这篇博文主要是延续前文系列的总结记录,这里主要是总结汇总日常主流的文本数据向量化算法模型相关知识内容。
(1)词袋模型
词袋模型(Bag of Words)是一种常用的文本向量化方法,用于将文本转换为数值特征表示。它假设文本中的单词顺序并不重要,只关注单词的频率信息。下面将详细介绍其算法原理,并分析其优点和缺点。
算法原理:
构建词汇表:首先,通过预处理步骤,将文本数据进行分词,去除停用词、标点符号等,得到一系列的单词列表。然后,构建一个词汇表,包含所有出现过的单词。
特征向量表示:对于每个文本样本,在词汇表中的每个单词都有一个对应的索引位置。根据每个文本中各个单词在词汇表中的出现频率,构建一个特征向量,表示该文本的词袋特征。
向量化表示:最终,将所有文本的词袋特征向量组合在一起,形成一个矩阵,用于表示整个文本数据集。
优点:
简单有效:词袋模型是一种简单而有效的文本向量化方法,易于实现和理解。它仅考虑单词的出现频率,忽略了单词的顺序和上下文信息,适用于大多数文本分类和聚类任务。
适应多种文本类型:词袋模型对于不同类型的文本数据都适用,无论是短文本、长文本还是多语种文本,都可以通过构建词汇表和计算单词频率进行向量化。
可解释性强:由于词袋模型仅关注单词的频率,每个维度都可以直接对应到一个单词,因此可以提供更好的可解释性和可视化效果。
缺点:
词汇表增长问题:随着文本数据集的增大,词汇表的大小也会增加,可能导致高维稀疏的特征向量表示。这会带来存储和计算负担,并且可能导致过拟合问题。
忽略语义和上下文:词袋模型忽略了单词之间的语义和上下文信息,只考虑了单词出现的频率。因此,它无法捕捉单词之间的关系,可能导致信息丢失和模型的局限性。
停用词处理:词袋模型通常需要处理停用词(如“the”、“and”等),这些常见但无实际含义的单词可能会对向量表示产生噪声影响。
总结:
词袋模型是一种简单而有效的文本向量化方法,将文本转换为数值特征表示。它具有简单有效、适应多种文本类型和可解释性强等优点。然而,词袋模型存在词汇表增长、忽略语义和上下文以及停用词处理等缺点。在实际应用中,需要根据具体任务和数据特点来选择合适的文本向量化方法,并结合其他技术(如词嵌入)来提高算法的性能和表达能力。
Demo代码实现如下所示:
from sklearn.feature_extraction.text import CountVectorizer
# 创建文本数据集
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 创建词袋模型对象
vectorizer = CountVectorizer()
# 将文本数据集转换为词袋特征向量矩阵
X = vectorizer.fit_transform(corpus)
# 输出词汇表
print("Vocabulary:", vectorizer.get_feature_names())
# 输出特征向量矩阵
print("Feature Matrix:\n", X.toarray())
#输出如下
Vocabulary: ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
Feature Matrix:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
(2)N-gram模型
N-gram模型是一种常用的文本向量化方法,它考虑了文本中连续n个单词(或字符)的组合,并将其作为特征进行表示。下面将详细介绍N-gram模型的算法原理,并分析其优点和缺点。
算法原理:
N-gram提取:首先,将文本数据进行分词(或字符切分),得到一系列的单词(或字符)列表。然后,从每个文本样本中提取连续n个单词(或字符)的组合,形成一个特征序列。
构建特征向量:根据提取到的N-gram特征序列,构建一个特征向量表示该文本。特征向量的每个维度对应于一个不同的N-gram组合,通过计算其在文本中出现的频率或存在与否进行编码。
优点:
考虑上下文信息:相比于词袋模型,N-gram模型考虑了连续的N个单词(或字符)的组合,可以更好地捕捉语言中的上下文信息,有助于提高特征的表达能力。
保留局部顺序:N-gram模型保留了文本中的部分顺序信息,能够更好地区分具有不同顺序的N-gram组合,使得特征更具判别力。
适应不同数据类型:N-gram模型不仅可以应用于文本数据的向量化,还可以应用于字符序列、DNA序列等其他类型的数据。
缺点:
维度爆炸:当N值较大或文本数据集较大时,可能会导致特征空间的维度急剧增加,这会增加存储和计算的开销,并且可能引发过拟合问题。
数据稀疏性:在大规模文本数据集中,某些N-gram组合可能只出现很少甚至没有,导致特征矩阵中存在大量的零元素,造成数据的稀疏性。
对文本长度敏感:N-gram模型对文本的长度敏感,较长的文本可能包含更多的N-gram组合,因此可能会导致特征向量的维度增加。
总结:
N-gram模型是一种考虑上下文信息的文本向量化方法,通过提取连续N个单词(或字符)的组合来表示文本。它具有考虑上下文信息、保留局部顺序和适应不同数据类型等优点。然而,N-gram模型也存在维度爆炸、数据稀疏性和对文本长度敏感等缺点。在实际应用中,根据数据集的规模和特征需求,可以选择合适的N值,并结合其他技术(如特征选择、降维)来提高算法的性能和可靠性。
Demo代码实现如下所示:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化N-gram向量化器
ngram_vectorizer = CountVectorizer(ngram_range=(1, 2))
# 将文本数据转换为N-gram特征矩阵
X = ngram_vectorizer.fit_transform(dataset)
# 获取特征词汇列表
feature_vocab = ngram_vectorizer.get_feature_names()
# 打印特征矩阵和特征词汇
print("N-gram Feature Matrix:")
print(X.toarray())
print("Feature Vocabulary:")
print(feature_vocab)
输出如下所示:
N-gram Feature Matrix:
[[0 1 0 0 0 0 0 1 1 0 0]
[0 1 1 1 1 0 1 0 0 0 0]
[1 0 0 0 1 1 0 0 0 1 1]]
Feature Vocabulary:
['awesome', 'coding', 'coding is', 'fun', 'is', 'is awesome', 'is fun', 'love', 'love coding', 'python', 'python is']
[Finished in 8.9s](3)TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本向量化方法,用于衡量单词在文本中的重要性。下面将详细介绍TF-IDF算法的原理,并分析其优点和缺点。
算法原理:
词频(Term Frequency,TF):TF指的是一个单词在文本中出现的频率。它可以通过计算单词在文本中的出现次数或使用归一化的频率来表示。
逆文档频率(Inverse Document Frequency,IDF):IDF用于衡量一个单词在整个文本语料库中的重要性。它通过计算包含该单词的文档总数的倒数来表示。IDF值越大,表示单词越不常见,具有更高的重要性。
TF-IDF计算:TF-IDF通过将词频和逆文档频率相乘来计算每个单词在文本中的TF-IDF值。TF-IDF值越大,表示单词在文本中越重要。
优点:
特征权重高效:TF-IDF算法能够有效地对文本特征进行加权,将注意力集中到那些在文本中频繁出现但在整个语料库中较为罕见的单词上。这使得TF-IDF能够提供有区分性的特征,有助于提高模型性能。
考虑文档级别信息:TF-IDF不仅考虑了单词在文本中的频率,还考虑了单词在整个语料库中的分布情况。这样可以捕捉到一些反映文档主题或领域特定的单词,使得特征更具代表性。
简单而直观:TF-IDF算法的原理和计算公式相对简单,易于理解和实现。它是一种通用且经过验证的文本向量化方法。
缺点:
无法处理语义关系:TF-IDF算法忽略了单词之间的语义关系,只基于词频和文档频率进行加权。因此,在某些情况下,可能会导致一些语义相关但在文本中出现较少的单词被低估或忽略。
停用词的影响:TF-IDF算法对停用词(如“the”、“and”等)没有很好的处理策略。由于停用词在大多数文档中都非常常见,它们的逆文档频率较低,可能导致它们在TF-IDF表示中占据较大的权重。
数据稀疏性:在大规模的文本数据集中,特别是当考虑更大的特征空间时,TF-IDF表示可能会导致数据稀疏性问题。这可能会对存储和计算带来挑战,并可能需要进行降维或其他处理。
总结:
TF-IDF是一种常用的文本向量化方法,通过结合词频和逆文档频率来衡量单词的重要性。它具有特征权重高效、考虑文档级别信息和简单而直观等优点。然而,TF-IDF也存在无法处理语义关系、停用词的影响和数据稀疏性等缺点。在实际应用中,需要根据具体任务和数据特点来选择合适的文本向量化方法,并结合其他技术(如词嵌入)来提高算法效果。
Demo代码实现如下所示:
from sklearn.feature_extraction.text import TfidfVectorizer
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化TF-IDF向量化器
tfidf_vectorizer = TfidfVectorizer()
# 将文本数据转换为TF-IDF特征矩阵
X = tfidf_vectorizer.fit_transform(dataset)
# 获取特征词汇列表
feature_vocab = tfidf_vectorizer.get_feature_names()
# 打印特征矩阵和特征词汇
print("TF-IDF Feature Matrix:")
print(X.toarray())
print("Feature Vocabulary:")
print(feature_vocab)
(4)Word2Vec
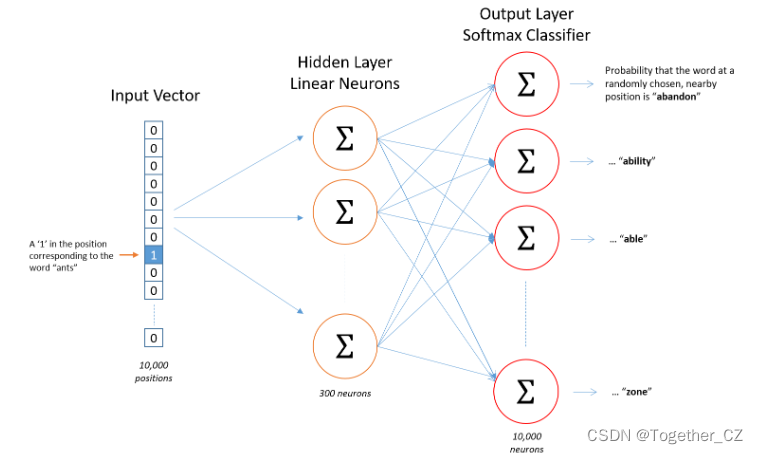
Word2Vec是一种用于将自然语言文本转换为向量表示(即嵌入)的算法。它的核心思想是将词语表示为高维空间中的向量,从而捕捉词语之间的相似性和语义关系。Word2Vec具有两种主要实现:Skip-gram和Continuous Bag of Words(CBOW)。
算法原理:
Skip-gram
Skip-gram模型的目标是利用一个词来预测它周围的上下文词。为了训练这个模型,我们使用一个滑动窗口在文本中移动,将中心词作为输入,试图预测窗口内的其他词。通过优化这个预测任务,模型学习到词语的向量表示。Skip-gram模型对于大型语料库和稀有词处理较好,但计算成本较高。
Continuous Bag of Words (CBOW)
CBOW模型与Skip-gram模型相反,它试图通过上下文词来预测目标词。在这个模型中,我们将窗口内的周围词作为输入,并试图预测中心词。CBOW模型的计算成本相对较低,因为它平均了上下文词的向量表示,但它对于稀有词的处理较差。
优点:
Word2Vec能够捕捉词语之间的语义和语法关系。相似的词语在向量空间中距离较近,这有助于提高自然语言处理任务的性能。
相比于词袋模型和TF-IDF表示方法,Word2Vec具有较低的维度,因此计算上更高效。
Word2Vec可以通过在线学习的方式更新模型,这使得在新数据到来时能够继续训练模型。
缺点:
Word2Vec的一个主要缺点是,它不能很好地处理多义词。由于每个词只有一个向量表示,多义词的不同含义无法分开表示。
Word2Vec是基于局部上下文捕捉词语信息的,因此可能无法充分捕捉到长距离的依赖关系和全局语义信息。
Word2Vec需要大量的训练数据和计算资源。对于小型语料库,它可能无法生成高质量的词向量。
尽管Word2Vec具有一定的局限性,但它在许多自然语言处理任务中取得了显著的成功。此外,它的出现催生了许多其他词嵌入技术,如GloVe、fastText和BERT等。
Demo代码实现如下所示:

import re
from gensim.models import Word2Vec
# 示例文本数据集
text = """
The quick brown fox jumps over the lazy dog.
The dog barks at the fox.
The cat meows at the dog.
The dog chases the cat.
"""
# 文本预处理
def preprocess(text):
# 转换为小写并移除标点符号
text = re.sub(r'[^\w\s]', '', text.lower())
# 分词
sentences = [sentence.split() for sentence in text.split('\n') if sentence]
return sentences
# 预处理数据集
sentences = preprocess(text)
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 保存和加载模型
model.save("word2vec.model")
model = Word2Vec.load("word2vec.model")
# 获取词向量
vector = model.wv['fox']
print("Vector for 'fox':", vector)
# 搜索相似词
similar_words = model.wv.most_similar('fox', topn=3)
print("Top 3 similar words to 'fox':", similar_words)(5)GloVe
GloVe(Global Vectors for Word Representation)是一种文本向量化方法,旨在将单词表示为向量,并在向量空间中捕获单词之间的语义关系。
算法原理:
GloVe算法的核心思想是基于共现矩阵(co-occurrence matrix)来学习单词的向量表示。共现矩阵记录了文本中每对单词在一定上下文窗口内出现的频率。GloVe通过将这些频率转换为概率,然后计算单词之间的共现概率比值来构建词向量。
具体来说,GloVe算法分两个步骤:
构建共现矩阵:遍历文本数据,统计每对单词在一个窗口内出现的次数。窗口大小决定了被考虑为上下文的单词范围。根据窗口大小和单词的距离,给予不同的权重。
训练词向量:通过优化目标函数,学习到单词的向量表示。目标函数是最小化单词向量之间的误差和观察到的共现概率之间的差异。模型的优化过程使用随机梯度下降(SGD)等优化算法。
优点:
GloVe算法可以更好地处理多义词。由于GloVe使用全局统计信息,将共现频率转化为概率比值,可以更好地区分单词不同的语义含义。
相比于Word2Vec,GloVe算法具有线性计算复杂性,因此在大规模语料库上的训练速度更快。
GloVe模型产生的词向量在语义上更加准确,能够捕捉到更多的语义关系,如相似性、类比关系等。
缺点:
GloVe算法对于低频词和稀有词的处理相对较弱。由于低频词在共现矩阵中出现次数较少,其学习到的向量表示可能不够准确。
GloVe算法需要大量的训练数据和计算资源。对于小型语料库,可能无法生成高质量的词向量。
GloVe模型在处理复杂的语义关系时可能存在一定的限制。它的表达能力可能不如一些更高级的模型,如BERT等。
尽管GloVe算法存在一些限制,但它仍然被广泛使用,并在许多自然语言处理任务中取得了良好的效果。它的出现丰富了文本向量化方法的选择,为研究人员和从业者提供了更多的选择。
Demo代码实现如下所示:
import numpy as np
"""
GloVe(全局词向量表示)是一种用于生成词向量的算法,它结合了全局语料库统计信息和局部上下文信息。与Word2Vec算法不同,GloVe算法直接通过最小化损失函数来学习词向量,而不需要运行迭代训练过程。
GloVe算法的目标是,对于在语料库中经常一起出现的词对,生成具有相似语义的词向量。为了实现这一目标,GloVe算法通过建立词共现矩阵来捕捉词对之间的共现信息。该矩阵表示了语料库中词对的共现频率。
GloVe算法的步骤如下:
构建共现矩阵:遍历语料库,对每个单词在其上下文窗口内出现的词进行计数。
计算词向量:利用共现矩阵计算词对的权重和互信息。
计算损失函数:利用词对的权重和互信息,计算词对的损失函数。
更新词向量:通过梯度下降法,根据损失函数的梯度更新词向量。
迭代训练:重复步骤3和步骤4,直到达到预定的训练轮数或收敛条件。
"""
class GloVe:
def __init__(self, corpus, vector_size=100, window_size=5, learning_rate=0.05, num_epochs=100):
self.corpus = corpus
self.vector_size = vector_size
self.window_size = window_size
self.learning_rate = learning_rate
self.num_epochs = num_epochs
self.word2idx = {}
self.idx2word = {}
self.V = None
self.U = None
def build_vocab(self):
words = []
for sentence in self.corpus:
words.extend(sentence.split())
words = list(set(words))
self.word2idx = {word: idx for idx, word in enumerate(words)}
self.idx2word = {idx: word for idx, word in enumerate(words)}
def co_occurrence_matrix(self):
vocab_size = len(self.word2idx)
co_matrix = np.zeros((vocab_size, vocab_size))
for sentence in self.corpus:
words_in_sentence = sentence.split()
for i in range(len(words_in_sentence)):
center_word = self.word2idx[words_in_sentence[i]]
for j in range(i - self.window_size, i + self.window_size + 1):
if j != i and j >= 0 and j < len(words_in_sentence):
context_word = self.word2idx[words_in_sentence[j]]
co_matrix[center_word][context_word] += 1
return co_matrix
def train(self):
self.build_vocab()
co_matrix = self.co_occurrence_matrix()
vocab_size = len(self.word2idx)
self.V = np.random.uniform(-1, 1, (vocab_size, self.vector_size))
self.U = np.random.uniform(-1, 1, (vocab_size, self.vector_size))
for epoch in range(self.num_epochs):
for i in range(vocab_size):
for j in range(vocab_size):
if i != j and co_matrix[i, j] > 0:
weight = np.log(co_matrix[i, j] + 1)
error = np.dot(self.U[i], self.V[j]) - np.log(co_matrix[i, j])
self.V[j] -= self.learning_rate * weight * error * self.U[i]
self.U[i] -= self.learning_rate * weight * error * self.V[j]
def get_word_vector(self, word):
idx = self.word2idx[word]
return self.V[idx]
def most_similar_words(self, word, topn=10):
word_vector = self.get_word_vector(word)
similarity_scores = np.dot(self.V, word_vector) / (np.linalg.norm(self.V, axis=1) * np.linalg.norm(word_vector))
idxs = np.argsort(similarity_scores)[::-1]
similar_words = [self.idx2word[idx] for idx in idxs[:topn]]
return similar_words
# 生成数据集
corpus = [
"The quick brown fox jumps over the lazy dog.",
"The dog barks at the fox.",
"The cat meows at the dog.",
"The dog chases the cat."
]
# 实例化GloVe模型
glove_model = GloVe(corpus)
# 训练模型
glove_model.train()
# 测试获取词向量和搜索相似词
word_vector = glove_model.get_word_vector('fox')
print("Vector for 'fox':", word_vector)
similar_words = glove_model.most_similar_words('fox', topn=3)
print("Top 3 similar words to 'fox':", similar_words)(6)FastText
FastText是一种文本向量化方法,它在Word2Vec的基础上进行了改进,主要用于处理词汇中的子词信息。FastText的核心思想是将单词表示为字符级别的n-gram,并通过使用局部上下文信息来捕捉单词的语义。
算法原理:
FastText算法的主要步骤如下:
字符级别的n-gram表示:FastText首先将单词划分为字符序列,然后构建字符级别的n-gram。例如,对于单词"apple",当n=3时,生成的n-gram有"app","ppl","ple"和"le"。这种字符级别的表示方式能够保留词中的一些字母序列信息,对于处理词汇中的前缀、后缀和内部结构具有较好的效果。
局部上下文学习:在FastText中,每个单词的向量表示是通过将字符级别的n-gram进行平均得到的。具体来说,对于一个单词,将其所有的n-gram向量进行平均得到单词的向量表示。这样的做法能够充分利用局部上下文信息,并捕获到单词在不同语境中的特征。
分类器训练:FastText还可以用于文本分类任务。在训练分类器时,它使用了层次化的Softmax分类器(hierarchical softmax classifier)来提高训练速度和效率。该分类器使用了树结构,将单词划分为不同的类别,通过预测单词所在类别的概率进行分类。
优点:
FastText能够处理词汇中的子词信息,对于处理未见过的词汇或低频词非常有效,因为它能够利用词汇的字符级别的n-gram信息。
FastText在训练速度上具有较大的优势,相比于基于Word2Vec的方法,它能够更快地训练出词向量模型。
FastText模型的表达能力较强,能够捕捉到更细粒度的语义信息,例如前缀、后缀和内部结构等。
缺点:
FastText模型相对于Word2Vec模型来说,所得到的词向量会更大,并且需要更多的内存存储。
由于FastText使用了字符级别的n-gram表示,当处理较长的文本时,训练和使用速度可能会受到一定的影响。
相对于一些更高级的模型,例如BERT,FastText的表达能力可能较弱,无法捕捉到更复杂的语义关系。
尽管FastText算法存在一些局限性,但它在处理自然语言处理任务中的词汇信息时具有一定的优势。在一些需要考虑词汇内部结构和处理低频词的应用场景中,FastText通常能够提供较好的性能。
import gensim
"""
FastText是一种文本向量化方法,它是基于Word2Vec的扩展。与Word2Vec只考虑单词级别的向量表示不同,FastText还考虑了子词级别的信息。通过将单词拆分为子词,FastText可以生成更加丰富的词向量,并且能够更好地处理不常见的单词。
"""
class FastText:
def __init__(self, corpus, vector_size=100, window_size=5, min_count=1, epochs=5):
self.corpus = corpus
self.vector_size = vector_size
self.window_size = window_size
self.min_count = min_count
self.epochs = epochs
self.model = None
def train(self):
sentences = [sentence.split() for sentence in self.corpus]
self.model = gensim.models.FastText(sentences=sentences, vector_size=self.vector_size,
window=self.window_size, min_count=self.min_count,
epochs=self.epochs)
def get_word_vector(self, word):
if self.model:
return self.model.wv[word]
else:
raise ValueError("Model has not been trained yet.")
def most_similar_words(self, word, topn=10):
if self.model:
return self.model.wv.most_similar(word, topn=topn)
else:
raise ValueError("Model has not been trained yet.")
# 生成数据集
corpus = [
"The quick brown fox jumps over the lazy dog.",
"The dog barks at the fox.",
"The cat meows at the dog.",
"The dog chases the cat."
]
# 实例化FastText模型
fasttext_model = FastText(corpus)
# 训练模型
fasttext_model.train()
# 测试获取词向量和搜索相似词
word_vector = fasttext_model.get_word_vector('fox')
print("Vector for 'fox':", word_vector)
similar_words = fasttext_model.most_similar_words('fox', topn=3)
print("Top 3 similar words to 'fox':", similar_words)(7)ELMo
ELMo(Embeddings from Language Models)是一种文本向量化方法,它基于预训练的双向语言模型来学习单词和短语的向量表示。ELMo在文本建模中获得了广泛的应用,并在自然语言处理任务中取得了优秀的性能。
算法原理:
ELMo算法主要基于两个核心思想:1)使用深层双向语言模型来学习单词和短语的上下文特征;2)通过将不同层次的隐藏表示进行加权求和来生成最终的向量表示。
具体来说,ELMo的算法原理包括以下步骤:
预训练语言模型:ELMo使用大规模的无标注语料库来预训练深层双向语言模型。双向语言模型由两个方向的循环神经网络(RNN)组成,分别从前向和后向对文本进行建模。这使得ELMo能够利用上下文语境中的信息来学习单词和短语的表示。
获取上下文表示:给定输入文本序列,ELMo将文本通过预训练的双向语言模型进行前向和后向的编码操作,得到不同层次的隐藏表示。
加权求和:为了生成最终的向量表示,ELMo使用了线性加权求和来结合不同层次的隐藏表示。通过学习任务自适应的权重,ELMo能够根据具体任务对不同层次的表示进行加权组合,从而获得更具有表达性的向量表示。
下游任务微调:在具体的下游任务中,使用ELMo生成的向量表示作为输入,然后在小规模标注数据上进行微调,以适应具体任务的需求。
优点:
ELMo能够捕捉到丰富的上下文语义信息,因为它使用了深层双向语言模型来建模文本的上下文。
ELMo生成的向量表示具有上下文感知性,能够更好地处理词汇的多义性和歧义性。
ELMo的向量表示可以应用于各种下游任务,如文本分类、命名实体识别、机器翻译等,并且能够取得很好的性能。
缺点:
ELMo算法需要大量的训练数据和计算资源进行预训练,因此在拥有有限数据集时可能效果不佳。
ELMo的计算复杂度较高,因为它需要进行前向和后向的编码操作,并且需要对不同层次的隐藏表示进行加权求和。
ELMo生成的向量表示较为复杂,可能会导致模型的解释性较差,并且在一些简单任务上效果不明显。
尽管ELMo算法存在一些限制和挑战,但它在处理自然语言处理任务中的上下文特征时具有很大优势。它的出现提升了文本向量化方法的表达能力,广泛应用于多种自然语言处理任务中。
Demo代码实现如下所示:
import tensorflow as tf
import tensorflow_hub as hub
"""
ELMo是一种基于深度双向语言模型(Deep Bidirectional Language Models)的文本向量化方法。它通过学习大规模无标注语料库的语言模型,提取各层的隐藏状态,并将这些隐藏状态作为文本的向量表示。由于ELMo使用深层语言模型的隐藏状态,它能够捕捉到单词在不同上下文中的多义性和语义变化。
在实际使用ELMo时,由于ELMo模型比较庞大,加载模型会需要一些时间。建议将加载模型的过程放在预处理阶段,以便在需要使用ELMo时可以直接调用。此外,在训练自己的ELMo模型时,可以使用更大的语料库和更复杂的模型结构来获得更好的向量表示。
"""
class ELMo:
def __init__(self):
self.model = None
def load_model(self):
self.model = hub.load("https://tfhub.dev/google/elmo/3")
def get_word_vectors(self, sentences):
if self.model:
embeddings = self.model(sentences)
return embeddings
else:
raise ValueError("Model has not been loaded yet.")
# 生成数据集
corpus = [
"The quick brown fox jumps over the lazy dog.",
"The dog barks at the fox.",
"The cat meows at the dog.",
"The dog chases the cat."
]
# 实例化ELMo模型
elmo_model = ELMo()
# 加载模型
elmo_model.load_model()
# 测试获取词向量
sentences = ["The quick brown fox", "The dog barks at the fox"]
word_vectors = elmo_model.get_word_vectors(sentences)
print("Word vectors:", word_vectors)(8)BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练模型,用于将文本序列映射为高维向量表示,并在各种自然语言处理任务中表现出色。下面将详细介绍BERT算法的原理,并分析其优点和缺点。
算法原理:
BERT的核心结构是Transformer,它由多个编码器层组成。每个编码器层都由多头自注意力机制(multi-head self-attention mechanism)和前馈神经网络(feed-forward neural network)组成。
词嵌入层:BERT首先将输入文本序列的单词转换为对应的分布式表示,即词嵌入。这些嵌入包含了单词的语义信息和上下文关系。
Transformer编码器:BERT使用多层Transformer编码器来捕捉整个文本序列的上下文依赖关系。每个编码器层都可以通过多头自注意力机制来同时考虑输入序列的全局和局部上下文信息。
预训练阶段:在预训练阶段,BERT通过大规模无标签的文本数据进行训练。该阶段包括两个任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
MLM任务:随机掩盖输入序列的某些单词,并通过Transformer编码器来预测被掩盖的单词。
NSP任务:判断两个输入句子是否是原始文本中按顺序相邻的句子。
优点:
上下文感知能力:BERT模型具有深层的Transformer编码器,能够充分捕捉文本序列中的上下文依赖关系。这使得它在处理自然语言处理任务时能够更好地理解和表达文本的含义。
预训练与微调:BERT通过大规模无标签数据进行预训练,学习到丰富的语义信息。然后,在具体任务上进行微调,使其适应特定的任务,提高模型性能。
双向编码:BERT采用了双向编码策略,不仅考虑了给定单词之前的上下文,还考虑了之后的上下文,从而更好地捕捉句子中的语义关系。
缺点:
计算资源需求高:BERT模型通常需要大量的计算资源和时间来进行训练和推理,特别是对于较大的模型和复杂的任务,可能会面临计算资源限制的问题。
数据需求量大:为了获得良好的性能,BERT模型需要大规模的数据集进行预训练。在某些领域或特定任务上,数据集可能稀缺,这可能会影响模型的表现。
难以解释性:BERT模型是一个黑盒模型,难以解释其具体运行原理和决策过程。这对于一些敏感应用场景或需要可解释性的任务来说可能是一个问题。
总结:
BERT是一种基于Transformer架构的预训练模型,能够将文本序列映射为高维向量表示,并具有上下文感知能力、预训练与微调和双向编码等优点。然而,BERT也存在计算资源需求高、数据需求量大和难以解释性等缺点。在实际应用中,可以根据任务需求和可用的资源来选择合适的BERT算法,同时结合其他技术和方法来克服其缺点,例如使用更小规模的BERT模型、采用迁移学习、对抗训练等。
另外,还有一些与BERT相关的改进算法,如RoBERTa、ALBERT、DistilBERT等,它们在对BERT进行改进的基础上,针对性地解决了一些问题,例如训练效率、模型大小等。这些改进算法可以根据具体任务和资源约束进行选择,以获得更好的性能和效果。
总之,BERT算法通过预训练和微调的方式,在文本向量化任务上取得了重要的突破。它具有上下文感知能力、预训练与微调、双向编码等优点,但也面临计算资源需求高、数据需求量大和难以解释性等挑战。在实际应用中,可以结合具体任务和资源情况,选择合适的BERT模型或改进算法,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
from transformers import BertTokenizer, BertModel
import torch
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 初始化BERT模型
model = BertModel.from_pretrained('bert-base-uncased')
# 将文本转换为BERT向量表示
def text_to_bert_vector(text):
# 分词并添加特殊标记
tokens = tokenizer.encode(text, add_special_tokens=True)
# 转换为PyTorch张量
input_ids = torch.tensor(tokens).unsqueeze(0) # 添加批次维度
# 使用BERT模型获取隐藏状态
with torch.no_grad():
outputs = model(input_ids)
hidden_states = outputs[0]
# 取最后一层的CLS标记的隐藏状态作为句子向量
sentence_vector = hidden_states[:, 0, :]
return sentence_vector.squeeze().tolist()
# 对数据集中的每个样本进行向量化
vectors = [text_to_bert_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"Bert Vector: {vector}")
print()
(9)GPT
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的预训练模型,用于将文本序列映射为高维向量表示,并在各种自然语言处理任务中表现出色。下面将详细介绍GPT算法的原理,并分析其优点和缺点。
算法原理:
GPT模型采用了Transformer架构,其中包含多个解码器层。每个解码器层由多头自注意力机制和前馈神经网络组成。
词嵌入层:GPT首先将输入文本序列的单词转换为对应的分布式表示,即词嵌入。这些嵌入包含了单词的语义信息和上下文关系。
Transformer解码器:GPT使用多层Transformer解码器来生成文本序列的高维向量表示。每个解码器层通过自注意力机制和前馈神经网络对输入序列进行编码和建模,以捕获上下文信息。
预训练阶段:在预训练阶段,GPT通过大规模无标签的文本数据进行训练。该阶段通常采用语言模型的方式,在给定部分文本的情况下预测下一个单词或下一个片段。
优点:
上下文感知能力:GPT模型通过Transformer架构能够充分捕捉文本序列中的上下文依赖关系,从而理解和表达文本的含义。这使得它在自然语言处理任务中具有较强的性能。
生成能力:GPT通过预训练的方式让模型学习到大规模语料库中的概率分布,因此可以用于生成连贯、合理的文本。该特性在生成式任务中具有重要的应用价值。
可扩展性:GPT采用了Transformer的架构,使其具有良好的可扩展性。可以通过增加层级或者调整模型大小来提高模型性能。
缺点:
计算资源需求高:GPT模型通常需要大量的计算资源和时间来进行训练和推理,特别是对于较大规模的模型和复杂任务。这限制了GPT模型的使用范围和实际应用。
预训练与微调过程:由于GPT模型采用预训练与微调的方式,需要大量的无标签数据进行预训练,然后再使用有标签数据进行微调。这可能会带来数据收集和标注的难题。
局限于单向信息:GPT模型只考虑了给定单词之前的上下文,而未来的上下文信息并未直接参与建模。这可能限制了模型对于双向上下文关系的感知能力。
总结:
GPT是一种基于Transformer架构的预训练模型,用于将文本序列映射为高维向量表示,并具有上下文感知能力、生成能力和可扩展性等优点。然而,GPT也面临计算资源需求高、预训练与微调过程复杂以及局限于单向信息等挑战。在实际应用中,可以根据具体任务和资源情况选择合适的GPT模型,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
from transformers import GPT2Tokenizer, GPT2Model
import torch
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化GPT tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 初始化GPT模型
model = GPT2Model.from_pretrained('gpt2')
# 将文本转换为GPT向量表示
def text_to_gpt_vector(text):
# 分词并添加特殊标记
tokens = tokenizer.encode(text, add_special_tokens=True)
# 转换为PyTorch张量
input_ids = torch.tensor(tokens).unsqueeze(0) # 添加批次维度
# 使用GPT模型获取隐藏状态
with torch.no_grad():
outputs = model(input_ids)
hidden_states = outputs[0]
# 取最后一层的CLS标记的隐藏状态作为句子向量
sentence_vector = hidden_states[:, -1, :]
return sentence_vector.squeeze().tolist()
# 对数据集中的每个样本进行向量化
vectors = [text_to_gpt_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"GPT Vector: {vector}")
print()
(10)Transformer-XL
Transformer-XL是一种改进的Transformer架构,用于文本序列的向量化表示。它通过利用相对位置编码和长序列建模来解决传统Transformer模型中的上下文限制问题。下面将详细介绍Transformer-XL算法的原理,并分析其优点和缺点。
算法原理:
Transformer-XL在传统Transformer的基础上引入了两个关键概念:相对位置编码和循环机制。
相对位置编码:传统Transformer使用绝对位置编码来表示输入序列中单词的位置信息。而Transformer-XL引入了相对位置编码,它能够捕捉到不同单词之间的相对距离信息,从而更好地建模长序列的依赖关系。
循环机制:为了解决传统Transformer中的上下文限制问题,Transformer-XL采用了循环机制,允许模型在每个时间步中重用前面的隐藏状态。这使得Transformer-XL能够更好地处理长序列,并且能够捕捉较远距离的依赖关系。
优点:
长序列建模:传统Transformer模型在处理长序列时存在内存限制和梯度消失等问题,而Transformer-XL通过引入相对位置编码和循环机制,能够有效处理长序列并捕捉较远距离的依赖关系。
上下文感知能力:Transformer-XL的循环机制允许模型重用前面的隐藏状态,使得模型能够更好地理解和表达序列中的上下文信息,从而提高了模型的性能。
高效训练:相对位置编码的引入使得Transformer-XL可以并行计算,减少了模型在训练过程中的计算量,从而提高了训练效率。
缺点:
计算资源需求高:虽然相对位置编码的引入使得Transformer-XL的训练过程更高效,但其仍然需要较大的计算资源来进行训练和推理,特别是对于较大规模的模型和复杂任务。
模型复杂性:相对位置编码和循环机制的引入增加了模型的复杂性,导致模型的存储和计算成本增加。这可能会限制Transformer-XL在资源受限环境中的应用。
总结:
Transformer-XL是一种改进的Transformer架构,通过引入相对位置编码和循环机制来解决传统Transformer模型中的上下文限制问题。它具有长序列建模能力、上下文感知能力和高效训练等优点。然而,Transformer-XL也面临计算资源需求高和模型复杂性的挑战。在实际应用中,可以根据任务需求和资源限制选择合适的Transformer-XL模型,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
from transformers import TransfoXLTokenizer, TransfoXLModel
import torch
"""
首先定义了一个包含三个文本样本的数据集。然后使用TransfoXLTokenizer和TransfoXLModel从Hugging Face库中初始化Transformer-XL tokenizer和Transformer-XL模型,加载预训练的transfo-xl-wt103模型。
接下来定义了一个辅助函数text_to_transformerxl_vector,用于将文本转换为Transformer-XL向量表示。在这个函数中首先使用tokenizer将文本分词,并添加特殊标记,然后将其转换为PyTorch张量。接着使用Transformer-XL模型对输入的张量获取隐藏状态,最后取最后一层中CLS标记的隐藏状态作为句子向量。
最后对数据集中的每个样本调用text_to_transformerxl_vector函数进行向量化,得到Transformer-XL文本向量化结果,并打印出来。
"""
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化Transformer-XL tokenizer
tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')
# 初始化Transformer-XL模型
model = TransfoXLModel.from_pretrained('transfo-xl-wt103')
# 将文本转换为Transformer-XL向量表示
def text_to_transformerxl_vector(text):
# 分词并添加特殊标记
tokens = tokenizer.encode(text, add_special_tokens=True)
# 转换为PyTorch张量
input_ids = torch.tensor(tokens).unsqueeze(0) # 添加批次维度
# 使用Transformer-XL模型获取隐藏状态
with torch.no_grad():
outputs = model(input_ids)
hidden_states = outputs[0]
# 取最后一层的CLS标记的隐藏状态作为句子向量
sentence_vector = hidden_states[:, -1, :]
return sentence_vector.squeeze().tolist()
# 对数据集中的每个样本进行向量化
vectors = [text_to_transformerxl_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"Transformer-XL Vector: {vector}")
print()
(11)XLNet
XLNet是一种基于Transformer架构的预训练语言模型,用于文本向量化表示。它通过自回归和自编码的方式进行预训练,并引入了排列语言模型(Permutation Language Model)的概念,以解决传统语言模型的限制。下面将详细介绍XLNet算法的原理,并分析其优点和缺点。
算法原理:
XLNet算法的核心思想是使用排列语言模型进行预训练,以捕捉文本序列中的全局依赖关系。
排列语言模型:与传统的自回归语言模型不同,排列语言模型在预测当前位置时考虑了所有位置的信息,而不仅限于当前位置之前的信息。这使得模型能够更好地处理序列中的长距离依赖关系。
自编码器结构:XLNet利用自编码器结构,在预训练阶段将输入序列中的一部分遮盖或替换为特殊的掩码标记,并通过最大似然估计来学习序列的联合概率分布。这使得模型能够学习到全局的上下文信息,从而提高了向量表示的质量。
多层双向Transformer:XLNet采用了多层双向Transformer结构,其中每个Transformer层都包含自注意力机制和前馈神经网络。这使得模型能够在不同层次的抽象中学习到不同级别的语义信息。
优点:
全局依赖关系建模:XLNet通过排列语言模型的方式,在预训练阶段考虑了所有位置的信息,从而能够更好地捕捉文本序列中的全局依赖关系。
自编码器结构:XLNet利用自编码器结构进行预训练,能够学习到全局的上下文信息,提高向量表示的质量和表达能力。
双向Transformer架构:采用双向Transformer结构,在不同层次的抽象中学习到不同级别的语义信息,提高了模型的性能和泛化能力。
零样本学习:由于XLNet的预训练过程中采用了自编码器结构,使得模型能够通过遮盖和替换输入序列的部分内容进行训练。这使得XLNet在一定程度上具备了零样本学习的能力,可以应对一些未见过的单词或短语。
解决排除偏差:传统的自回归语言模型需要根据左侧已生成的内容来预测下一个单词,容易导致偏向性。而XLNet通过排列语言模型的方式,在生成每个位置时都考虑了所有其他位置的信息,有助于缓解这种偏差问题。
缺点:
计算资源需求高:XLNet模型通常需要大量的计算资源和时间来进行训练和推理,特别是对于较大规模的模型和复杂任务。这限制了XLNet模型的使用范围和实际应用。
预训练与微调过程:由于XLNet采用预训练与微调的方式,需要大量的无标签数据进行预训练,然后再使用有标签数据进行微调,这可能会带来数据收集和标注的难题。
解释性较差:XLNet模型的复杂性导致其解释性较差,对于生成的结果往往难以解释和理解。
计算资源消耗大:与其他基于Transformer架构的模型类似,XLNet在训练和推理过程中需要大量的计算资源和时间。特别是在处理较大规模的数据集和复杂任务时,计算资源需求更高。
预训练与微调过程复杂:XLNet的预训练过程涉及到大量无标签数据的训练,然后再使用有标签数据进行微调。这需要耗费大量的时间、计算资源和标注数据,限制了模型的实际应用范围。
难以解释性:XLNet模型的复杂性导致其解释性较差。生成的结果往往难以被解释和理解,这在一些对于解释性要求较高的任务中可能存在问题。
总结:
XLNet是一种基于Transformer架构的预训练语言模型,通过排列语言模型和自编码器结构来捕捉文本序列中的全局依赖关系,并具有全局依赖关系建模和自编码器结构、双向Transformer架构等优点。然而,XLNet也面临计算资源需求高、预训练与微调过程复杂以及解释性较差的挑战。在实际应用中,可以根据任务需求和资源限制选择合适的XLNet模型,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
from transformers import XLNetTokenizer, XLNetModel
import torch
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化XLNet tokenizer
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
# 初始化XLNet模型
model = XLNetModel.from_pretrained('xlnet-base-cased')
# 将文本转换为XLNet向量表示
def text_to_xlnet_vector(text):
# 分词并添加特殊标记
tokens = tokenizer.encode(text, add_special_tokens=True)
# 转换为PyTorch张量
input_ids = torch.tensor(tokens).unsqueeze(0) # 添加批次维度
# 使用XLNet模型获取隐藏状态
with torch.no_grad():
outputs = model(input_ids)
hidden_states = outputs[0]
# 取最后一层的CLS标记的隐藏状态作为句子向量
sentence_vector = hidden_states[:, -1, :]
return sentence_vector.squeeze().tolist()
# 对数据集中的每个样本进行向量化
vectors = [text_to_xlnet_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"XLNet Vector: {vector}")
print()
(12)ALBERT
ALBERT(A Lite BERT)是一种轻量级的BERT(Bidirectional Encoder Representations from Transformers)模型,用于文本向量化表示。它通过参数共享和句子顺序预测等方法来减少BERT模型的复杂度和训练成本。下面将详细介绍ALBERT算法的原理,并分析其优点和缺点。
算法原理:
ALBERT算法具有以下关键思想和原理:
参数共享:传统的BERT模型中,Encoder层和Transformer层都是独立的,导致模型参数大量冗余。而ALBERT引入了参数共享机制,将不同位置的Transformer层共享参数,从而大幅减少了模型的参数数量。
句子顺序预测:与BERT模型采用的遮盖语言建模不同,ALBERT使用句子顺序预测任务来进行预训练。这样可以减少训练过程中的计算量,并且能够更好地捕捉上下文信息。
文本段落划分:为了进一步降低模型复杂度,ALBERT将输入文本划分为若干个连续的片段。每个片段包含多个句子,这样可以在保持上下文关系的同时减少模型的计算量。
优点:
轻量级模型:通过参数共享和文本段落划分等技术,ALBERT大幅减少了模型的参数数量和复杂度,使得模型更加轻量级,并且具有较快的训练速度和推理速度。
高效训练和推理:由于ALBERT的轻量化设计,它在训练和推理过程中消耗的计算资源较少,特别是对于资源受限的环境下,能够更高效地进行训练和使用。
更好的上下文建模:通过引入句子顺序预测任务,ALBERT能够更好地捕捉上下文信息,提供更准确的文本向量化表示。
缺点:
损失一定性能:为了减少模型的复杂度和参数数量,ALBERT采用了参数共享机制,这可能会导致模型性能略微下降。相比于原始的BERT模型,在一些复杂任务上,ALBERT的表现可能不如BERT。
无法处理长文本:由于ALBERT将输入文本划分为若干个片段,这使得其在处理长文本时存在局限性,可能无法完全捕捉到全局的上下文关系。
总结:
ALBERT是一种轻量级的BERT模型,通过参数共享、句子顺序预测和文本段落划分等技术来减少模型复杂度,提高训练和推理效率。它具有轻量级模型、高效训练和推理以及更好的上下文建模等优点。然而,ALBERT也面临性能损失和无法处理长文本的缺点。在实际应用中,可以根据任务需求和资源限制选择合适的ALBERT模型,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
from transformers import AlbertTokenizer, AlbertModel
import torch
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化ALBERT tokenizer
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
# 初始化ALBERT模型
model = AlbertModel.from_pretrained('albert-base-v2')
# 将文本转换为ALBERT向量表示
def text_to_albert_vector(text):
# 分词并添加特殊标记
tokens = tokenizer.encode_plus(text, add_special_tokens=True, return_tensors='pt')
# 使用ALBERT模型获取隐藏状态
with torch.no_grad():
outputs = model(**tokens)
hidden_states = outputs.last_hidden_state
# 取最后一层的CLS标记的隐藏状态作为句子向量
sentence_vector = hidden_states[:, 0, :]
return sentence_vector.squeeze().tolist()
# 对数据集中的每个样本进行向量化
vectors = [text_to_albert_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"ALBERT Vector: {vector}")
print()
(13)USE
USE(Universal Sentence Encoder)是一种通用句子编码器,用于文本向量化表示。它可以将不同长度和语言的句子映射到固定维度的向量空间中,从而实现文本的语义表示。下面将详细介绍USE算法的原理,并分析其优点和缺点。
算法原理:
USE算法具有以下关键思想和原理:
双塔架构:USE采用了双塔(Dual-Tower)架构,其中一个塔用于编码输入文本,另一个塔用于计算相似度得分。这样可以同时考虑句子级别和上下文级别的信息,提高了句子编码的质量和准确性。
Transformer模型:在编码文本的塔中,USE使用Transformer模型进行序列建模。Transformer模型能够通过自注意力机制有效地捕捉句子中的语义和上下文关系,提供更准确的句子编码。
多任务学习:为了提高句子编码的泛化能力,USE采用了多任务学习的方法。除了常见的语义相似度任务,还包括情感分类、问答等任务。这样可以使模型学习到更丰富的语义信息,提高句子编码的效果。
优点:
通用性:USE是一个通用的句子编码器,适用于不同语言和不同长度的句子。它可以将任意文本映射到固定维度的向量空间中,提供一致的语义表示。
高质量句子编码:通过采用Transformer模型和多任务学习的方式,USE能够捕捉句子的语义和上下文关系,提供高质量的句子编码。这使得它在许多自然语言处理任务中具有良好的表现。
快速推理速度:由于USE使用了轻量级的Transformer模型,它具有较快的推理速度。这使得在实时应用或资源受限的环境中能够高效地进行文本向量化。
缺点:
固定维度表示:USE将不同长度的句子映射到固定维度的向量空间中,这可能导致信息损失。对于某些需要考虑上下文细节的任务,固定维度表示可能无法提供足够的精确度。
依赖预训练:USE模型通常需要在大规模数据上进行预训练,然后再进行微调或特定任务的训练。这可能会带来数据收集和标注的难题,并且对计算资源要求较高。
总结:
USE是一种通用的句子编码器,通过采用双塔架构、Transformer模型和多任务学习等技术来实现高质量的句子编码。它具有通用性、高质量句子编码和快速推理速度等优点。然而,固定维度表示和依赖预训练的缺点需要在具体应用中加以考虑。在实际应用中,可以根据任务需求选择合适的USE模型,并结合其他技术手段来解决其缺点,以提高文本向量化的性能和效果。
Demo代码实现如下所示:
import tensorflow_hub as hub
import tensorflow_text
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化USE模型
use_model = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual/3")
# 将文本转换为USE向量表示
def text_to_use_vector(text):
# 使用USE模型获取句子的向量表示
embeddings = use_model([text])
sentence_vector = embeddings[0].numpy()
return sentence_vector
# 对数据集中的每个样本进行向量化
vectors = [text_to_use_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"USE Vector: {vector}")
print()
(14)LASER
LASER(Language-Agnostic SEntence Representations)是一种用于文本向量化的算法,它能够生成语言无关的句子表示。下面将对LASER算法的原理进行详细介绍,并讨论其优点和缺点。
LASER算法原理:
对齐阶段(Alignment):LASER首先通过一个字级别的对齐模型来捕捉不同语言之间的对应关系。它使用了一个多层的双向LSTM模型来学习两种语言之间的字级别对齐。
编码阶段(Encoding):在这个阶段,LASER使用了一个预训练的大规模翻译模型将每个语言的句子对翻译成另一种语言。然后,利用这些翻译对来对齐两种语言的句子表示。之后,通过一个双向LSTM模型对句子进行编码,得到每个句子的固定长度表示。
聚合阶段(Aggregation):在这个阶段,LASER使用均值池化操作将每个句子的编码向量转换为一个固定长度的向量。这样,每个句子都被表示为一个语言无关的向量。
LASER算法的优点:
语言无关性:LASER算法能够生成语言无关的句子表示,使得它可以在多种语言之间进行有效的跨语言文本处理。
高质量的句子表示:LASER使用预训练的大规模翻译模型和对齐模型来生成句子表示,这有助于捕捉句子的上下文信息和语义含义,提供更丰富和准确的句子表示。
灵活性:LASER算法可以用于各种自然语言处理任务,如文本分类、信息检索、机器翻译等,而不依赖特定任务的特征工程。
LASER算法的缺点:
计算资源要求高:由于LASER使用了大规模的翻译模型和对齐模型,因此需要较大的计算资源和存储空间。这可能会限制其在资源受限环境中的应用。
依赖翻译对:LASER算法在编码阶段需要使用翻译对来对齐两种语言的句子表示。这意味着如果没有可用的翻译对,就无法得到准确的结果。
对稀有语言的支持有限:由于LASER是通过翻译模型进行训练,其性能可能会受到训练数据中稀有语言样本数量的限制。
综上所述,LASER算法通过对齐、编码和聚合阶段来生成语言无关的句子表示。它具有语言无关性和高质量的句子表示的优点,但也存在计算资源要求高和对翻译对依赖的缺点。在实际应用中,需要根据任务需求和环境限制来评估是否适合使用LASER算法。
Demo代码实现如下所示:
import numpy as np
from laserembeddings import Laser
# 生成数据集
dataset = [
"I love coding",
"Coding is fun",
"Python is awesome"
]
# 初始化LASER模型
laser = Laser()
# 将文本转换为LASER向量表示
def text_to_laser_vector(text):
# 使用LASER模型获取句子的向量表示
embeddings = laser.embed_sentences([text], lang='en')
sentence_vector = np.array(embeddings)
return sentence_vector
# 对数据集中的每个样本进行向量化
vectors = [text_to_laser_vector(text) for text in dataset]
# 打印向量化结果
for i, vector in enumerate(vectors):
print(f"Text: {dataset[i]}")
print(f"LASER Vector: {vector}")
print()
"""
模型文件可以从这里下载:
https://github.com/facebookresearch/LASER
"""欢迎补充!