一、论文
- 研究领域: 点云配准
- 论文:APR: Online Distant Point Cloud Registration through Aggregated Point Cloud Reconstruction
-
IEEE Transactions on Pattern Analysis and Machine Intelligence
-
Submitted on 4 May 2023
- 论文链接
二、论文简述


三、论文详述
APR:通过聚合点云重构实现在线远程点云配准
- Abstract
对于许多驾驶安全应用来说,精确配准在远处移动车辆上生成的LiDAR点云是非常重要的。然而,这样的点云在同一对象上具有极其不同的点密度和传感器视角,使得在这样的点云上的配准非常困难。在本文中,我们提出了一种新的特征提取框架,称为APR,在线远点云注册。具体地,APR利用自动编码器设计,其中自动编码器用几个帧来重建更密集的聚合点云,而不是原始的单个输入点云。我们的设计迫使编码器提取功能,丰富的本地几何信息的基础上,一个单一的输入点云。然后将这些特征用于在线远距离点云配准。我们对KITTI和nuScenes数据集上的最先进(SOTA)特征提取器进行了广泛的实验。结果表明,APR比所有其他提取器表现更好,在LoKITTI和LoNuScenes上,SOTA提取器的平均注册召回率分别提高了7.1%和4.6%。代码可在https://github.com/liuQuan98/APR上获得。
- Introduction
由于LiDAR传感器具有精确和准确的360°视野,它们被安装在新车型上,用于障碍物检测和规避,以安全导航。通过宽带无线通信在相邻车辆之间共享和对齐室外点云是非常有趣的,这可以极大地扩展视野并提高不同对象上的点密度。因为车辆可能是远距离的(例如20至50米),对应的点云在点密度和关于场景中相同对象的视点方面是相当不同的。例如,图1(a)示出了从两个精确对齐的点云中提取的关于目标车辆的点,这两个点云分别从相距仅20米的两个车辆获得。可以看出,它们对目标具有相当不同的观点(即,蓝色和橙子点分别从侧前方和后方透视图获得)。尽管远距离点云存在这种差异,但如果它们能够很好地对齐,它肯定会增强各种下游任务,例如对象检测和语义分割。
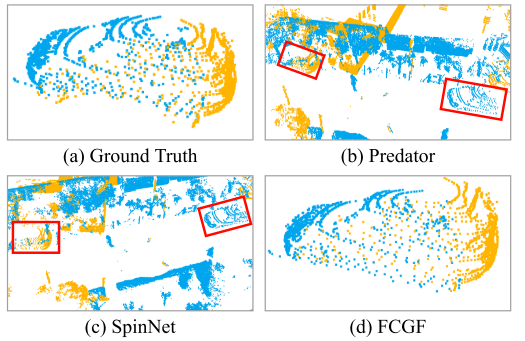
图1:(a)从具有不同点密度和传感器视角的两个良好对准的点云提取的示例车辆。
(b)-(d)SOTA点云配准方法的配准结果,即,Predator、SpinNet和FCGF。Predator和SpinNet无法很好地对齐两个点云,示例车辆在两个不同的位置(由红框指示)分开。FCGF可以粗略地对齐两个点云,但仍然不够准确。
一种用于移动车辆的实用在线远程点云注册方案必须满足以下三个要求:
1)它必须能够处理这种点云的密度和视图差异;
2)对于在线推理的计算和存储开销两者而言,它应该是成本有效的;
3)它必须实现上级的准确性,因为结果对于自主或辅助驾驶决策和驾驶安全应用至关重要。例如,对于驾驶安全应用来说,采用严格的配准准则是极其关键的,例如,0.5°的旋转误差和0.5米的平移误差(对应于在50米内的所有位置处小于一米的最大平移误差)。
在文献中,大多数点云配准方案以近点云(例如,10米),其具有相似的点密度并且共享目标对象上的重叠传感器视角。在这些方法中,特征提取器[Choy等人,2019; Bai等人,2020; Ao等人,2021; Huang等人,2021; Poiesi和Boscaini,2021]旨在提高特征质量。离群值拒绝方法[Bai等人,2021; Pais等人,2020; Choy等人,#20200;,以识别虚假的信息。端到端方法反过来创建新的注册管道。这些方法在传统方法的合并方面做出了很大努力[Aoki等人,2019; Yew和Lee,2020],特征匹配过程[Weixin等人,2019; Li等人,2020; Sarode等人,2019],使用Transformer提取上下文信息[Wang和所罗门,2019 a; Wang and所罗门,2019b; Ali等人,2021],以及基于局部块相似性假设执行分阶段配准[Lu等人,2021年; Yu等人,2021; Qin等人,2022]。然而,直接将这些方法应用于大规模户外远距离点云的精度是不令人满意的。例如,图1(B)-(d)描绘了在图1(a)中示出的示例两个远点云上的SOTA点云配准方法的结果。因此,据我们所知,没有现有的方案成功地解决了在线远程点云配准问题。
在本文中,我们提出了一种新的特征提取框架,称为聚合点云重建(APR),在线远程点云注册移动车辆。为了克服远处室外点云的密度和视图差异,如果两辆车都有完整的视图并更好地了解相同的环境,那将是理想的。受此启发,APR的主要思想是通过将具有关于当前环境的完整视图的更密集聚合点云的表示嵌入到特征中(称为APR特征)来训练强大的特征提取器。然后,两个对应的远点云的这种特征可以用于配准。
APR的主要思想是通过将具有关于当前环境的完整视图的更密集聚合点云的表示嵌入到特征中(称为APR特征)来训练强大的特征提取器
APR设计面临如下两个主要挑战。首先,训练如此强大的特征提取器以包含环境的完整视图是不平凡的。在APR设计中,通过自动编码器结构训练提取器。具体地,编码器可以是现有技术的特征提取主干(例如,FCGF或Predator),并且度量学习损失被应用于提取的特征,使得APR特征优选基于特征相似性的配准。此外,解码器对单个点云的特征图进行解码,并导出重构的点云,该重构的点云与聚合点云(APC)进行比较,该聚合点云被定义为对应车辆的一系列点云帧对齐在一起。结果,增强了编码器猜测更密集的几何形状的能力,使得APR特征包含丰富的环境信息。特别地,对于诸如Predator之类的存储器繁重的骨干,编码器和解码器是不对称的,以避免训练期间的存储器不足(OOM)问题。
在APR设计中,通过自动编码器结构训练提取器(编码器可以是现有技术的特征提取主干)
其次,对两个移动车辆执行在线远距离点云配准是具有挑战性的,因为它要求配准算法不仅准确而且快速。给定在每个车辆上收集的连续系列的点云帧,直接的方法是将来自每个车辆的多个帧作为输入以执行配准,这将招致沉重的存储器和计算成本,因为需要SLAM或多路配准来配准连续扫描。相比之下,在我们的设计中,由于编码器有能力猜测APC的功能,只有两个点云帧的一对车辆被用来执行在线成对注册。每个车辆的点云系列仅用于在离线训练期间生成聚合点云。
我们在以前的SOTA特征提取器上实现APR,即,FCGF [Choy等人,2019]和Predator [Huang et al.2021年]。我们提取了两个低重叠点云数据集,即,LoKITTI和LoNuScenes,与KITTI和nuScenes重叠≤ 30%,并进行广泛的实验。结果表明,APR可以有效地提高以前的特征提取器的性能,在LoKITTI和LoNuScenes上注册两个点云帧时,注册召回率(RR)分别增加了2.6%和5.2%,范围从5米到50米。
我们在本文件中强调我们的主要贡献如下:
·我们提出了一种自动编码器设计作为特征提取框架,其中编码器的描述性可以被增强,尽管解码器设计的多样性是对称的或不对称的。
·我们引入了一种新类型的点云重建目标,其中不是使用输入帧,而是使用附近的几个帧来描述不同视图和密度的环境,有效地应对密度变化和视图视差。
·我们进行了大量的实验,结果表明APR实现了远距离点云配准的SOTA性能。
- Related Work
在本节中,我们首先讨论传统的和基于学习的特征提取器,它们与我们的特征提取器密切相关;然后,我们转向端到端方法和基于重建的方法,介绍注册管道的最新进展。

传统特征提取器
传统方法[约翰逊和Hebert,1999; Rusu等人,2009; Tombari等人,2010]表示基于局部形状的特征匹配的早期探索。SpinImages(SI)[约翰逊和Hebert,1999]基于投影图像匹配点云; FPFH [Rusu等人,2009]提取局部几何形状的旋转不变直方图; SHOT [Tombari等人,2010]通过将局部参考帧(LRF)与几何直方图组合来发挥作用。然而,传统的方法通常要求表面法线,这是很难在实时场景中获得的,并且由于其有限的判别能力,很容易被学习方法超越。
Learning-based Feature Extractors
Patch-based Learning Methods.
基于补丁的学习方法的开创性工作是3DMatch [Zeng等人,2017],其在局部区域上应用3D卷积以提取用于配准的局部特征。PPF-Net [Deng等人,2018]利用PointNet [Qi等人,2017]以提取鲁棒的点对特征。PerfectMatch [Gojcic等人,2019]使用平滑密度值(SDV)来进一步提高特征鲁棒性。最近的进展包括DIP [Poiesi和Boscaini,2021],其使用倒角损失和最硬对比度损失的组合损失[Choy等人,2012]。2019]; SpinNet [Ao等人,2021]将LRF与SO(2)不变卷积相结合,以实现更好的旋转不变性。然而,这些方法通常具有有限的感受野,由于使用的局部补丁,和高的计算时间,由于重复的局部补丁计算。它们通常不能满足我们问题的实时性要求。
Fully Convolutional Methods.
为了自然地结合全局和局部信息,提出了完全卷积方法。FCGF [Choy等人,2019]首先将度量学习应用于密集卷积特征,实现SOTA性能,同时比基于补丁的方法快几个数量级。D3Feat [Bai等人,2020]通过采用KPConv改善FCGF [托马斯等人,2019年]并培训联合提取器-检测器骨干。Predator [Huang等人,2021]在瓶颈处使用重叠注意模块进一步解决低重叠问题,实现SOTA性能。我们实现我们的方法的基础上,这些方法,因为他们的快速和强大的性质完全符合我们的要求的骨干。
End-to-end Registration
端到端配准方法通常修改传统配准流水线的组件,将流水线转换成可以以端到端方式训练的网络。
Superpoint Matching Methods
基于超点的分阶段配准已经在高重叠点云上看到了成功[Lu等人,2021年; Yu等人,2021; Qin等人,2022],其中首先对下采样点云执行配准(即,超级点),然后级联到匹配的超级点周围的更密集的点云补丁上。然而,这些方法通常难以注册远距离的点云,因为补丁相似性假设在巨大的密度方差和视图视差下被打破。
Other Methods
一些方法诸如PointNetLK [Aoki等人,2019]和RPM-Net [Yew和Lee,2020]增强了优化算法[Lucas和Kanade,1981; Gold等人,1998],其中特征提取自PointNet [Qi等人,2017]。一些方法如DeepICP [Weixin et al.,2019]和IDAM [Li等人,2020]以可学习的方式细化特征匹配过程,减少误报。其他管道,包括DCP [Wang和所罗门,2019 a],PRNet [Wang和Solomon,2019 b]和RPSRNet [Ali等人,2021],使用转换器来获取特征之间的上下文信息。然而,它们通常专用于室内或合成点云数据集,并且通常无法扩展到室外LiDAR点云的水平。
Reconstruction-based Registration
我们知道其他方法也试图将倒角丢失和重建合并到配准管道中。
特征度量配准[Huang等人,2020]使用输入帧的重构,其基本上不要求信息损失。DIP [Poiesi和Boscaini,2021]仅使用倒角损失来对齐两个局部贴片。与他们专注于特征而不是几何形状相比,我们的解码器网络直接从特征中学习新点的偏移偏差,更专注于重建局部几何形状。
Chamfer loss是一种用于点云数据(point cloud data)的深度学习任务的损失函数。点云是由一组离散的点组成的三维数据表示形式,通常用于表示物体的形状或场景的几何信息。Chamfer loss的主要目标是测量两个点云之间的相似性或距离,通常用于点云配准(registration)、点云重建(reconstruction)和点云生成(generation)等任务中。
Chamfer loss的计算方法通常基于以下步骤:
1. 对于两个点云A和B,分别计算每个点到另一个点云中最近点的距离。这可以通过搜索最近邻点(nearest neighbor)来完成。
2. 对于点云A,计算每个点到点云B的最近距离,并将这些距离的平均值作为A到B的距离度量。
3. 同样,对于点云B,计算每个点到点云A的最近距离,并将这些距离的平均值作为B到A的距离度量。
4. 最后,Chamfer loss通常定义为A到B和B到A距离度量的平均值,即Chamfer Loss = (A到B距离 + B到A距离) / 2。
Chamfer loss的目标是最小化这个损失函数,从而使两个点云尽可能地接近或对齐。在点云配准中,通常使用Chamfer loss来衡量配准后的点云与参考点云之间的差异。在点云生成任务中,Chamfer loss可以用来评估生成的点云与真实点云之间的相似性。
Chamfer loss是点云相关任务中常用的损失函数之一,它有助于模型学习点云之间的几何对齐关系。
度量学习(Metric Learning)是一种机器学习任务,其重点是学习数据点之间的距离度量或相似性函数。度量学习的目标是将数据点映射到一个空间中,其中点之间的距离或相似性反映了数据中的潜在关系或相似性。这个学习到的度量可以用于各种任务,例如聚类、分类、检索和推荐。
度量学习的关键概念和组成部分包括:
1. **距离度量:** 在度量学习中,主要目标是学习一个合适的距离度量或相似性度量,以量化数据点对之间的相似性。常见的距离度量包括欧氏距离、马氏距离、余弦相似度等。
2. **训练数据:** 度量学习通常需要有标记的训练数据,其中每个数据点都与一个标签或类别相关联,从而可以学习如何度量不同类别之间的相似性或差异性。
3. **损失函数:** 在度量学习中,会定义一个损失函数,用于衡量学习到的度量与实际数据之间的差距。训练过程的目标是最小化这个损失函数,以使学习到的度量尽可能准确地反映数据之间的关系。
4. **应用领域:** 度量学习可以应用于多种领域,包括人脸识别、图像检索、推荐系统、文本相似性分析和聚类等。在这些领域中,度量学习可以帮助改进数据点之间的相似性度量,从而提高模型性能。
5. **嵌入空间:** 学习到的距离度量通常将数据点映射到一个低维嵌入空间中,其中点的相对位置反映了它们在原始空间中的相似性。这个嵌入空间可以用于各种下游任务。
度量学习的目标是改善数据表示,使得数据点之间的相似性在度量空间中更容易计算或解释。这在许多机器学习和数据挖掘任务中都具有重要意义,因为它可以提高模型的性能和可解释性。
- Problem Modeling
System Model
我们考虑进行在线远程点云注册移动车辆。每辆车都配备有LiDAR传感器,并且可以连续生成点云帧的时间序列(例如,每秒十个点云帧)。此外,相邻车辆可以经由宽带无线通信技术真实的有效地交换点云数据[Wang等人,2020; Perfecto等人,2017]。车辆具有用于点云数据存储的足够量的存储器,但是具有车载嵌入式系统的有限计算能力。在离线训练过程中,需要对点云序列中的一对点云框架之间的距离进行粗略估计。应注意,在在线注册期间,我们不需要关于车辆如何经由GPS或惯性传感器移动的任何侧信道信息(例如,加速度计和陀螺仪)。
Problem Definition

- System Design
聚合点云重建(APR)的核心思想是利用自动编码器结构来训练强大的编码器作为特征提取器。代替重构原始关键帧,自动编码器结构中的解码器重构聚合点云。因此,使用经过良好训练的编码器,可以从单个关键帧中提取特征,但是可以有效地表示具有密集和全景视图的环境点云,其用于在线配准。为此,如图2所示,APR具有分别用于离线训练和在线推断的不同流水线。更具体地说,培训管道由以下三个部分组成:
Key-frame Feature Extraction (KFE)
KFE是自动编码器结构中的编码器,其是完全卷积网络(FCN)。编码器充当特征提取器,其从关键帧提取特征,用于推理期间的在线注册和训练期间的非关键帧重构。APR是一个通用的特征提取框架,可以采用现有的每点特征提取器作为其编码器。例如,在我们当前的实现中,两个SOTA全卷积方法,即,FCGF [Choy等人,2019]和Predator [Huang et al.2021],以满足在线注册的实时要求。更多的点云特征提取器,例如D3Feat [Bai等人,2020年]将在未来通过。
APR的编码器可以用现有的编码器替代
Aggregated Point Cloud Generation (APG)
APG将当前关键帧的相邻非关键帧作为输入,并对齐它们以形成聚合点云(APC)作为解码器的重构目标。
Non-key-frame Point Cloud Reconstruction (NPR)
NPR充当自动编码器的解码器,其通过在对应于特征向量的点周围生成若干新点来从特征图显式地提取局部几何形状。使用倒角距离损失将生成的点与APG生成的APC进行比较。
在在线推理期间,仅当前关键帧在一对车辆之间交换。然后使用关键帧来提取APR特征,并在每个车辆处执行常规的基于特征的配准。