地址栏上不可见”,这个说法没毛病,但依然不是GET和POST本身的区别。
虽然这三点不是它们的本身区别,但至少是它们在使用上的区别,所以我在面试这个问题时,如果面试者能够回答上面三点我基本会给个及格分。那么你想不想要更高的分数?
四、终极区别
GET和POST最大的区别主要是GET请求是幂等性的,POST请求不是。这个是它们本质区别,上面的只是在使用上的区别。
什么是幂等性?幂等性是指一次和多次请求某一个资源应该具有同样的副作用。简单来说意味着对同一URL的多个请求应该返回同样的结果。
正因为它们有这样的区别,所以不应该且不能用get请求做数据的增删改这些有副作用的操作。因为get请求是幂等的,在网络不好的隧道中会尝试重试。如果用get请求增数据,会有重复操作的风险,而这种重复操作可能会导致副作用(浏览器和操作系统并不知道你会用get请求去做增操作)。
五、我的建议
如果面试官问你这个问题时,我建议你说出上面三点,同时要说明那三点是它们在使用上的区别,当然也要把它们的终极区别给说出来。
PS:曾经有一个研读了HTTP协议的人去一家公司面试,面试官问他这个问题时,他回答“GET是用于获取数据的,POST一般用于将数据发给服务器。其他GET和POST没什么区别”,于是被刷了。
因为有些面试官心中也只有那一个“标准答案”。
86.如何实现跨域?
实现跨域有以下几种方案:
- 服务器端运行跨域 设置 CORS 等于 *;
- 在单个接口使用注解 @CrossOrigin 运行跨域;
- 使用 jsonp 跨域;
87.说一下 JSONP 实现原理?
ajax请求受同源策略影响,不允许进行跨域请求,而script标签src属性中的链接却可以访问跨域的js脚本,利用这个特性,服务端不再返回JSON格式的数据,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。
【分享】具体可以参考此文章:
https://blog.csdn.net/u011897301/article/details/52679486/
https://blog.csdn.net/u011897301/article/details/52679486/
九、设计模式
88.说一下你熟悉的设计模式?
一共23种设计模式!
引用《软件秘笈-设计模式那点事》书籍:
按照目的来分,设计模式可以分为创建型模式、结构型模式和行为型模式。
创建型模式用来处理对象的创建过程;结构型模式用来处理类或者对象的组合;行为型模式用来对类或对象怎样交互和怎样分配职责进行描述。
创建型模式用来处理对象的创建过程,主要包含以下5种设计模式:
- 工厂方法模式(Factory Method Pattern)
- 抽象工厂模式(Abstract Factory Pattern)
- 建造者模式(Builder Pattern)
- 原型模式(Prototype Pattern)
- 单例模式(Singleton Pattern)
结构型模式用来处理类或者对象的组合,主要包含以下7种设计模式:
- 适配器模式(Adapter Pattern)
- 桥接模式(Bridge Pattern)
- 组合模式(Composite Pattern)
- 装饰者模式(Decorator Pattern)
- 外观模式(Facade Pattern)
- 享元模式(Flyweight Pattern)
- 代理模式(Proxy Pattern)
行为型模式用来对类或对象怎样交互和怎样分配职责进行描述,主要包含以下11种设计模式:
- 责任链模式(Chain of Responsibility Pattern)
- 命令模式(Command Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 策略模式(Strategy Pattern)
- 模板方法模式(Template Method Pattern)
- 访问者模式(Visitor Pattern)
举两个单例模式,其他的自己网上学习吧
单例模式实现1:
public class Singleton {
// 类共享实例对象
private static Singleton singleton = null;
// 私有构造方法
private Singleton() {
System.out.println("-- this is Singleton!!!");
}
// 获得单例方法
public synchronized static Singleton getInstance() {
// 判断 共享对象是否为null ,如何为null则new一个新对象
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
}
单例模式实现2:
public class Singleton {
// 类共享实例对象 实例化
private static Singleton singleton = new Singleton();
// 私有构造方法
private Singleton() {
System.out.println("-- this is Singleton!!!");
}
// 获得单例方法
public static Singleton getInstance() {
// 直接返回共享对象
return singleton;
}
}89.简单工厂和抽象工厂有什么区别?
工厂模式主要是为创建对象提供了接口。工厂模式按照《Java与模式》中的提法分为三类:
- 1. 简单工厂模式(Simple Factory)
- 2. 工厂方法模式(Factory Method)
- 3. 抽象工厂模式(Abstract Factory)
这三种模式从上到下逐步抽象,并且更具一般性。还有一种分类法,就是将简单工厂模式看为工厂方法模式的一种特例,两个归为一类。两者皆可,这本为使用《Java与模式》的分类方法。
在什么样的情况下我们应该记得使用工厂模式呢?大体有两点:
- 1.在编码时不能预见需要创建哪种类的实例。
- 2.系统不应依赖于产品类实例如何被创建、组合和表达的细节
具体的可以参考这篇文章:https://www.cnblogs.com/zhangchenliang/p/3700820.html
十、Spring/Spring MVC
90.为什么要使用 spring?
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架,它由Rod Johnson创建。它是为了解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。
91.解释一下什么是 aop?
AOP(Aspect-Oriented Programming)指一种程序设计范型,该范型以一种称为切面(aspect)的语言构造为基础,切面是一种新的模块化机制,用来描述分散在对象、类或方法中的横切关注点(crosscutting concern)。
Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
92.解释一下什么是 ioc?
IoC就是(Inversion of Control),控制反转。在Java开发中,IoC意味着将你设计好的类交给系统去控制,而不是在你的类内部控制。这称为控制反转。
Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
93.spring 有哪些主要模块?
Spring有七大模块组成:
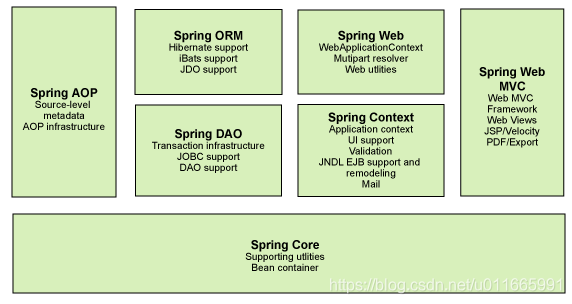
- 核心容器(Spring Core)
核心容器提供Spring框架的基本功能。Spring以bean的方式组织和管理Java应用中的各个组件及其关系。Spring使用BeanFactory来产生和管理Bean,它是工厂模式的实现。BeanFactory使用控制反转(IoC)模式将应用的配置和依赖性规范与实际的应用程序代码分开。
- 应用上下文(Spring Context)
Spring上下文是一个配置文件,向Spring框架提供上下文信息。Spring上下文包括企业服务,如JNDI、EJB、电子邮件、国际化、校验和调度功能。
- Spring面向切面编程(Spring AOP)
通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了 Spring框架中。所以,可以很容易地使 Spring框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
- JDBC和DAO模块(Spring DAO)
JDBC、DAO的抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理,和不同数据库供应商所抛出的错误信息。异常层次结构简化了错误处理,并且极大的降低了需要编写的代码数量,比如打开和关闭链接。
- 对象实体映射(Spring ORM)
Spring框架插入了若干个ORM框架,从而提供了ORM对象的关系工具,其中包括了Hibernate、JDO和 IBatis SQL Map等,所有这些都遵从Spring的通用事物和DAO异常层次结构。
- Web模块(Spring Web)
Web上下文模块建立在应用程序上下文模块之上,为基于web的应用程序提供了上下文。所以Spring框架支持与Struts集成,web模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
- MVC模块(Spring Web MVC)
MVC框架是一个全功能的构建Web应用程序的MVC实现。通过策略接口,MVC框架变成为高度可配置的。MVC容纳了大量视图技术,其中包括JSP、POI等,模型来有JavaBean来构成,存放于m当中,而视图是一个街口,负责实现模型,控制器表示逻辑代码,由c的事情。Spring框架的功能可以用在任何J2EE服务器当中,大多数功能也适用于不受管理的环境。Spring的核心要点就是支持不绑定到特定J2EE服务的可重用业务和数据的访问的对象,毫无疑问这样的对象可以在不同的J2EE环境,独立应用程序和测试环境之间重用。
94.spring 常用的注入方式有哪些?
之前写过一篇文章 常用的注解,有需要的可以参考:https://blog.csdn.net/u011665991/article/details/82460263
- @Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。
- @Scope注解 作用域
- @Lazy(true) 表示延迟初始化
- @Service用于标注业务层组件、
- @Controller用于标注控制层组件(如struts中的action)
- @Repository用于标注数据访问组件,即DAO组件。
- @Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
- @Scope用于指定scope作用域的(用在类上)
- @PostConstruct用于指定初始化方法(用在方法上)
- @PreDestory用于指定销毁方法(用在方法上)
- @DependsOn:定义Bean初始化及销毁时的顺序
- @Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的Bean将作为首选者,否则将抛出异常
- @Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下:
- @Autowired @Qualifier("personDaoBean") 存在多个实例配合使用
- @Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
- @PostConstruct 初始化注解
- @PreDestroy 摧毁注解 默认 单例 启动就加载
- @Async异步方法调用
95.spring 中的 bean 是线程安全的吗?
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的Spring bean并没有可变的状态(比如Serview类和DAO类),所以在某种程度上说Spring的单例bean是线程安全的。如果你的bean有多种状态的话(比如 View Model 对象),就需要自行保证线程安全。
最浅显的解决办法就是将多态bean的作用域由“singleton”变更为“prototype”。
96.spring 支持几种 bean 的作用域?
当通过spring容器创建一个Bean实例时,不仅可以完成Bean实例的实例化,还可以为Bean指定特定的作用域。Spring支持如下5种作用域:
-
singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的Bean将只有一个实例
-
prototype:原型模式,每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新的Bean实例
-
request:对于每次HTTP请求,使用request定义的Bean都将产生一个新实例,即每次HTTP请求将会产生不同的Bean实例。只有在Web应用中使用Spring时,该作用域才有效
-
session:对于每次HTTP Session,使用session定义的Bean豆浆产生一个新实例。同样只有在Web应用中使用Spring时,该作用域才有效
-
globalsession:每个全局的HTTP Session,使用session定义的Bean都将产生一个新实例。典型情况下,仅在使用portlet context的时候有效。同样只有在Web应用中使用Spring时,该作用域才有效
其中比较常用的是singleton和prototype两种作用域。对于singleton作用域的Bean,每次请求该Bean都将获得相同的实例。容器负责跟踪Bean实例的状态,负责维护Bean实例的生命周期行为;如果一个Bean被设置成prototype作用域,程序每次请求该id的Bean,Spring都会新建一个Bean实例,然后返回给程序。在这种情况下,Spring容器仅仅使用new 关键字创建Bean实例,一旦创建成功,容器不在跟踪实例,也不会维护Bean实例的状态。
如果不指定Bean的作用域,Spring默认使用singleton作用域。Java在创建Java实例时,需要进行内存申请;销毁实例时,需要完成垃圾回收,这些工作都会导致系统开销的增加。因此,prototype作用域Bean的创建、销毁代价比较大。而singleton作用域的Bean实例一旦创建成功,可以重复使用。因此,除非必要,否则尽量避免将Bean被设置成prototype作用域。
97.spring 自动装配 bean 有哪些方式?
Spring中bean有三种装配机制,分别是:
- 1. 在xml中显示配置;
- 2. 在java中显示配置;
- 3. 隐式的bean发现机制和自动装配。
【分享】
有需要的可以参考:https://blog.csdn.net/beirdu/article/details/78768606
98.spring 事务实现方式有哪些?
事务:事务逻辑上的一组操作,组成这组操作的各个逻辑单元,要么一起成功,要么一起失败.比如,保证数据的运行不会说A给B钱,A钱给了B却没收到。
实现事务的三种方式:
- 1.aspectJ AOP实现事务:
- 2.事务代理工厂Bean实现事务:
- 3.注解方式实现事务:
在需要进行事务的方法上增加一个注解“@Transactional(rollbackFor = MyExepction.class )”
99.说一下 spring 的事务隔离?
- 事务特性(4种):
- 原子性 (atomicity):强调事务的不可分割.
- 一致性 (consistency):事务的执行的前后数据的完整性保持一致.
- 隔离性 (isolation):一个事务执行的过程中,不应该受到其他事务的干扰
- 持久性(durability) :事务一旦结束,数据就持久到数据库
- 如果不考虑隔离性引发安全性问题:
- 脏读 :一个事务读到了另一个事务的未提交的数据
- 不可重复读 :一个事务读到了另一个事务已经提交的 update 的数据导致多次查询结果不一致.
- 虚幻读 :一个事务读到了另一个事务已经提交的 insert 的数据导致多次查询结果不一致.
- 解决读问题: 设置事务隔离级别(5种)
- DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
- 未提交读(read uncommited) :脏读,不可重复读,虚读都有可能发生
- 已提交读 (read commited):避免脏读。但是不可重复读和虚读有可能发生
- 可重复读 (repeatable read) :避免脏读和不可重复读.但是虚读有可能发生.
- 串行化的 (serializable) :避免以上所有读问题.
- Mysql 默认:可重复读
- Oracle 默认:读已提交
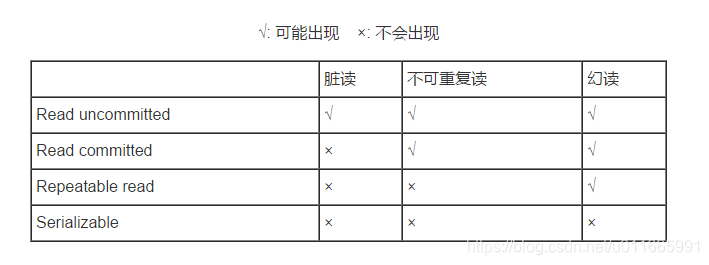
- read uncommited:是最低的事务隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。
- read commited:保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。
- repeatable read:这种事务隔离级别可以防止脏读,不可重复读。但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了以下情况产生(不可重复读)。
- serializable:这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读之外,还避免了幻象读(避免三种)。
- 事务的传播行为(7种)
PROPAGION_XXX :事务的传播行为
- * 保证同一个事务中
- PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认)
- PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务
- PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常
- * 保证没有在同一个事务中
- PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务
- PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务
- PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常
- PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
100.说一下 spring mvc 运行流程?
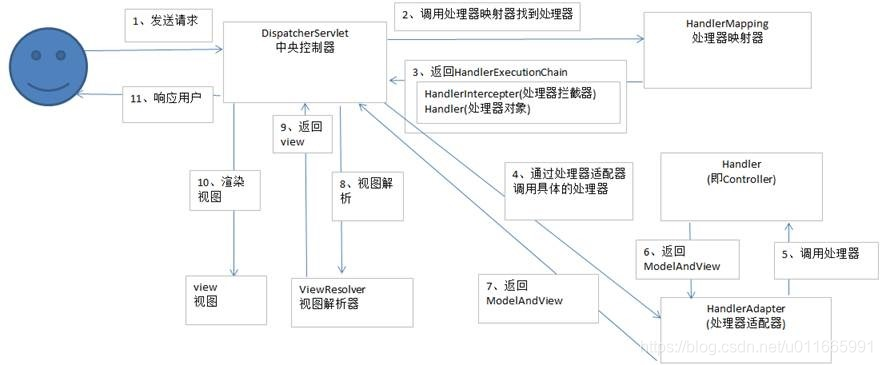
流程
- 1、用户发送请求至前端控制器DispatcherServlet
- 2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。
- 3、处理器映射器找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
- 4、DispatcherServlet调用HandlerAdapter处理器适配器
- 5、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
- 6、Controller执行完成返回ModelAndView
- 7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet
- 8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器
- 9、ViewReslover解析后返回具体View
- 10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
- 11、DispatcherServlet响应用户
101.spring mvc 有哪些组件?
| 名称 | 简介 |
HandlerMapping |
管理请求(request)和处理句柄(Handler)之间的映射关系 |
HandlerAdapter |
处理句柄适配器, 1.每个 HandlerAdapter包装一个Handler,2. HandlerAdapter主要用于隔离调用者DispatcherServlet和各式各样的Handler |
HandlerExceptionResolver |
处理句柄异常解析器 |
ViewResolver |
视图解析器:根据视图名称和Locale解析为具体View对象用来渲染页面 |
RequestToViewNameTranslator |
请求到视图名称的翻译器:从request中获取视图名称,作为ViewResolver的补充 |
LocaleResolver |
Locale地区解析器处理本地化/国际化语言相关,结合上下文和当前请求分析得到应该使用的 Locale地区 |
ThemeResolver |
主题解析器,处理UI主题(look and feel)相关 |
MultipartResolver |
Multipart上传数据解析器 |
FlashMapManager |
管理FlashMap结构的重定向参数 |
102.@RequestMapping 的作用是什么?
@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。
【分享】具体可以参考文章:https://www.cnblogs.com/qq78292959/p/3760560.html
103.@Autowired 的作用是什么?
这个注解就是spring可以自动帮你把bean里面引用的对象的setter/getter方法省略,它会自动帮你set/get。
<bean id="userDao" class="..."/>
<bean id="userService" class="...">
<property name="userDao">
<ref bean="userDao"/>
</property>
</bean>这样你在userService里面要做一个userDao的setter/getter方法。
但如果你用了@Autowired的话,你只需要在UserService的实现类中声明即可。
@Autowired
private IUserDao userdao;十一、Spring Boot/Spring Cloud
104.什么是 spring boot?
SpringBoot是一个框架,一种全新的编程规范,他的产生简化了框架的使用,所谓简化是指简化了Spring众多框架中所需的大量且繁琐的配置文件,所以 SpringBoot是一个服务于框架的框架,服务范围是简化配置文件
105.为什么要用 spring boot?
最明显的特点是,让文件配置变的相当简单、让应用部署变的简单(SpringBoot内置服务器,并装备启动类代码),可以快速开启一个Web容器进行开发
- (1)一个简单的SpringBoot工程是不需要在pom.xml手动添加什么配置的,如果与其他技术合用 比如postMan(文档在线自动生成、开发功能测试的一套工具)、Swagger(文档在线自动生成、开发功能测试的一套工具),则需要在pom.xml中添加依赖,由程序自动加载依赖jar包等配置文件。
- (2)我们之前在利用SSM或者SSH开发的时候,在resources中储存各种对应框架的配置文件,而现在我们只需要一个配置文件即可,配置内容也大体有 服务器端口号、数据库连接的地址、用户名、密码。这样,虽然简单 但在一定问题上而言,这也是极不安全的,将所有配置,放在一个文件里,是很危险的,但对于一般项目而言并不会有太大影响。
- (3)在SpringBoot创建时会自动创建Bootdemo1Application启动类,代表着本工程项目和服务器的启动加载,在springBoot中是内含服务器的,所以不需手动配置Tomact,但注意端口号冲突问题。
106.spring boot 核心配置文件是什么?
核心配置文件是指在resources根目录下的application.properties或application.yml配置文件,读取这两个配置文件的方法有两种,都比较简单
107.spring boot 配置文件有哪几种类型?它们有什么区别?
这里我理解的是两种类型 application.properties和application.yml
application.yml配置结构
spring:
application:
name: wxxcx mvc:
view:
prefix: /WEB-INF/jsp/ suffix: jspapplication.properties配置结构
spring.application.name=wxxcx
server.port = 9000
server.context-path = /
server.tomcat.uri-encoding = UTF-8
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp
108.spring boot 有哪些方式可以实现热部署?
SpringBoot热部署方式一共有两种,分别使用两种不同的依赖
SpringBoot 1.3后才拥有SpringBoot devtools热部署
①:spring-boot-devtools ②:Spring Loaded
- 方式一: 在项目的pom文件中添加依赖:
<!--热部署jar-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>- 方式二: 在项目中添加如下代码
<build>
<plugins>
<plugin>
<!-- springBoot编译插件-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<dependencies>
<!-- spring热部署 -->
<!-- 该依赖在此处下载不下来,可以放置在build标签外部下载完成后再粘贴进plugin中 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>springloaded</artifactId>
<version>1.2.6.RELEASE</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>添加完毕后需要使用mvn指令运行:
首先找到IDEA中的Edit configurations ,然后进行如下操作:(点击左上角的"+",然后选择maven将出现右侧面板,在红色划线部位输入如图所示指令,你可以为该指令命名(此处命名为MvnSpringBootRun))
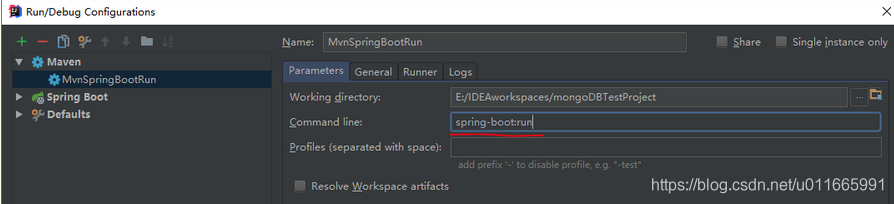
点击保存将会在IDEA项目运行部位出现,点击绿色箭头运行即可
109.jpa 和 hibernate 有什么区别?
简单的可以理解为:
- Hibernate是JPA规范的一个具体实现
- hibernate有JPA没有的特性
- hibernate 的效率更快
- JPA 有更好的移植性,通用性
【分享】
分享两篇文章供大家参考:https://www.cnblogs.com/mosoner/p/9494250.html
http://baijiahao.baidu.com/s?id=1602675844799153392&wfr=spider&for=pc
110.什么是 spring cloud?
- Spring Cloud是一个微服务框架,相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案。
- Spring Cloud对微服务基础框架Netflix的多个开源组件进行了封装,同时又实现了和云端平台以及和Spring Boot开发框架的集成。
- Spring Cloud为微服务架构开发涉及的配置管理,服务治理,熔断机制,智能路由,微代理,控制总线,一次性token,全局一致性锁,leader选举,分布式session,集群状态管理等操作提供了一种简单的开发方式。
- Spring Cloud 为开发者提供了快速构建分布式系统的工具,开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。
分享两篇文章供大家参考:https://www.cnblogs.com/lexiaofei/p/6808152.html
https://blog.csdn.net/kkkloveyou/article/details/79210420
https://spring.io/projects/spring-cloud
111.spring cloud 断路器的作用是什么?
在分布式环境下,特别是微服务结构的分布式系统中, 一个软件系统调用另外一个远程系统是非常普遍的。这种远程调用的被调用方可能是另外一个进程,或者是跨网路的另外一台主机, 这种远程的调用和进程的内部调用最大的区别是,远程调用可能会失败,或者挂起而没有任何回应,直到超时。更坏的情况是, 如果有多个调用者对同一个挂起的服务进行调用,那么就很有可能的是一个服务的超时等待迅速蔓延到整个分布式系统,引起连锁反应, 从而消耗掉整个分布式系统大量资源。最终可能导致系统瘫痪。
断路器(Circuit Breaker)模式就是为了防止在分布式系统中出现这种瀑布似的连锁反应导致的灾难。
一旦某个电器出问题,为了防止灾难,电路的保险丝就会熔断。断路器类似于电路的保险丝, 实现思路非常简单,可以将需要保护的远程服务嗲用封装起来,在内部监听失败次数, 一旦失败次数达到某阀值后,所有后续对该服务的调用,断路器截获后都直接返回错误到调用方,而不会继续调用已经出问题的服务, 从而达到保护调用方的目的, 整个系统也就不会出现因为超时而产生的瀑布式连锁反应。
分享一篇文章供大家参考:http://www.cnblogs.com/chry/p/7278853.html
112.spring cloud 的核心组件有哪些?
Spring Cloud由众多子项目组成,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Consul 等,提供了搭建分布式系统及微服务常用的工具,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性token、全局锁、选主、分布式会话和集群状态等,满足了构建微服务所需的所有解决方案。
- 服务发现——Netflix Eureka
- 客服端负载均衡——Netflix Ribbon
- 断路器——Netflix Hystrix
- 服务网关——Netflix Zuul
- 分布式配置——Spring Cloud Config
分享一篇文章供大家参考:https://blog.csdn.net/springML/article/details/82492643
十二、Hibernate
113.为什么要使用 hibernate?
114.什么是 ORM 框架?
115.hibernate 中如何在控制台查看打印的 sql 语句?
116.hibernate 有几种查询方式?
117.hibernate 实体类可以被定义为 final 吗?
118.在 hibernate 中使用 Integer 和 int 做映射有什么区别?
119.hibernate 是如何工作的?
120.get()和 load()的区别?
121.说一下 hibernate 的缓存机制?
122.hibernate 对象有哪些状态?
123.在 hibernate 中 getCurrentSession 和 openSession 的区别是什么?
124.hibernate 实体类必须要有无参构造函数吗?为什么?
十三、Mybatis
125.mybatis 中 #{}和 ${}的区别是什么?
- 1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id".
- 2. $将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
- 3. #方式能够很大程度防止sql注入。
- 4.$方式无法防止Sql注入。
- 5.$方式一般用于传入数据库对象,例如传入表名.
- 6.一般能用#的就别用$.
- MyBatis排序时使用order by 动态参数时需要注意,用$而不是#
分享一篇文章供大家参考:https://www.cnblogs.com/baizhanshi/p/5778692.html
126.mybatis 有几种分页方式?
- 1、数组分页
- 2、sql分页
- 3、拦截器分页
- 4、RowBounds分页
当然现在也有很多分页插件:比如PageHelper等
分享一篇文章供大家参考:https://www.cnblogs.com/baizhanshi/p/5778692.html
https://blog.csdn.net/chenbaige/article/details/70846902
127.RowBounds 是一次性查询全部结果吗?为什么?
是一次性查询全部结果,只不过会根据参数丢掉一部分
分享一篇文章供大家参考:https://blog.csdn.net/u010077905/article/details/38469653
128.mybatis 逻辑分页和物理分页的区别是什么?
- 1:逻辑分页 虽然看起来实现了分页的功能,但实际上是将查询的所有结果放置在内存中,每次都从内存获取。内存开销比较大,在数据量比较小的情况下效率比物理分页高;在数据量很大的情况下,内存开销过大,容易内存溢出,不建议使用
- 2:物理分页 这种分页方法从底层上就是每次只查询对应条目数量的数据,内存开销比较小,在数据量比较小的情况下效率比逻辑分页还是低,在数据量很大的情况下,建议使用物理分页
129.mybatis 是否支持延迟加载?延迟加载的原理是什么?
在mybatis 中默认没有使用延迟加载 ,但是通过配置 <setting name="lazyLoadingEnabled" value="true"/>实现延迟加载
延迟加载的原理:动态代理:在Hibernate中,被动态代理的延迟对象是one方;many方还是第一个普通的一个对象;
分享几篇文章供大家参考:http://www.cnblogs.com/trisaeyes/archive/2007/01/08/614996.html
https://www.cnblogs.com/llynic/p/6377783.html
130.说一下 mybatis 的一级缓存和二级缓存?
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构用于存储缓存数据。不同的sqlSession之间的缓存数据区域是互相不影响的。也就是他只能作用在同一个sqlSession中,不同的sqlSession中的缓存是互相不能读取的
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。二级缓存的作用范围更大。
分享几篇文章供大家参考:https://blog.csdn.net/weixin_36380516/article/details/73194758
https://zhidao.baidu.com/question/140731349194225845.html
131.mybatis 和 hibernate 的区别有哪些?
- Hibernate 框架
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,建立对象与数据库表的映射。是一个全自动的、完全面向对象的持久层框架。
- Mybatis框架
Mybatis是一个开源对象关系映射框架,原名:ibatis,2010年由谷歌接管以后更名。是一个半自动化的持久层框架。
- 2.1 开发方面
在项目开发过程当中,就速度而言:
hibernate开发中,sql语句已经被封装,直接可以使用,加快系统开发;
Mybatis 属于半自动化,sql需要手工完成,稍微繁琐;
但是,凡事都不是绝对的,如果对于庞大复杂的系统项目来说,发杂语句较多,选择hibernate 就不是一个好方案。
- 2.2 sql优化方面
Hibernate 自动生成sql,有些语句较为繁琐,会多消耗一些性能;
Mybatis 手动编写sql,可以避免不需要的查询,提高系统性能;
- 2.3 对象管理比对
Hibernate 是完整的对象-关系映射的框架,开发工程中,无需过多关注底层实现,只要去管理对象即可;
Mybatis 需要自行管理 映射关系;
- 2.4 缓存方面
<ul><li><strong> 相同点:</strong></li> <li> Hibernate和Mybatis的二级缓存除了采用系统默认的缓存机制外,都可以通过实现你自己的缓存或为其他第三方缓 存方案,创建适配器来完全覆盖缓存行为。</li> <li><strong>不同点:</strong></li> <li><strong>Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存。</strong></li> <li>MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。</li> </ul></li>
比较:
- Hibernate 具有良好的管理机制,用户不需要关注SQL,如果二级缓存出现脏数据,系统会保存,;
- Mybatis 在使用的时候要谨慎,避免缓存CAche 的使用。
Hibernate优势
-
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
-
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
-
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
-
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
Mybatis优势
-
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
-
MyBatis容易掌握,而Hibernate门槛较高。
一句话总结
- Mybatis:小巧、方便、高效、简单、直接、半自动化
- Hibernate:强大、方便、高效、复杂、间接、全自动化
132.mybatis 有哪些执行器(Executor)?
Mybatis有三种基本的Executor执行器: SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
- BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
Mybatis中如何指定使用哪一种Executor执行器?
答:在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
133.mybatis 分页插件的实现原理是什么?
实现原理: 就是在StatementHandler之前进行拦截,对MappedStatement进行一系列的操作(大致就是拼上分页sql)
分享几篇文章供大家参考:https://blog.csdn.net/tuesdayma/article/details/80166361
134.mybatis 如何编写一个自定义插件?
因为本人目前没有写过自定义四插件,所以网上找了一篇文章供大家分享
https://www.jianshu.com/p/96ddaec4aea7
十四、RabbitMQ
135.rabbitmq 的使用场景有哪些?
- 场景1:单发送单接收
- 场景2:单发送多接收场景3:Publish/Subscribe
- 场景3:Publish/Subscribe
- 场景4:Routing (按路线发送接收)
- 场景5:Topics (按topic发送接收)
分享几篇文章供大家参考:https://www.cnblogs.com/luxiaoxun/p/3918054.html
136.rabbitmq 有哪些重要的角色?
- none
- 1、不能访问 management plugin
- management
- 1、用户可以通过AMQP做的任何事外加:
- 2、列出自己可以通过AMQP登入的virtual hosts
- 3、查看自己的virtual hosts中的queues, exchanges 和 bindings
- 4、查看和关闭自己的channels 和 connections
- 5、查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
- policymaker
- 1、management可以做的任何事外加:
- 2、查看、创建和删除自己的virtual hosts所属的policies和parameters
- monitoring
- 1、management可以做的任何事外加:
- 2、列出所有virtual hosts,包括他们不能登录的virtual hosts
- 3、查看其他用户的connections和channels
- 4、查看节点级别的数据如clustering和memory使用情况
- 5、查看真正的关于所有virtual hosts的全局的统计信息
- administrator
- 1、policymaker和monitoring可以做的任何事外加:
- 2、创建和删除virtual hosts
- 3、查看、创建和删除users
- 4、查看创建和删除permissions
- 5、关闭其他用户的connections
分享几篇文章供大家参考:https://www.cnblogs.com/luxiaoxun/p/3918054.html
137.rabbitmq 有哪些重要的组件?
Spring AMQP 是基于 Spring 框架的AMQP消息解决方案,提供模板化的发送和接收消息的抽象层,提供基于消息驱动的 POJO的消息监听等,很大程度上方便了我们进行相关程序的开发。
Message消息是当前模型中操纵的基本单位,它由Producer产生,经过路由转发被Consumer所消费。它是生产者和消费者发送和处理的对象。消息头是由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
Exchange用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Exchange包含4种类型:Direct, Topic, Fanout, Headers。不同的类型,他们如何处理绑定到队列方面的行为会有所不同。
- Direct类型: 允许一个队列通过一个固定的Routing-key(通常是队列的名字)进行绑定。 Direct交换器将消息根据其routing-key属性投递到包含对应key属性的绑定器上。
- Topic类型: 支持消息的Routing-key用*或#的模式,进行绑定。*匹配一个单词,#匹配0个或者多个单词。例如,binding key *.user.# 匹配routing key为 usd.user和eur.user.db,但是不匹配user.hello。
- Fanout类型:它只是将消息广播到所有绑定到它的队列中,而不考虑routing key的值。
- Header类型: 它根据应用程序消息的特定属性进行匹配,这些消息可能在binding key中标记为可选或者必选。
Queue队列,它代表了Message Consumer接收消息的地方,它用来保存消息直到发送给消费者。Queue有以下一些重要的属性。
- 持久性:如果启用,队列将会在消息协商器(Broker)重启前都有效。
- 自动删除:如果启用,那么队列将会在所有的消费者停止使用之后自动删除掉自身。
- 惰性:如果没有声明队列,那么在执行到使用的时候会导致异常,并不会主动声明。
- 排他性:如果启用,队列只能被声明它的消费者使用。
Binding绑定,生产者发送消息到Exchange,接收者从Queue接收消息,而绑定(Binging)是生产者和消费者消息传递的重要连接,它是连接生产者和消费者进行信息交流的关键。
简单来说,RabbitMQ就是一个消息代理机制。它的工作就是接收和转发消息。你可以把它当作是一个邮局:寄信人把信件放入邮箱,邮递员就会把信件投递到你的收件人处。在这个比喻中,RabbitMQ就扮演着邮箱、邮局以及邮递员的角色。其中:
- Exchange: 就是顺丰和韵达。
- routingkey: 就是邮件地址的概念.
- queue: 就是邮箱接收软件,但是可以接收多个地址的邮件,通过bind实现。
- producer: 消息生产者,就是投递消息的程序。
- consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
138.rabbitmq 中 vhost 的作用是什么?
vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的队列、绑定、交换器和权限控制;
vhost通过在各个实例间提供逻辑上分离,允许你为不同应用程序安全保密地运行数据;
RabbitMQ的Vhost主要是用来划分不同业务模块。不同业务模块之间没有信息交互。
Vhost之间相互完全隔离,不同Vhost之间无法共享Exchange和Queue。因此Vhost之间数据无法共享和分享。如果要实现这种功能,需要Vhost之间手动构建对应代码逻辑。
分享几篇文章供大家参考:https://www.cnblogs.com/zhengchunyuan/p/9253725.html
https://www.rabbitmq.com/vhosts.html
139.rabbitmq 的消息是怎么发送的?
RabbitMQ事务和Confirm发送方消息确认
分享几篇文章供大家参考:https://www.cnblogs.com/vipstone/p/9295625.html
140.rabbitmq 怎么保证消息的稳定性?
正常情况下,如果消息经过交换器进入队列就可以完成消息的持久化,但如果消息在没有到达broker之前出现意外,那就造成消息丢失,有没有办法可以解决这个问题?RabbitMQ有两种方式来解决这个问题:
- 通过AMQP提供的事务机制实现;
- 使用发送者确认模式实现;
分享几篇文章供大家参考:https://www.cnblogs.com/vipstone/p/9350075.html
141.rabbitmq 怎么避免消息丢失?
- 消息持久化
- ACK确认机制
- 设置集群镜像模式
- 消息补偿机制
分享几篇文章供大家参考:https://blog.csdn.net/u011665991/article/details/89946185
142.要保证消息持久化成功的条件有哪些?
需要将queue,exchange和Message都持久化。
分享几篇文章供大家参考:https://blog.csdn.net/u011665991/article/details/89946411
未更新完成。。。。
143.rabbitmq 持久化有什么缺点?
144.rabbitmq 有几种广播类型?
145.rabbitmq 怎么实现延迟消息队列?
146.rabbitmq 集群有什么用?
147.rabbitmq 节点的类型有哪些?
148.rabbitmq 集群搭建需要注意哪些问题?
149.rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
150.rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
151.rabbitmq 对集群节点停止顺序有要求吗?
十五、Kafka
152.kafka 可以脱离 zookeeper 单独使用吗?为什么?
153.kafka 有几种数据保留的策略?
154.kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
155.什么情况会导致 kafka 运行变慢?
156.使用 kafka 集群需要注意什么?
十六、Zookeeper
157.zookeeper 是什么?
158.zookeeper 都有哪些功能?
159.zookeeper 有几种部署模式?
160.zookeeper 怎么保证主从节点的状态同步?
161.集群中为什么要有主节点?
162.集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
163.说一下 zookeeper 的通知机制?
十七、MySql
164.数据库的三范式是什么?
165.一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
166.如何获取当前数据库版本?
167.说一下 ACID 是什么?
168.char 和 varchar 的区别是什么?
169.float 和 double 的区别是什么?
170.mysql 的内连接、左连接、右连接有什么区别?
171.mysql 索引是怎么实现的?
172.怎么验证 mysql 的索引是否满足需求?
173.说一下数据库的事务隔离?
174.说一下 mysql 常用的引擎?
175.说一下 mysql 的行锁和表锁?
176.说一下乐观锁和悲观锁?
177.mysql 问题排查都有哪些手段?
178.如何做 mysql 的性能优化?
十八、Redis
179.redis 是什么?都有哪些使用场景?
Redis是一个基于内存的高性能开源的 key—value型 单线程 数据库,支持string、list、set、zset和hash类型数据。
适用场景: 对扩展性要求高的数据
- 数据高并发的读写
- 海量数据的读写
不适场景:
- 需要事务支持(非关系型数据库)
- 基于sql结构化查询储存,关系复杂
180.redis 有哪些功能?
- 全页面缓存
- 顺序排列
- 会话session存储
- 队列
- pub/sub
具体参考文章:https://blog.csdn.net/sinat_34496643/article/details/80077319
181.redis 和 memecache 有什么区别?
- redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多 (3) redis可以持久化其数据
- Memcache与Redis的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型 Memcache对数据类型支持相对简单。 Redis有复杂的数据类型。
3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
182.redis 为什么是单线程的?
redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销
183.什么是缓存穿透?怎么解决?
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决办法:
1.布隆过滤 2. 缓存空对象. 将 null 变成一个值.
具体参考文章:https://blog.csdn.net/u011665991/article/details/89956398
184.redis 支持的数据类型有哪些?
redis支持丰富的数据类型,从最基础的string到复杂的常用到的数据结构都有支持:
- string:最基本的数据类型,二进制安全的字符串,最大512M。
- list:按照添加顺序保持顺序的字符串列表。
- set:无序的字符串集合,不存在重复的元素。
- sorted set:已排序的字符串集合。
- hash:key-value对的一种集合。
- bitmap:更细化的一种操作,以bit为单位。
- hyperloglog:基于概率的数据结构。
这些众多的数据类型,主要是为了支持各种场景的需要,当然每种类型都有不同的时间复杂度。其实这些复杂的数据结构相当于之前在《解读REST》这个系列博客基于网络应用的架构风格中介绍到的远程数据访问(Remote Data Access = RDA)的具体实现,即通过在服务器上执行一组标准的操作命令,在服务端之间得到想要的缩小后的结果集,从而简化客户端的使用,也可以提高网络性能。比如如果没有list这种数据结构,你就只能把list存成一个string,客户端拿到完整的list,操作后再完整的提交给redis,会产生很大的浪费。
185.redis 支持的 java 客户端都有哪些?
Redisson,Jedis,lettuce等等,官方推荐使用Redisson。
186.jedis 和 redisson 有哪些区别?
- Jedis api 在线网址:http://tool.oschina.net/uploads/apidocs/redis/clients/jedis/Jedis.html
- redisson 官网地址:https://redisson.org/
- redisson git项目地址:https://github.com/redisson/redisson
- lettuce 官网地址:https://lettuce.io/
- lettuce git项目地址:https://github.com/lettuce-io/lettuce-core
概念:
Jedis:是Redis的Java实现客户端,提供了比较全面的Redis命令的支持,
Redisson:实现了分布式和可扩展的Java数据结构。
Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。
优点:
Jedis:比较全面的提供了Redis的操作特性
Redisson:促使使用者对Redis的关注分离,提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列
Lettuce:主要在一些分布式缓存框架上使用比较多
可伸缩:
Jedis:使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Redisson:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作
Lettuce:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Lettuce的API是线程安全的,所以可以操作单个Lettuce连接来完成各种操作
结论:
建议使用:Jedis + Redisson
187.怎么保证缓存和数据库数据的一致性?
- 对删除缓存进行重试,数据的一致性要求越高,我越是重试得快。
- 定期全量更新,简单地说,就是我定期把缓存全部清掉,然后再全量加载。
- 给所有的缓存一个失效期。
分享几篇文章供大家参考:https://blog.csdn.net/u011665991/article/details/89954298
188.redis 持久化有几种方式?
- RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
- AOF:AOF 机制对每条写入命令作为日志,以
append-only的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。
补充:
通过 RDB 或 AOF,都可以将 redis 内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云等云服务。
如果 redis 挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动 redis,redis 就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
如果同时使用 RDB 和 AOF 两种持久化机制,那么在 redis 重启的时候,会使用 AOF 来重新构建数据,因为 AOF 中的数据更加完整。
RDB 优缺点
- RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份redis中的数据。
- RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。
- 如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
- RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF 优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据。
- AOF 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
- AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在 rewrite log 的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。
- AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台 rewrite 还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条 flushall 命令给删了,然后再将该 AOF 文件放回去,就可以通过恢复机制,自动恢复所有数据。
- 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性能会大大降低)
- 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志/merge/回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB和AOF到底该如何选择
不要仅仅使用 RDB,因为那样会导致你丢失很多数据
也不要仅仅使用 AOF,因为那样有两个问题,第一,你通过 AOF 做冷备,没有 RDB 做冷备,来的恢复速度更快; 第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug。
redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
分享几篇文章供大家参考:https://blog.csdn.net/yinxiangbing/article/details/48627997
189.redis 怎么实现分布式锁?
官方推荐采用Redlock算法,即使用string类型,加锁的时候给的一个具体的key,然后设置一个随机的值;取消锁的时候用使用lua脚本来先执行获取比较,然后再删除key。具体的命令如下:
SET resource_name my_random_value NX PX 30000
if redis.call(“get”,KEYS[1]) == ARGV[1] then
return redis.call(“del”,KEYS[1])
else
return 0
end
190.redis 分布式锁有什么缺陷?
(一)缓存和数据库双写一致性问题
(二)缓存雪崩问题
(三)缓存击穿问题
(四)缓存的并发竞争问题
分享几篇文章供大家参考:
- https://www.jianshu.com/p/6fba984cd9bd
- https://www.cnblogs.com/linianhui/archive/2017/11/06/what-problem-does-redis-solve.html
- https://blog.csdn.net/hcmony/article/details/80694560
- https://www.cnblogs.com/linianhui/archive/2017/11/06/what-problem-does-redis-solve.html
191.redis 如何做内存优化?
1. 关闭 Redis 的虚拟内存[VM]功能,即 redis.conf 中 vm-enabled = no
2. 设置 redis.conf 中 maxmemory ,用于告知 Redis 当使用了多少物理内存后拒绝继续写入的请求,可防止 Redis 性能降低甚至崩溃
3.可为指定的数据类型设置内存使用规则,从而提高对应数据类型的内存使用效率
- Hash 在 redis.conf 中有以下两个属性,任意一个超出设定值,则会使用 HashMap 存值
- hash-max-zipmap-entires 64 表示当 value 中的 map 数量在 64 个以下时,实际使用 zipmap 存储值
- hash-max-zipmap-value 512 表示当 value 中的 map 每个成员值长度小于 512 字节时,实际使用 zipmap 存储值
- List 在 redis.conf 中也有以下两个属性
- list-max-ziplist-entires 64
- list-max-ziplist-value 512
4. 在 Redis 的源代码中有一行宏定义 REDIS-SHARED-INTEGERS = 10000 ,修改该值可以改变 Redis 存储数值类型的内存开销
192.redis 淘汰策略有哪些?
- noeviction:当内存限制达到,谁也不删除,返回错误。
- allkeys-lru:尝试回收最少使用的键,使得新添加的数据有空间存放。
- volatile-lru:尝试回收最少使用的键,但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkey-random:回收随机的键,使得新添加的数据有空间存放。
- volatile-random:回收随机的键,使得新添加的数据有空间存放,但仅限于过期集合的键。
- volatile-ttl:回收在过期集合的键,并且优先回收存货时间较短的键,使得新添加的数据有空间存放。
193.redis 常见的性能问题有哪些?该如何解决?
- Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
- Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
- Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
十九、JVM
194.说一下 jvm 的主要组成部分?及其作用?
195.说一下 jvm 运行时数据区?
196.说一下堆栈的区别?
197.队列和栈是什么?有什么区别?
198.什么是双亲委派模型?
199.说一下类加载的执行过程?
200.怎么判断对象是否可以被回收?
201.java 中都有哪些引用类型?
202.说一下 jvm 有哪些垃圾回收算法?
203.说一下 jvm 有哪些垃圾回收器?
204.详细介绍一下 CMS 垃圾回收器?
205.新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
206.简述分代垃圾回收器是怎么工作的?
207.说一下 jvm 调优的工具?
208.常用的 jvm 调优的参数都有哪些?
