透过现象看本质——回头再看Nginx
Nginx的进程模型
使用过nginx的朋友都知道nginx的性能很高,而其原因可能少有人知。首先,nginx的架构就奠定了其高性能的基础。那么就先来看看nginx的基础架构吧,如下图所示:(不能完全理清楚所有内容也没关系,因为本小节讲述的主要内容是Nginx的进程模型)
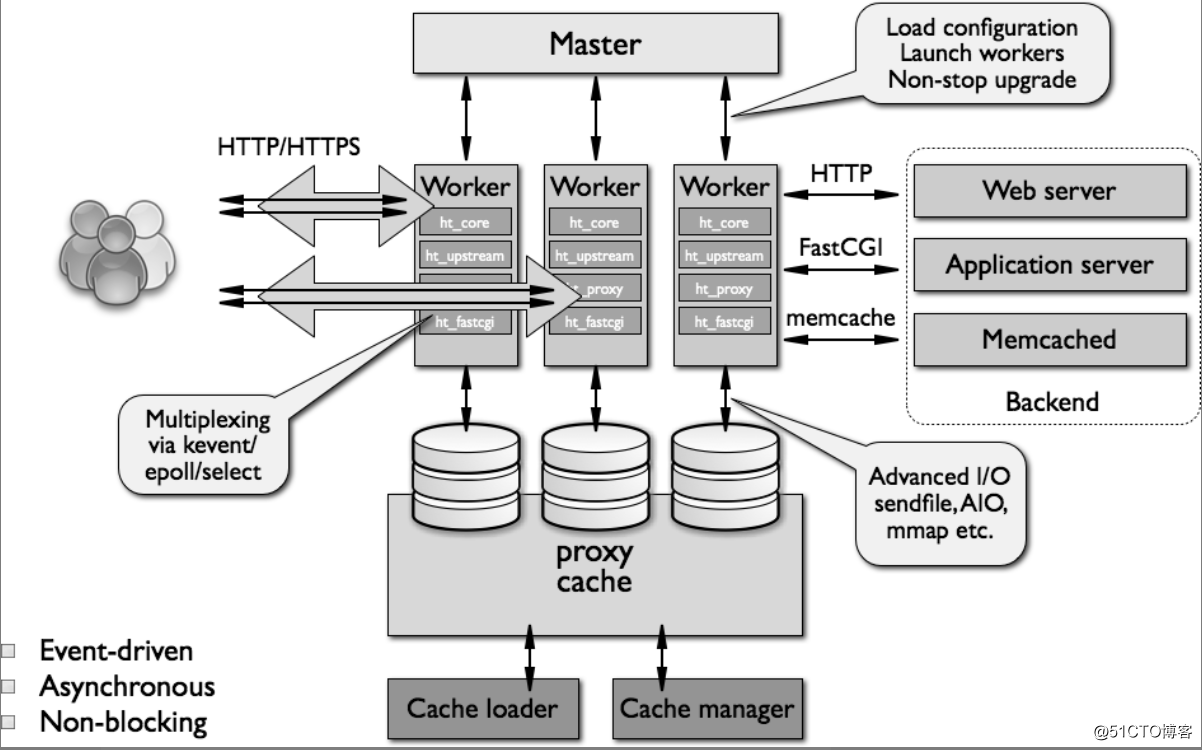
本小节先来说说Nginx基础架构中的进程模型:
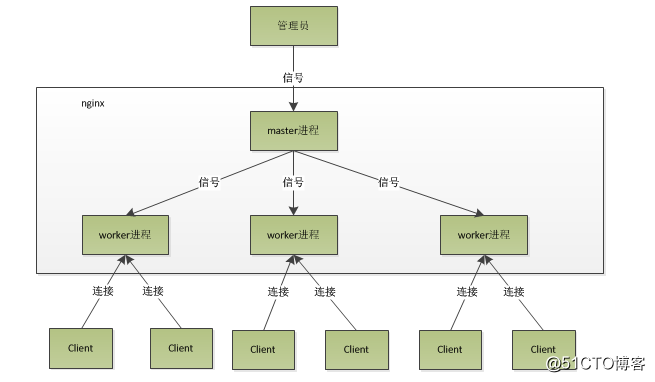
所谓进程模型,即Nginx响应请求或服务时程序运行(机器执行指令集)的方式,一般在nginx服务启动后,在Unix系统中会以daemon的方式在后台运行,后台进程包含一个master进程以及多个worker进程。
而在我们进行调试时,可以手动关闭后台模式以及设置nginx取消master进程,使其以单进程方式运行,但是生产环境中肯定不允许这样上线服务,主流的运行方式还是默认使用多进程。
这里插一下关于进程和程序的区别:
其实这两者完全不是一个概念,程序只是一堆等待执行的代码和部分待处理的数据,只有被加到内存中,由CPU处理执行代码,才可以发挥其作用,从而形成一个真正的“活的”动态的进程。所以二者的典型区别不言而喻,程序未被执行时是静态的,只有运行时才变成动态的进程,并且进程有始有终(进程的“生老病死”)。
言归正传,还是回来说nginx的多进程模式。nginx启动后,会有如上图所示的一个master进程和多个worker进程。
master进程:负责管理worker进程,接收、发送信号,监控worker进程状态;操作控制Nginx只需要通过与master进程通信就可以了。
worker进程:负责处理基本网络事件,每个worker进程都是平等且独立的(记住独立两个字)。一般worker进程数会设置为机器(服务器)的CPU核心数(原因下文会讲到)。

Nginx响应连接的工作原理
我们从nginx启动时的工作流程以及启动后所响应外部的操作来理解nginx处理一个连接的工作原理及过程。
启动时:
Nginx启动时,会先解析配置文件,获取需要监听的ip地址与端口号(涉及网络编程以及TCP/IP理论),然后在master进程中,首先初始化好这个监控的socket,然后fork多个子进程,子进程竞争(例如互斥锁机制)accept新的连接。此时,Nginx以及启动好,等待客户端来连接自己。
fork——属于系统编程内容,原意为叉子,可能老外使用的是叉子,而决定使用这个单词来比喻fork的作用,fork函数的功能就是创建(有时候理解为派生)出多个子进程
启动后:
客户机发起连接请求,通过TCP三次握手与Nginx建立一个连接,此时竞争成功的一个worker进程获取到这个建立好连接的socket,开始创建nginx对连接的封装(其实说白了就是结构体封装)。随之执行读写事件(本文所述的事件理解为网络事件即可)函数、添加读写事件来与客户端进行数据交互。最后,其中一方主动断开连接(四次挥手),到此,一个连接也就寿终正寝了(该worker进程被宣告退休)。
Nginx重启流程
当我们执行命令kill -HUP pid时,master进程是如何响应的呢?
首先,master接收到kill(不要简单理解为杀死,很多人都保持着这样的理解,但是这样不准确,在linux系统中,kill表示的是用于向进程发送信号的,可以使用kill -l查看可以携带的信号)的信号时,首先会重载配置文件,然后启动新的worker进程,并且向旧的worker进程发送信号,提示他们做完当前事件之后就可以光荣退休了。新的worker进程启动后,开始接收新的请求。这种方式就是直接给mater进程发送信号。
而在新的版本中,可以使用其他方式例如:./nginx -s reload就是重启服务,./nginx -s stop就是停止服务,执行./nginx -s reload时会启动一个新的进程(nginx),该进程解析到reload的时候,就控制nginx重载配置文件,向master进程发送信号了,随后就和上面旧版本的方式一样的过程了。
以上就是nginx内部工作(内部究竟干了啥活)了,但是此时考虑一个问题:worker进程如何处理请求的呢?
worker进程工作方式
既然worker进程是由master进程fork出来的,并且每个worker进程都是对等的,那么当一个请求过来时,任何一个worker进程都有可能处理它,这个时候怎么办呢?
为了保证只有一个进程处理该连接请求,所有的worker进程会进行竞争,触发锁机制,一般是互斥锁,抢到锁的进程获得权利来处理这个请求(读事件开始调用accept接受该连接),进行读取、解析、处理请求,将结果(数据信息)返回给客户端,最后断开连接,这个请求完整走完它的人生。因此,一个请求完全是由也仅仅由一个worker进程处理。
Nginx为什么选择多进程模型?
这个问题其实不是特别容易说,没有进程线程的理论基础可能也无法理解原理,这边给出其具备的”独立“特征所带来的优势吧。
”独立“的进程,意味着不需要加锁,节省开销,并且多个worker进程之间互不影响,某一个出现bug后,会有新的worker进程开始工作,从而降低风险,也不会中断其他服务,同时也简化了编程和检查问题。
那么,问题又来了,使用多进程模型,每个worker进程中也只有一个主线程,如何可以处理高并发呢?
且看下节。
Nginx异步非阻塞的处理请求方式(简单说说)
简单理解阻塞与非阻塞
- 阻塞就是线程在执行IO操作获取数据时,这个IO可能会需要一定的时间才能等到数据返回,然后才能接着执行下面的命令。那么,此时,这个线程的等待状态(一般在nginx中称作内核等待,而nginx中最忌讳阻塞的系统调用)我们就把它称为阻塞。没有充分利用起cpu的资源。
- 非阻塞还是这个线程在进行 IO操作时,无需等待数据的返回,可以接着往下执行代码命令,会返回一个结果给你,你可以使用cpu资源做其他的事情。
举个例子:阻塞就好比下课你去食堂吃饭,但去的时候人太多了,你就傻傻地在原地排队等。
非阻塞就好比是你去食堂吃饭,人依旧很多,但是你可以先去上个洗手间,看会儿资讯,不影响你干这些事情。充分利用时间,这个时间就好比是CPU的使用率,非阻塞的存在可以避免浪费CPU资源。
为什么需要异步方式?
上面说的非阻塞,在nginx应用时,虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。所以,才会采取异步方式。
- 同步:同步指的当线程进行IO操作请求数据时,是你主动"关心"数据的返回。
- 异步:当前线程无需主动关心数据是否返回,当数据返回时,会有相关的事件通知你。
举个例子:同步就是你有不懂的问题问同事,他给你开始讲解解决思路或方案,你一直在主动听取他的内容,异步就是同样你问同事问题,他可能说我先考虑考虑,想出来了主动来告诉你。
异步方式+非阻塞处理请求可以避免浪费CPU资源,同时提高响应速度,工作效率。其实本质上就是说worker进程,在循环执行异步请求(事件),从而处理高并发。
因此,设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的资源浪费。
结尾给出Nginx源码目录介绍吧。
Nginx代码的目录结构
解压nginx软件,进入其目录就可以看到它的目录结构如下:
[root@localhost nginx-1.16.1]# tree -d
.
├── auto #自动编译安装相关目录
│ ├── cc #针对各种编译器进行相应的编译配置目录,包括gcc、ccc等
│ ├── lib #程序依赖的各种库,包括openssl、pcre 、perl等
│ │ ├── geoip
│ │ ├── google-perftools
│ │ ├── libatomic
│ │ ├── libgd
│ │ ├── libxslt
│ │ ├── openssl
│ │ ├── pcre
│ │ ├── perl
│ │ └── zlib
│ ├── os #针对不同的操作系统所做的编译配置目录
│ └── types #与数据类型相关的一些辅助脚本
├── conf #存放默认配置文件,在make install后,会拷贝到安装目录中去
├── contrib #存放一些实用工具,如geo配置生成工具(geo2nginx.pl
│ ├── unicode2nginx #
│ └── vim #
│ ├── ftdetect #
│ ├── ftplugin #
│ ├── indent #
│ └── syntax #
├── html #存放默认的网页文件,在make install后,会拷贝到安装目录中去
├── man #手册
└── src #存放nginx的源代码
├── core #nginx的核心源代码,包括常用数据结构的定义,以及nginx初始化运行的核心代码如main函数
├── event #对系统事件处理机制的封装,以及定时器的实现相关代码
│ └── modules #不同事件处理方式的模块化,如select、poll、epoll、kqueue等
├── http #nginx作为http服务器相关的代码
│ ├── modules #包含http的各种功能模块
│ │ └── perl #
│ └── v2 #
├── mail #nginx作为邮件代理服务器相关的代码
├── misc #一些辅助代码,测试c++头的兼容性,以及对google_perftools的支持
├── os #主要是对各种不同体系统结构所提供的系统函数的封装,对外提供统一的系统调用接口
│ └── unix #
└── stream #实现四层协议的转发、代理或者负载均衡等第三方模块
对于使用者而言最关键的是conf目录,html目录,对于开发者而言可能需要看其源码文件:目录为src,这就涉及到nginx的核心部分,包括模块、模块对应的功能等。
参考链接:tengine.taobao.org