记一次从kindle云端阅读器爬取书籍
逛推的时候无意发现有出版社免费公布了一部分书的kindle版,想着下载下来,却发现无法下载,如下图。
然后就打算试试爬虫,kindle云端阅读器显示文档的部分是直接嵌在iframe中的,查看源代码后试图直接访问:


说实在的,我根本没有学过前端,HTML、JS都是之前玩爬虫的时候稍稍了解了一下,不知道如何直接获取这样的情况。以下内容均基于现用现查,谬误之处在所难免,还望指正。
方法一:selenium
整个阅读器在翻页过程中网址是不变的,没有办法使用requests库(或者说我不会),一个直接的想法就是通过selenium调用无头浏览器,模拟访问。
这个库的详细介绍参见https://cuiqingcai.com/2599.html
简单来说,它可以模拟浏览器对网页的访问,并进行诸如“点击”,“截屏”之类的操作,所以我们完全可以使用它进入阅读器,不断模拟点击翻页,再将指定区域截图保存。
kindle云端阅读器长这样:
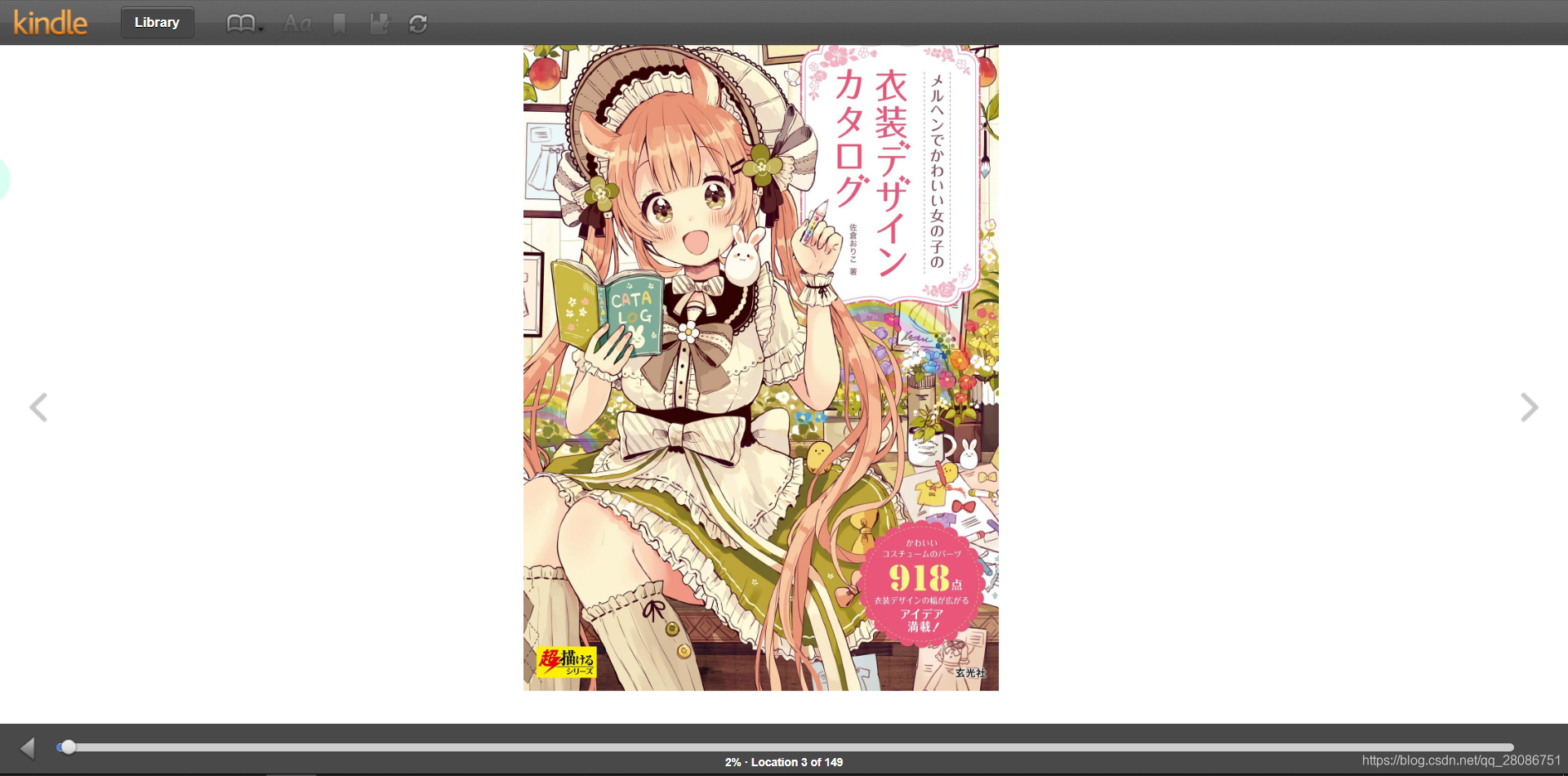
只要定位到右侧的那个箭头,就可以进行点击。
尝试访问阅读器
我们使用chromedriver
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
#驱动路径 谷歌的驱动存放路径
path = r'E://chromeDriver/chromedriver.exe'
# 进入浏览器设置
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(executable_path=path,chrome_options=options)
url ='https://www.baidu.com/'
browser.get(url)
browser.save_screenshot('0.png')
运行之后会自动打开一个chrome窗口,在你的代码所在目录中也会多出一个截图,可以看到确实成功截图。
但是换成阅读器的地址,https://read.amazon.co.jp/,会怎么样?
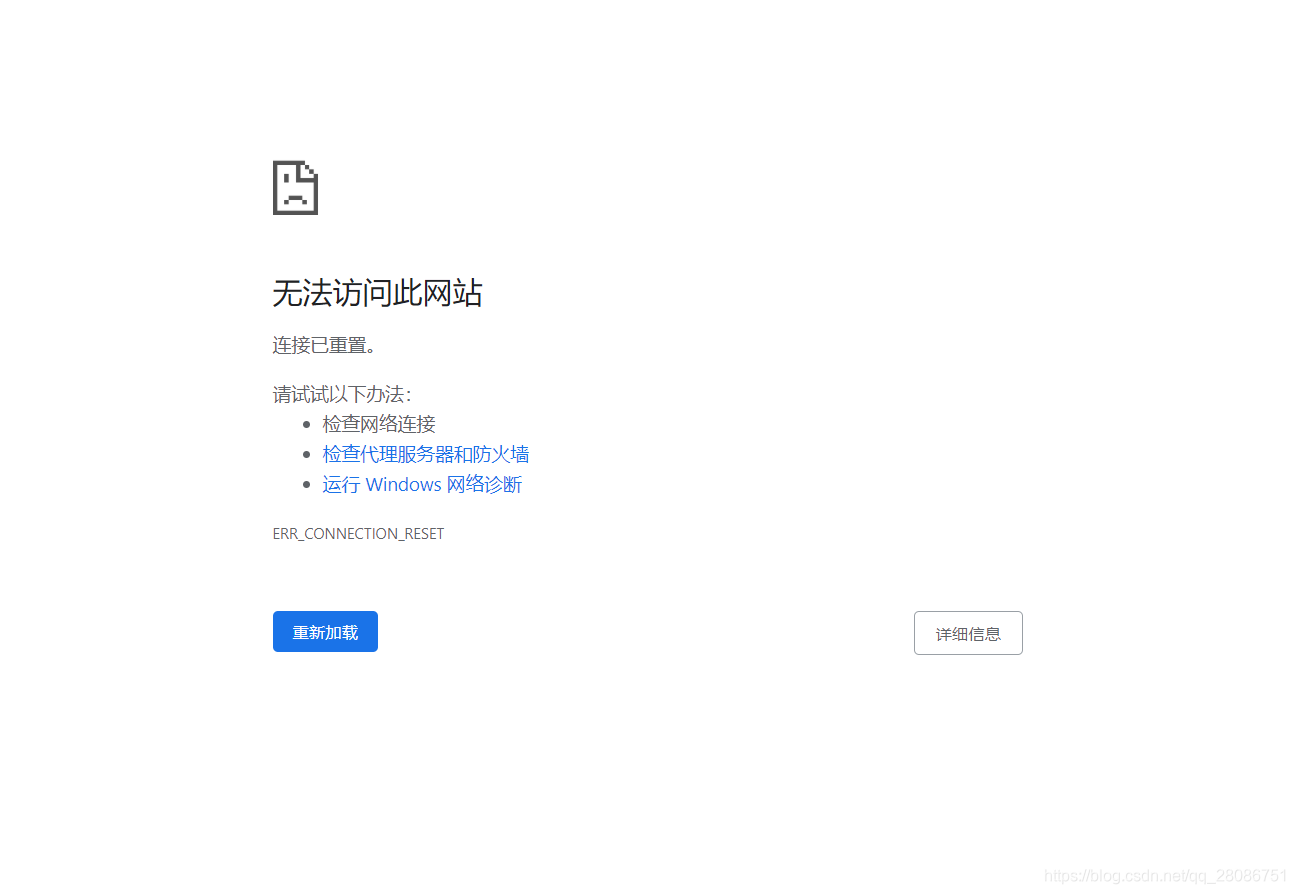
原因很简单,这是日版网站,而我们的IP是大陆的。我一直用的是chrome的一个插件,但是selenium默认不使用用户配置,我们需要稍微修改一下代码:
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
#驱动路径 谷歌的驱动存放路径
path = r'E://chromeDriver/chromedriver.exe'
options = webdriver.ChromeOptions()
#改成你的chrome目录
options.add_argument("--user-data-dir="+r"C:\Users\mi\AppData\Local\Google\Chrome\User Data")
browser = webdriver.Chrome(executable_path=path,chrome_options=options)
url ='https://read.amazon.co.jp/'
browser.get(url)
time.sleep(20)#休眠20s以等待网页加载
browser.save_screenshot('0.png')
browser.quit()
如果你正在使用chrome的话,运行之前先关闭它。

成功访问。
定位
接下来就是找到右箭头的位置。直接查看网页源代码只能看到一个iframe,我们可以按F12审查元素。
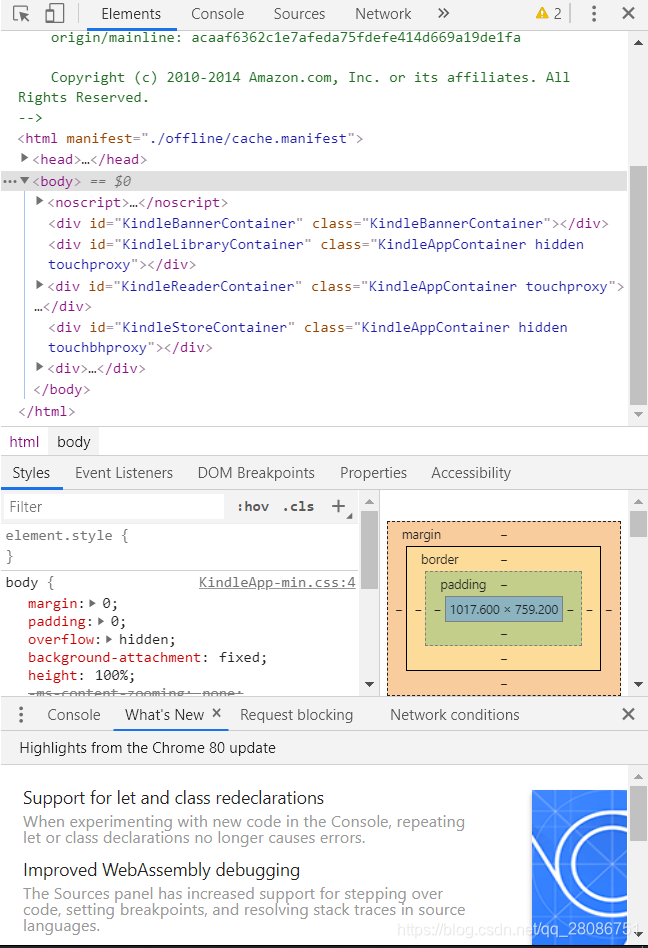
直接Ctrl+F,查找next
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
#驱动路径 谷歌的驱动存放路径
path = r'E://chromeDriver/chromedriver.exe'
options = webdriver.ChromeOptions()
#改成你的chrome目录
options.add_argument("--user-data-dir="+r"C:\Users\mi\AppData\Local\Google\Chrome\User Data")
browser = webdriver.Chrome(executable_path=path,chrome_options=options)
url ='https://read.amazon.co.jp/'
browser.get(url)
time.sleep(20)#休眠20s以等待网页加载
browser.save_screenshot('0.png')
fr=browser.find_element_by_id('KindleReaderIFrame')
browser.switch_to.frame(fr)
x=browser.find_elements_by_class_name('kindleReader_arrowBtn')[1]
x.click()
browser.quit()
iframe中的内容不能直接定位,browser.switch_to.frame(fr)可以切换至该iframe内。接下来按照之前审查元素中找到的类名进行查找。
为什么要加下标?
因为左箭头和右箭头类名相同,find_elements_by_class_name会返回这两个元素。
运行一下试试。

成功。
因为梯子速度较慢,点击下一页时要暂停一会儿等待网页加载完成,用sleep就可以了。再加上循环,最终代码如下:
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
path = r'E://chromeDriver/chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_argument("--user-data-dir="+r"C:\Users\mi\AppData\Local\Google\Chrome\User Data")
browser = webdriver.Chrome(executable_path=path,chrome_options=options)
url ='https://read.amazon.co.jp/'
browser.get(url)
time.sleep(15)
x=browser.find_element_by_id('KindleReaderIFrame')
print(x)
browser.switch_to.frame(x)
browser.save_screenshot('book/0.png')
error=[]
cur=0
for i in range(10):
try:
browser.save_screenshot(f'book/{cur+1}.png')
cur+=1
ele = browser.find_element_by_id('kindleReader_content')
ele.screenshot(f'book/c{cur+1}.png')
x=browser.find_elements_by_class_name('kindleReader_arrowBtn')[1]
x.click()
time.sleep(5)
except:
print(i)
error.append(i)
print(error)
browser.quit()
10次循环的结果如下:
重复的原因是网页并没有加载完成就已经再次截图,可以适当延长截图后的休眠时间。
虽然基本可以保存下来,但是通过截图效果太差,太模糊,之后我想到可以直接保存页面的图片。在搜索的过程中,我发现完全可以通过浏览器自带的console完成图片的下载。
方法二:console+js
按F12调出chrome的console:
在console中可以使用JS直接操作网页,当然包括点击下一页和保存图片。
和方法一相同,首先要在网页中找到右箭头所在的元素,才可以点击,JS代码比python要简单许多:
var c=document.getElementById("KindleReaderIFrame")
var iwindow = c.contentWindow;
var s=iwindow.document.getElementsByClassName("kindleReader_arrowBtn")
window.curr=0
curr用来给图片标号,是一个全局变量。
先用iwindow做一个中间量,提取出iframe中的内容再进行查找。
输出一下s:

s的长度为2,原因同上,有两个箭头,我们只需要第二个。
直接调用click()方法即可实现翻页:
s[1].click()
经过审查元素我们可以发现,在之前提到的那个iframe中还嵌套了多个子iframe:
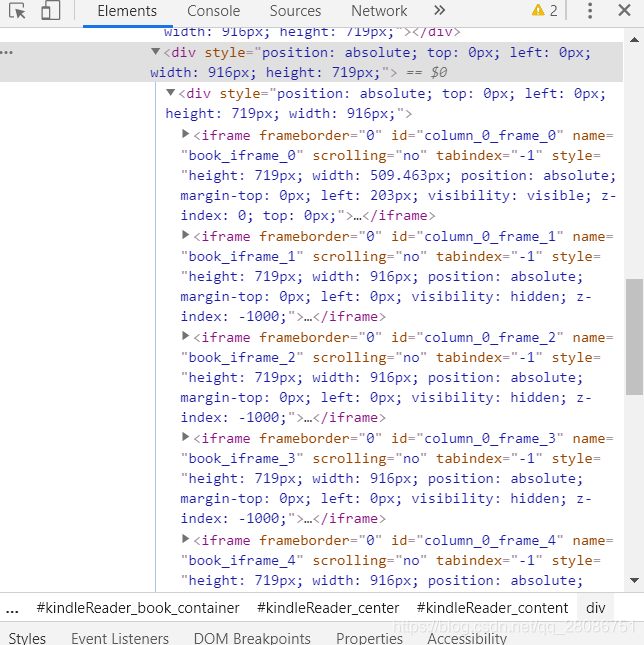
每一个iframe中都包含一张图片,我没有发现第几张才是当前页面,索性全部下载。
首先编(搜)写(索)一个下载图片的函数:
function download(src) {
var $a = document.createElement('a');
$a.setAttribute("href", src);
var m=window.curr.toString();
window.curr++;
$a.setAttribute("download", m+".png");
var evObj = document.createEvent('MouseEvents');
evObj.initMouseEvent( 'click', true, true, window, 0, 0, 0, 0, 0, false, false, true, false, 0, null);
$a.dispatchEvent(evObj);
};
下载一张图片试试函数能不能用。
//fs存储上面提到的多个iframe
fs=c.contentWindow.document.getElementsByTagName('iframe')
cur=fs[0];
//查找第一个iframe中的img标签,返回是一个集合,取第一个
var img=cur.contentWindow.document.getElementsByTagName('img')[0]
download(img.getAttribute('src'))
很好,下载一张图片成功,方便起见,把下载一个页面上的所有图片封装一下:
function downloadOne() {
fs=c.contentWindow.document.getElementsByTagName('iframe')
for(let x=0;x<fs.length;x++){
cur=fs[x];
var img=cur.contentWindow.document.getElementsByTagName('img')[0]
download(img.getAttribute('src'))
}
s[1].click()
};
基本没什么改动,仅仅加了层循环,下载完后点击下一页即可。
最后循环遍历每一页,下面以下载5页为例:
for(let i=1;i<=5;i++){
(function(i){setTimeout(function(){downloadOne()},5000*i);})(i);
}
JS的setTimeout就相当于sleep,第一个参数是休眠后执行的操作,要以函数形式给出,第二个参数是休眠的毫秒数。
但是要注意JS是单线程,但是浏览器是多线程,如果将休眠的时间设定为相同,比如5000毫秒,那么5秒后浏览器会连续下载5次,而不是休眠5秒下载一次。要实现逐个唤醒,可以将休眠时间依次延长,5000,5000*2,……具体可以自行尝试。
后期处理
第二种方法下载图片之后有大量重复,我个人是手动去了一下重。图片格式看起来不太方便,可以将它们组合成PDF文件。微软自带图片转PDF工具(可能是OFFICE的?)。全选所有图片,在第一张上面右键(否则顺序会乱),选择打印,打印机如图选择:
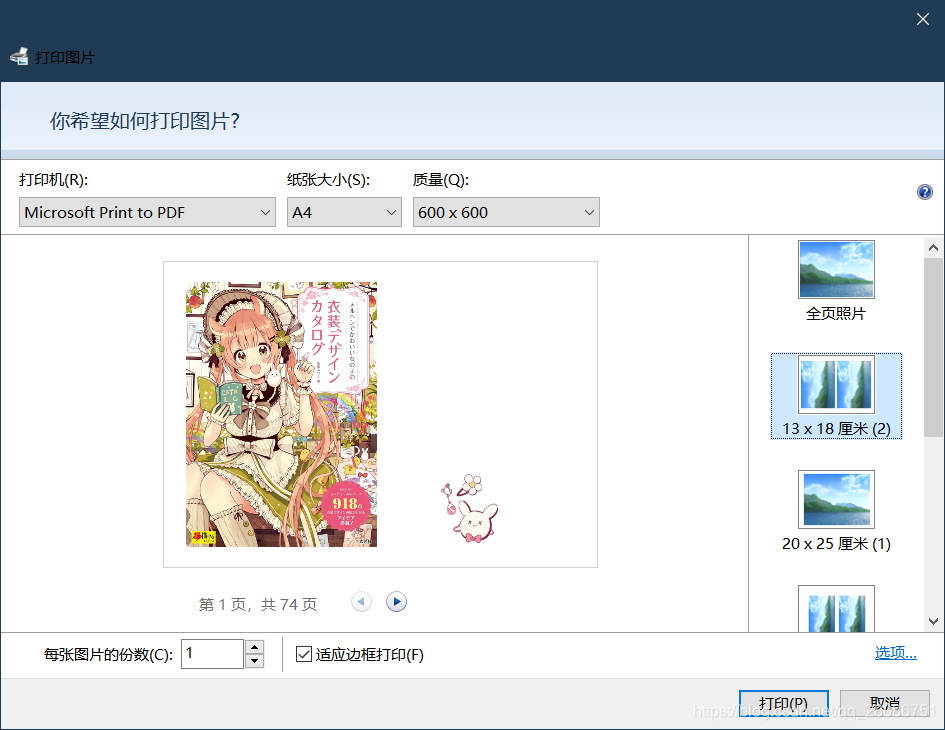
点击打印即可输出PDF文件。
