如果你准备研究机器学习的东西,或者构造机器学习应用程序,最好的实践方法
不是建立一个非常复杂的系统,拥有多么复杂的变量;而是构建一个简单的算法,这样你可
以很快地实现它。
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算
法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。
类偏斜情况表现为我们的训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。
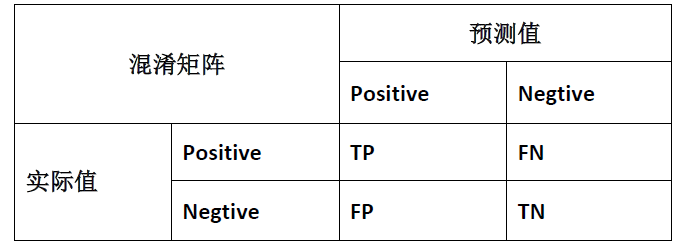
查准率(Precision)和查全率(Recall)
我们将算法预测的结果分成四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为假
3. 错误肯定(False Positive,FP):预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为真
则:查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿
瘤的病人的百分比,越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的
病人的百分比,越高越好。