1.TCP的流量控制机制
>为什么要实现流量控制?
因为当发送方向接收方传送数据包速度过快时,由于接收方来不及接收就会导致数据包的丢失。
因此就需要流量控制(Flow Control):让发送方发送速率不要太快,要让接收方来得及接受。
>流量控制举例
A向B发送数据

①TCP为面向连接,因此先建立会话,B向A发送TCP数据,此时Ack=0(确认序号为0),rwnd=300(告诉发送方,接受缓存空间大小为300字节)。
②A会根据B的接受缓存空间(窗口),来设置自己的发送窗口大小(也为300字节)。
③A会根据发送窗口中的数据向B发送若干个数据包。
④假使A在向B发送数据的过程中,B已接收到第1至200的字节数据,但第201至300字节的数据丢失,此时B会向A发送一个确认接收,
发送TCP数据中Ack=201,rwnd=300(就会让A发送第201个数据,接收窗口大小不变)
⑤此时A会将滑动窗口向右移动200(Ack-1)位,B的接收窗口也向右移动200位。
⑥丢失数据的处理:当发送窗口中所有新的数据都发送完毕后,再重新传丢失的数据(此时已经不能在发送新的数据)
⑦然后B发送TCP数据,此时确认序号Ack=501,并且可以调整窗口rwnd=100
⑧此时A会根据B发送的数据,调整自己的发送窗口为100字节
⑨当B接收数据完毕之后,向A发送TCP数据,将接收窗口设置为rwnd=0,就代表不允许A再发送数据。
⑩接着B会将接收缓存中的数据存到其他地方
假如说当B不在让A发送之后,要恢复发送,B就可以再次向A发送确认号Ack和发送窗口rwnd。如果该发送的TCP数据丢失,A并不是一直等待无动于衷,而是它也会向B发送数据确认窗口大小。
2.TCP拥塞控制
>为什么会发生拥塞以及拥塞控制和流量控制的区别?
TCP的流量控制指的是两个计算机之间相互传送数据,由于发送方发送数据快而导致接收方来不及接收,这是两个计算机之间,
而TCP拥塞控制主要是因为网段中若干个计算机发送数据,导致路由器方数据“堵死”,然后计算机仍然不断发送数据就会会导致数据的大量丢失,因此应该时该网段中的所有计算机在发送数据时,控制自己的发送量来避免拥塞。
用正经话来讲:
拥塞控制是一个全局的过程,涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
流量控制往往指在给定的发送端和接收端之间的点对点通信量的控制,它所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
>出现资源拥塞的条件:对资源需求的总和 > 可用资源 (当信道上传送的数据包总量大于带宽承受的大小时就会发生拥塞)
>拥塞控制所起的作用:
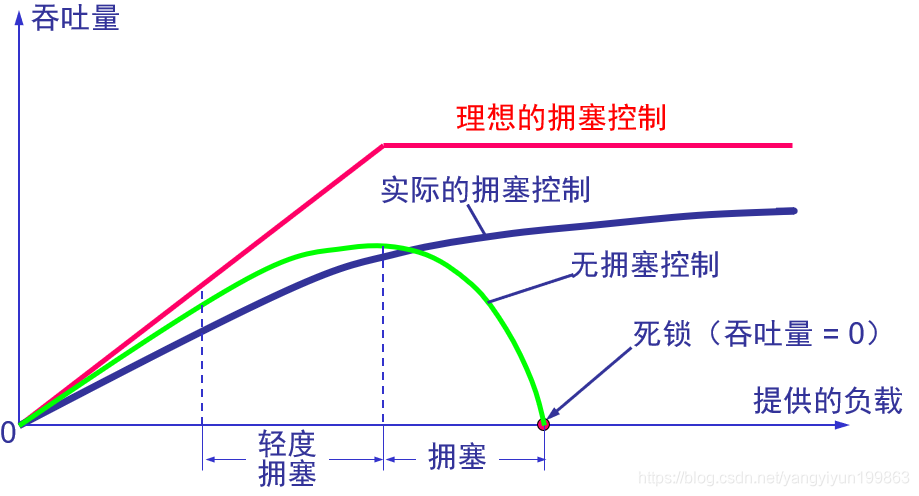
理想的拥塞控制:在信道上所有计算机发送多少数据,路由器都能处理多少发送数据,当计算机发送的数据超过信道承受数据量时,将会把发送的数据包“扔掉”。随着发送的数据包越来越多,路由器仍然保持一个处理数据的量。但实际上是不可能的
无拥塞控制:由于路由器中也是有操作系统,CPU等,刚开始随着发送数据增多,会导致丢失小部分数据,但随着计算机向路由器发送的数据越来越多,路由器实际上是处理不过来的,反而处理数据效率更低,因此就会随着发送数据量越多,导致路由器处理效率越低,甚至会瘫痪。
实际的拥塞控制:所有TCP会有拥塞机制,能够避免出现吞吐量为0的情况,出现死锁的情况。
>发送方维持拥塞窗口cwnd(congestion window)

拥塞窗口就相当于发送窗口,一开始先将拥塞窗口cwnd设置为1,此时发送方先发送一个报文给接收方,然后接收方发送确认之后,发送方会将堵塞窗口cwnd设置为2,再次发送两个报文给接收方,当再次收到确认时,就会设置cwnd=4,发送四个报文给接收方,就这样每当收到接收方的确认数据,就会选择性将堵塞窗口cwnd的值不断增加。
>慢开始和拥塞避免算法的实现举例
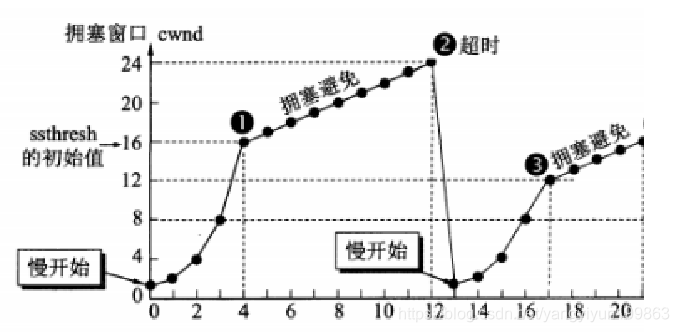
①发送方会将拥塞窗口设置为cwnd=1,此时向B发送一个报文。当发送方接收到确认数据后,将设置cwnd=2,向B发送两个报文,此时是呈指数型增长。
②但并不会一直呈指数型增长,它会设置一个慢开始门限(再此设置ssthresh的初始值为16),也就是为了避免拥塞,发送报文增长数量变缓,当达到慢开始门限时,就会每传输一次,将cwnd增加1,此时呈线性增长。
③当出现报文丢失时,首先会重新设置一个慢开始门限(将原慢开始门限除以2),并且从cwnd=1开始发送报文,然后和①一样。
④当达到慢开始门限(ssthresh=8)时,减缓发送报文增长,此时呈线性增长,cwnd增加1.
也就是说,慢开始是指从cwnd=1开始不断增加发送报文数量,并且是在慢开始门限之前。当达到慢开始门限后,让cwnd的增长成线性,使网络比较不容易出现拥塞,但不可能完全避免,这就是拥塞避免。
>快重传和快速恢复
(1)快重传举例
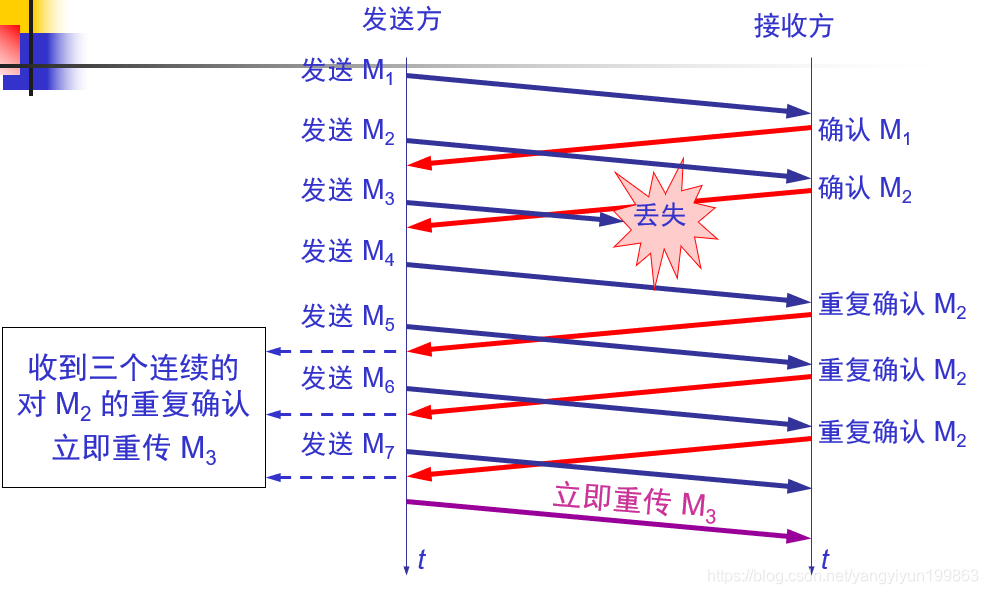
当发送方依次发送七个报文时,当接收方接到M1,M2,时,并且直接接到了M4,没有接到M3时,此时接收方知道M3报文丢失,它不会像之前那样等到M7接收完毕之后再重新确认M3,而是立即发送确认数据M1,M2,当接收到M4后,重复确认M2;接到M5之后,再次重复确认M2;接收到M6时,第三次重复确认M2;因为快重传中规定,当一连三次接收到重复确认后,就会立即进行重传(即“快重传”),这样就不会导致超时,让发送方误以为网络堵塞,就会避免重新慢开始的情况。
(2)之前当接收方发现中间某个数据包丢失时,会累积等到之后的数据包接受完之后,再发送该数据包丢失的确认信息。但快重传指的就是,当接收方发现中间某个数据包丢失时,就不再累计等待,而是直接告诉发送方该数据丢失。
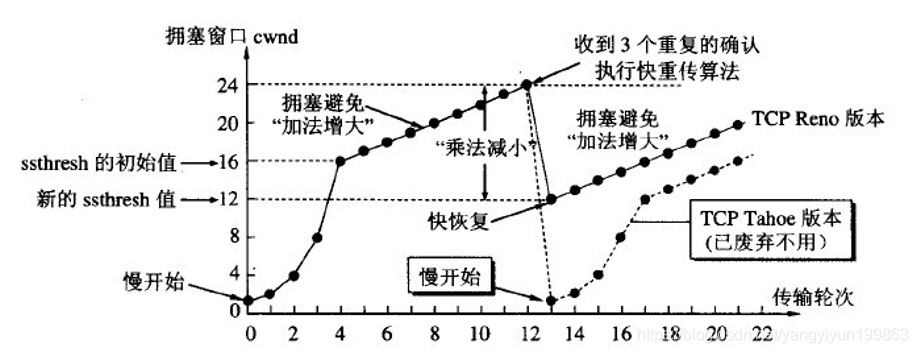
①当收到三个重复的确认时,执行快重传算法,首先将慢开始门限设置为原来慢开始门限的一半,但此时并不是和之前的慢开始一样,从cwnd=1开始,而是直接从慢开始门限cwnd=12开始,直接进入拥塞避免(线性增长)。
②发送方的发送窗口的上限值应当取为接收方窗口和拥塞窗口这两个变量中较小的一个,即发送窗口的上限值=Min[rwnd,cwnd]
快恢复是和慢开始相对来说的快,因为不会再和慢开始一样从cwnd=1开始,而是直接从慢开始门限开始。
3.TCP的传输连接管理
>TCP的连接建立:用三次握手建立TCP连接
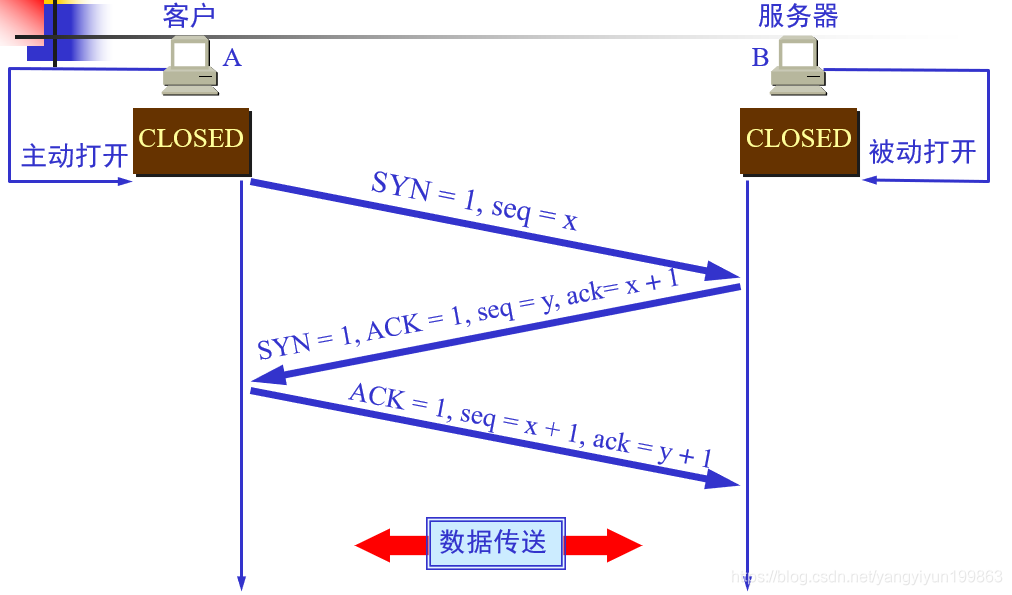
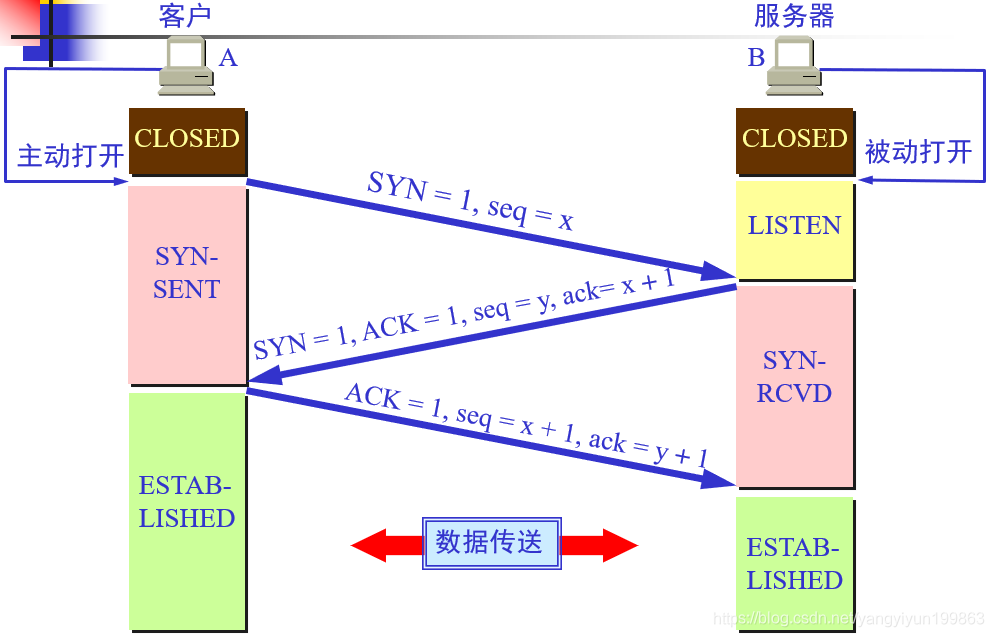
>为什么需要三次握手?
因为可能出现一种情况:当A向B发送请求报文时,报文可能会从走一个很远的路由器进行传输,当客户机发现一段时间后并没有得到回应,则选择再一次发送请求报文,此时可能会很快得到服务器发送的确认连接报文。但过了一段时间,第一次发送的请求报文到了服务器时,服务器就会再次创建一个连接,发送到A,但A之前已经和B建立了连接,因此就不会再理第二次从B来的连接。当B一直接收不到从A发来的请求数据,B的这个连接就会一直等待,这样就造成了B的资源浪费。
所以为了避免资源浪费甚至服务器瘫痪,就出现了三次握手,当客户A第二次发送请求时,服务器B就知道连接建立成功了,如果长时间没有等到A的第二次发送数据就会释放连接。(前两次为同步信息)
>TCP的连接释放
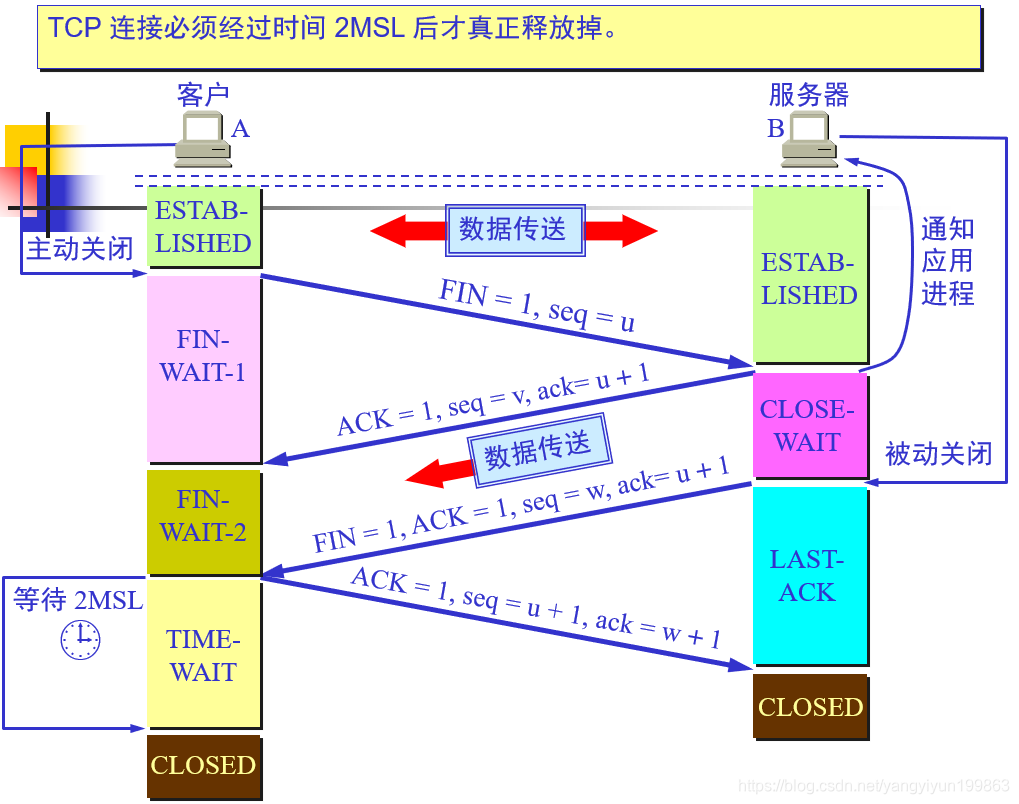
要等待2MSL时间后才能真正释放的原因是,当客户A在最后一次确认之后,如果这个确认的数据包丢失了,服务器B就会再一次发送一个确认报文到客户A,如果A一发送完确认报文就释放连接,那就会再次导致资源浪费。
