题记:想了解Kylin、首先需要了解一下什么是OLAP、OLTP
一、OLAP:( OnLine Analytical Processing )
一般查询延迟在秒级或者毫秒级,可以实现交互式查询、OLAP的查询一般需要Scan大量数据,大多时候只访问部分列,聚合的需求(Sum、Count、Max、Min、排序、减等)多于明细的需求、查询原始明细数据。
OLAP应用:
在年底或者发布会上的大数据分析和统计应用,如:豆瓣读书报告,网易云音乐听歌报告,蚂蚁金服的支付账单等等。OLAP最重要的应用BI分析、类型TOP5 或者TOP10 排行榜、或者统计标签的人物画像哪类人最多等等,热点问题排行榜并不是。
OLAP优点:
专门用来做决策支持
历史的、总结的、统一的数据,进行比较或者归纳。
侧重与查询
查询吞吐量和相应时间是关键性能指标
二、OLTP:(Online Transaction Processing)
一般只会访问少量的记录,且大多时候都会利用索引。
OLTP应用:
在线的面向终端用户直接使用的 Web 应用:金融,博客,评论,电商等系统的查询都是 OLTP 查询,比如最常见的基于主键的 CRUD 操作。
OLTP优点:
专门用来做日常的,基本的操作
任务由短的,原子的,隔离的事务组成
处理的数据量在 G 级别
重视一致性和可恢复性
事务的吞吐量是关键性能指标
最小化并发冲突
总结:
OLTP 需要解决数据的增、删、改、查的问题,OLAP 需要解决数据聚合的问题。
扩展:
OLAP实现方式:根据存储数据的方式不同可以分为 ROLAP、MOLAP。
ROLAP:
ROLAP 主要通过数据引擎强大的计算能力,瞬间聚合数据得到 OLAP 结果。
MOLAP:
MOLAP 则是提前计算聚合好数据模型,查询的时候只需要返回已经聚合好的数据结果。
三、Kylin理论
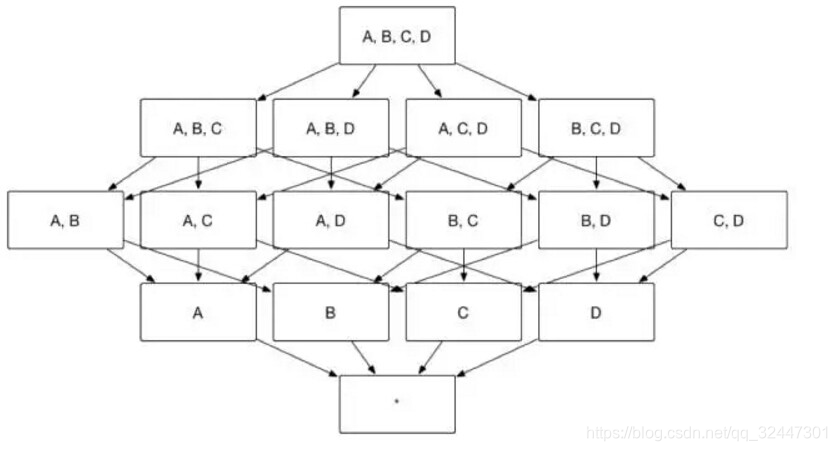
核心思想:空间换时间
四、Kylin 架构
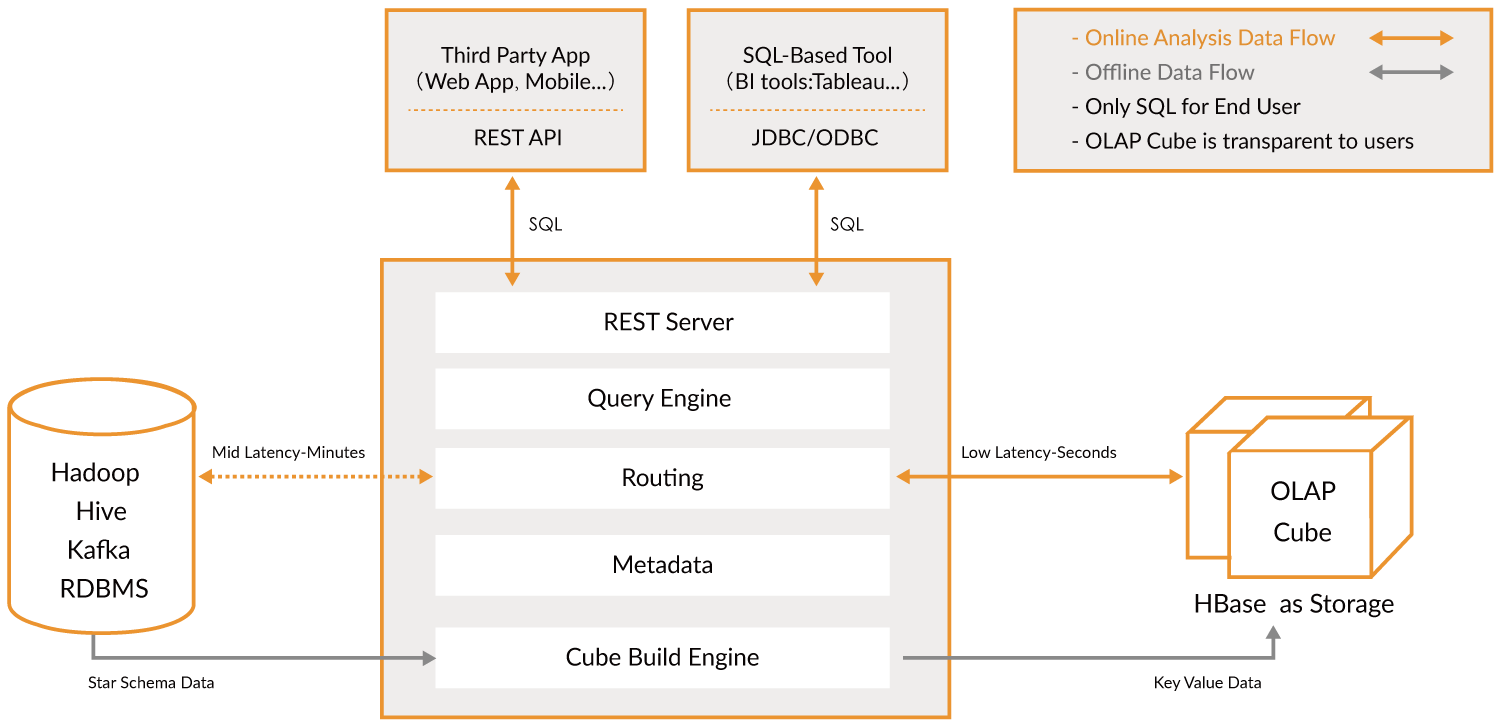
Kylin 自身的组件只有两个:**JobServer 和 QueryServer **。 Kylin 的 JobServer 主要负责将数据源(Hive,Kafka)的数据通过计算引擎(MapReduce,Spark)生成 Cube 存储到存储引擎(HBase)中。
QueryServer 主要负责 SQL 的解析,逻辑计划的生成和优化,向 HBase 的多个 Region 发起请求,并对多个 Region 的结果进行汇总,生成最终的结果集。
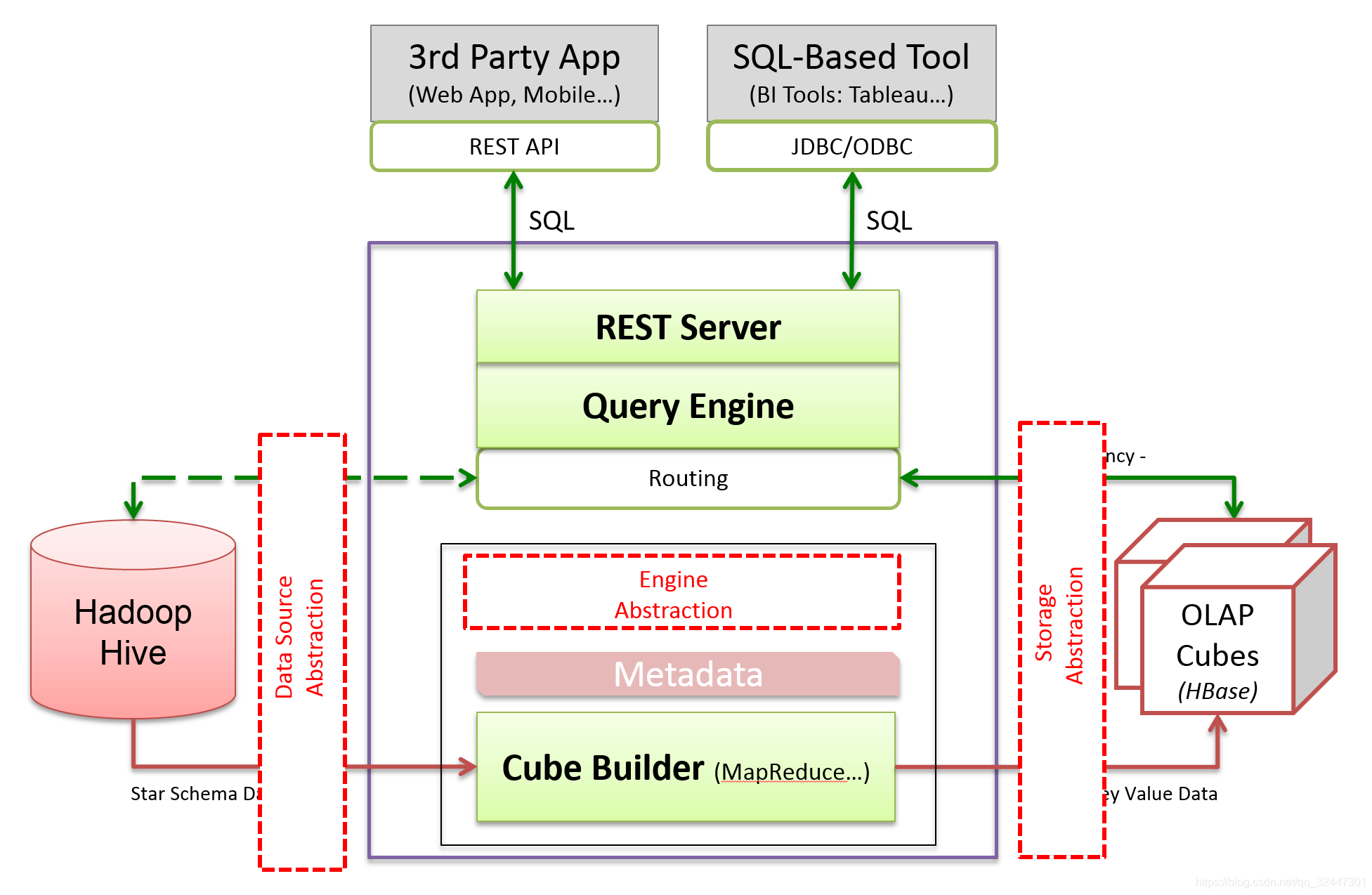
在架构设计上,Kylin 的数据源,构建 Cube 的计算引擎,存储引擎都是可插拔的。Kylin 的核心就是这套可插拔架构,Cube 数据模型和 Cuboid 的算法。
五、Kylin 数据模型
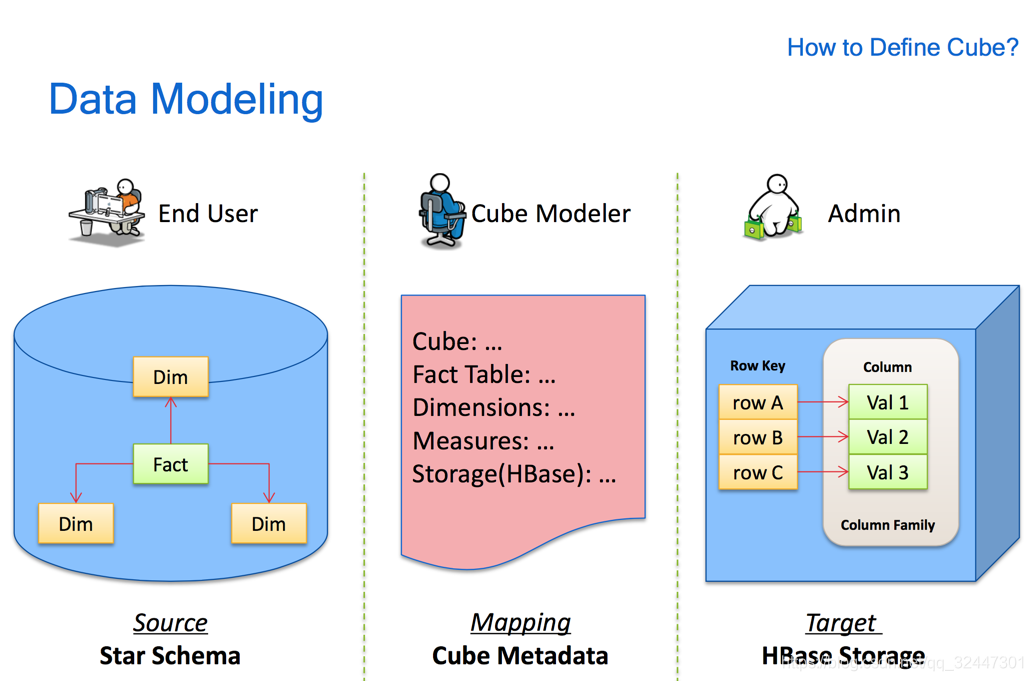
Kylin 将表中的列分为维度列和指标列。在数据导入和查询时相同维度列中的指标会按照对应的聚合函数 (Sum, Count, Min, Max, 精确去重,近似去重,百分位数,TOPN) 进行聚合。
六、插件架构
参考:http://kylin.apache.org/cn/blog/
参考: RangeYan
