论文Title:Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation。发表于2014年。
本文是计算机视觉目标检测领域的奠基作,提出了R-CNN模型,指定了一类目标检测流程的范式,后期目标检测的算法都受其影响。
R-CNN中的R为 region,即目标检测候选框的意思。名字直接告诉我们,该工作就是对候选框进行CNN操作,提取出其特征,再对特征进行分类等处理。
R-CNN提出对候选框进行偏移调整,用一个回归模型提高候选框框中物体的能力。
此外,R-CNN研究提出将卷积神经网络提取特征的可视化,属于深度神经网络的可解释性研究。
下面是我读这篇论文自己整理的内容,以及自己的思考总结。
文章目录
背景
R-CNN的提出,解决了当时两大问题:
①如何使用深度神经网络来训练一个高效的模型,用于定位物体。
这之前目标检测基本都是用传统的计算机视觉方法。
文章提出了两阶段范式(先生成候选框,再对候选框进行分类+微调)。
R-CNN使用卷积神经网络提取候选框特征,再对特征进行分类。
同时还使用一个回归模型对候选框的位置进行微调。
②目标检测可使用的数据少。
提出了“先监督式预训练,后在特定领域微调”这一范式。
即使用fine tuning的迁移学习技术。
R-CNN流程的3个模块
- 1、将一个图像生成多个候选框
- 2、将候选框用一个大型的卷积神经网络提取特征,每一个候选框提取出一个固定长度的特征向量。
- 3、对提取出来的向量使用线性支持向量机(Linear SVM)进行类别预测,每个类别都训练一个线性支持向量机来预测是否是当前类别。
- [同时] 对提取出来的向量同时进行偏移量的预测,使用回归模型,用于对候选框的定位进行微调。
下图是论文中给的R-CNN流图(图中没有画回归模型):
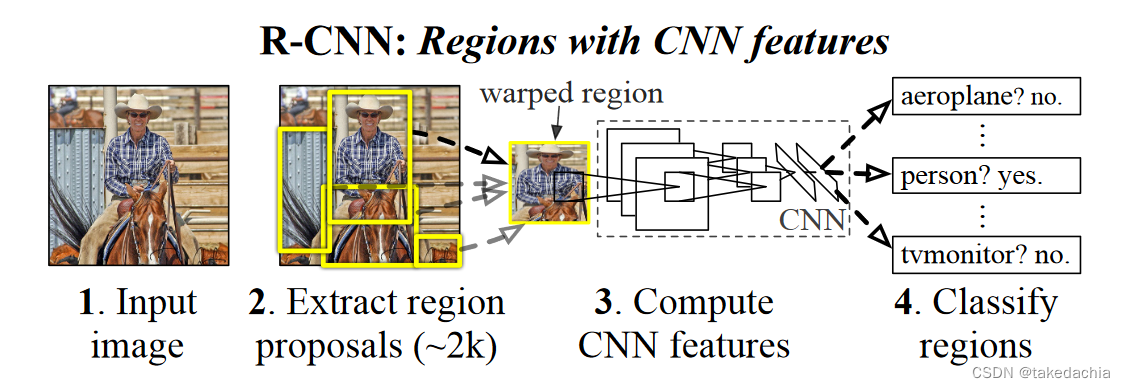
细节1:生成候选框
使用selective search方法,即聚类产生初始分割区域,其根据颜色、纹理、大小、形状相似度加权合并产生不同层次的2000个左右的候选框。
把它当成一个随机生成候选框的算法即可,这里没有和网络相关的可学习参数。

细节2:对候选框进行特征提取
先对候选框进行缩放,缩放成227×227的RGB图像。缩放细节:将候选框向四周扩展16个像素,然后强行缩放成227×227大小。如下图的缩放效果。
之后进行mean-subtracted处理,即减去均值。

之后喂给卷积神经网络模型(文中使用的AlexNet,所以读入的是227×227的图像),最后提取到一个4096维的向量。
主干流程:模型测试阶段
根据前面提到的3+1个模块的设计,具体流程为:
- 传入一个图像,使用selective search方法,生成2000个候选框,进行缩放。
- 缩放后喂到CNN模型中,抽取到一个4096维的向量。这一步是最耗时的。
- 对该向量用训练好的线性SVM分类器预测各个类别(每个类别都有一个线性SVM分类器)。
第2步中得到的是一个2000×4096(候选框数×向量长度)的矩阵,这里乘以一个4096×N的矩阵(N为类别数,即为训练好的SVM),就可以得到各个类别置信度。
最后,使用NMS算法(非极大值抑制)剔除多余的重复预测的候选框。
此外在分类预测的同时,还会同时对候选框进行偏移的预测,将其修正到更准确的位置。
下面这张示意图将这个模型的流程概括得很清晰(图摘自b站up“同济子豪兄”的R-CNN论文解读):
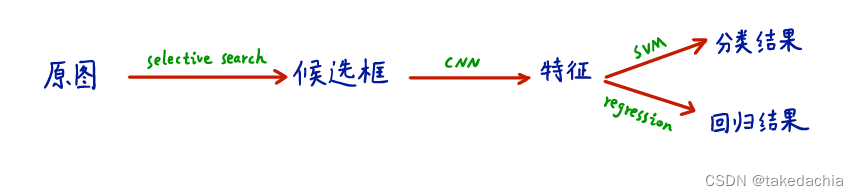
主干流程:模型训练阶段
详述一下训练模型时的细节。
1 CNN模型的训练
①使用预训练模型+微调(fine tuning)的方式进行训练
在第二个模块的CNN模型中,使用了ImageNet图像分类数据集的预训练模型(作者使用的AlexNet),将该预训练模型使用微调(fine tuning)的迁移学习方法应用到VOC目标检测数据集上。(这个方法可解决目标检测数据量少的问题)
具体就是将VOC数据集上的候选框作为训练集,进行缩放,然后喂入CNN模型进行微调训练。其中CNN模型中最后一个全连接层的原1000个输出改成21个,对应PASCAL VOC 2012数据集20个类别+1个背景类。
背景类即未被有效框中的候选框代表的类。
注意,我们在训练CNN模型时,最后一层21个类别的输出仅用作训练,以训练出一个特征提取器。
我们参考一下AlexNet的结构:
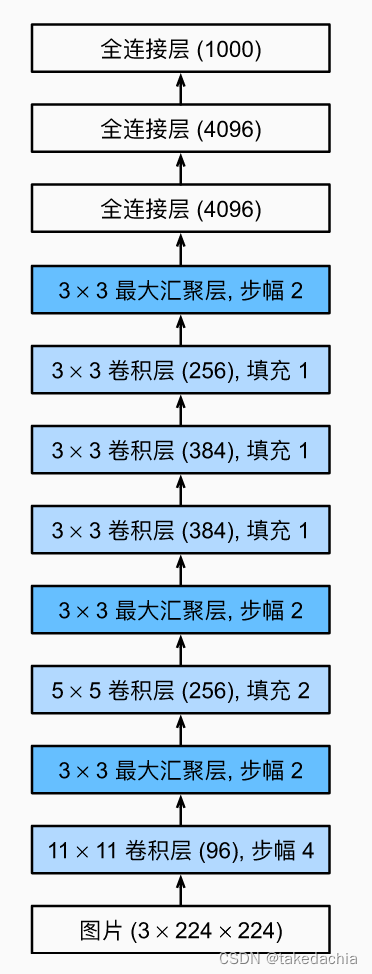
最后一个全连接层改成21个输出后得以训练整个模型,但我们最后需要用到的是倒数第二层全连接层(甚至用再往前池化层的输出)提取到的4096维的向量,我们需要依靠它进行在测试阶段进行分类。分类的方法使用线性SVM分类器,下文会讲。
②生成训练数据集
那么训练的样本怎么来的呢?
我们知道一开始拥有一些Ground Truth,即人工标注的框,但数量极少,拿来训练不现实。
我们还有大量的通过selective search生成的候选框,我们就可以对候选框通过处理标注,使其成为训练样本。
那么如何标注呢?
首先,我们将训练样本分成正样本和负样本,正样本指标注为20个分类的候选框,负样本指标注为背景类的候选框。
如何区分正样本和负样本?这里使用了IoU(交并比)的概念,来衡量一个候选框是否有效地框中了目标。
如下面两张图展示的:
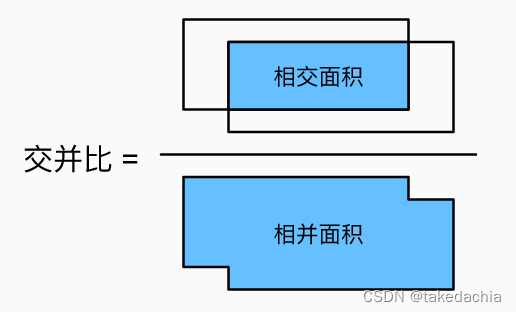

我们将一个候选框(如上图淡蓝色的框)和这一张图片中的所有Ground Truth(如上图的红框,图中就1个GT框,实际上可以有多个,代表多类)做对比,计算出各个IoU值,得到最大的IoU值和对应的类别。
我们将IoU>0.5的候选框视作正样本。比如,候选框有效地框中了bird,即为bird的正样本。
未有效框中bird,而是框中了树枝和远处的绿色,即为bird的负样本,视作背景类。
这样我们的训练集就生成了,既有那20类的候选框,又有背景候选框。
③解决训练集中类别不平衡的问题
以上生成的训练集中,负样本(背景类样本)的数量仍占绝大多数,直接拿来训练会造成类别的不平衡,模型识别正样本的能力下降。
所以在训练时,需要保证一个批量的数据中,正样本有一定的比例(比如文中所描述的一个128数量的批次中,要有32个正样本和96个负样本)。
由于正样本数量远远小于负样本,这样需要对正样本进行过采样,对负样本进行欠采样,通过重采样以达到类别相对均衡。
2 线性SVM分类器的训练
①训练线性SVM
每个类别都会训练一个线性SVM的二分类器。
我们使用CNN网络提取到的特征(即一个候选框对应的一个4096维向量),对其进行一个二分类的判断。比如判断它是不是bird。这是一个bird的二分类器。
我们还可以再训练一个car的二分类器。这样依次训练20个类别各自的二分类器。
②生成训练数据集
分类“car”的二分类器为例,一个二分类器肯定也需要一定“car”正样本和非“car”的负样本(可以是框到car的很小一部分;也可以是背景,甚至是别的类别)。
这个二分类器的训练集数据又是怎么来的呢?
想想前面训练的CNN特征提取器,它会在IoU>0.5时就能识别出一辆“car”,一方面这样模糊识别的能力比较强,这样能抽取出五花八门的car特征;另一方面训练CNN时正样本少,需要相对低一点的IoU值要求来凑出更多的正样本来。
但是现在的二分类器需要严格地识别一辆相对完整的car,判别这是一辆car的可能性,毕竟有20个类别等着你去对比可能性大小。(此外后面会讲到,我们还需要预测这个候选框的定位信息,这个定位信息需要和一辆完整car的特征信息去对比,预测出定位的偏移)因此,在训练二分类器的时候,正样本和负样本和前面训练CNN的时候不同。
这里,正样本是数据集本身标注的Ground Truth框。
如果IoU小于0.3,视为训练的负样本。(注意如果IoU大于0.3的样本则不用来训练,被抛弃掉)
训练的时候也应当要注意正负样本的均衡。
③难分辨的负样本的挖掘(hard negative mining)
R-CNN还使用了 hard negative mining,即将难分辨的一些负样本的数据作为“一本错题集”,加入到下一轮的训练中。
这样也能提升分类器的性能。
思考:为什么要用SVM分类,而不在CNN模型中直接以softmax分类作为结果
这个问题归根结底和训练数据少有关。
在CNN模型训练中,我们的正样本数量不够,所以需要降低IoU值的要求,将IoU>0.5的候选框一并归为训练集正样本,让模型能学习。这样的设计,明显可以看出其在定位性能上会有一定的损失(毕竟半辆车都拿来凑合着学了,最后预测时也就只能认识框中的半辆车)。
假使我们的样本足够多(比如框足够多),不应当降低IoU的要求,而将正好框中的目标候选框视为正样本,这样也就没有定位性能损失的问题。
所以无奈作者将预测地没那么好的候选框特征(即用CNN提取出来的4096维特征向量)人为地进行二次处理,将其特征信息拆分为分类+偏移预测(后文讲述)。
作者做了一些预实验,发现对训练时需要对正负样本进行划分,在训练CNN特征提取器时和对候选框进行分类使用不同的正负样本进行训练,会提高mAP(模型的性能)。对候选框进行分类时,我们需要更严格地划分正负样本,正样本就得是Ground Truth框。
如前文示意图所示,偏移预测就是下文需要讲的Bounding box Regression。
3 候选框偏移量的预测(Bounding box Regression)
因为候选框不可避免地会产生定位误差,所以我们可以对生成的候选框进行偏移修正。
Bounding box regression是受DPM算法的启发的,它通过训练一个线性回归模型,给予一组特征(CNN提取的特征),来预测一个新的检测框,这个新框的偏移量是这个Regression预测的目标。
这个偏移量是相对于正确位置(如Ground Truth框完整地框中某个目标)的偏移量,偏移量通过一组偏移系数计算得到,而偏移系数则是学出来的。
下面结合论文和我的思考细讲一下Bounding box Regression干了一件什么事。
我把这部分内容放到了另一篇子文章中:R-CNN 之预测框回归(Bounding box regression)问题详述
R-CNN的一些思想和贡献
以上是R-CNN进行目标检测任务的主干内容,再讲讲论文其他涉及的一些贡献和思想。
其中,预测框回归(Bounding box regression)已详细在主干部分讨论。
将学到的特征可视化(神经网络可解释性研究)
R-CNN也是卷积神经网络可解释性分析的奠基作之一(其它工作如还有ZFNet等)。R-CNN提出了一个可视化方法,直观地展示网络学到了什么东西。
①关于神经元的激活值activation
先复习两个概念:
在CNN模型中,一个层的输出一般是:长×宽×通道数,其中矩阵中的每个数代表一个神经元neuron。
每一个层的输出称为这一组神经元的激活值activations,它会被传入下一层作为输入。
论文中提到的激活值activation就是某个通道中输出的数。
作者提出的将学到特征可视化的方法,就是寻找能够使AlexNet中某些神经元激活值最大的图片区域。什么意思呢?
②激活值对应原图感受野
下面自己画了张图,展示某层的激活值对应的原图感受野。一张227×227的图片传入AlexNet网络,它最后一个池化层pool5的输出的feature map是6×6大小,有256个通道。
我们取池化层输出的第1个通道上的(3,3)这个激活值(红色小块),对应到原图就是一个195×195的感受野。并且(3,3)这个位置靠近中心,几乎就覆盖了原图的绝大部分区域。
池化层输出的256个通道我们可以把它视作256个高等级的语义特征类,比如假设第1个通道代表了“光晕”特征,第2个通道代表了“平行纹理”等等。
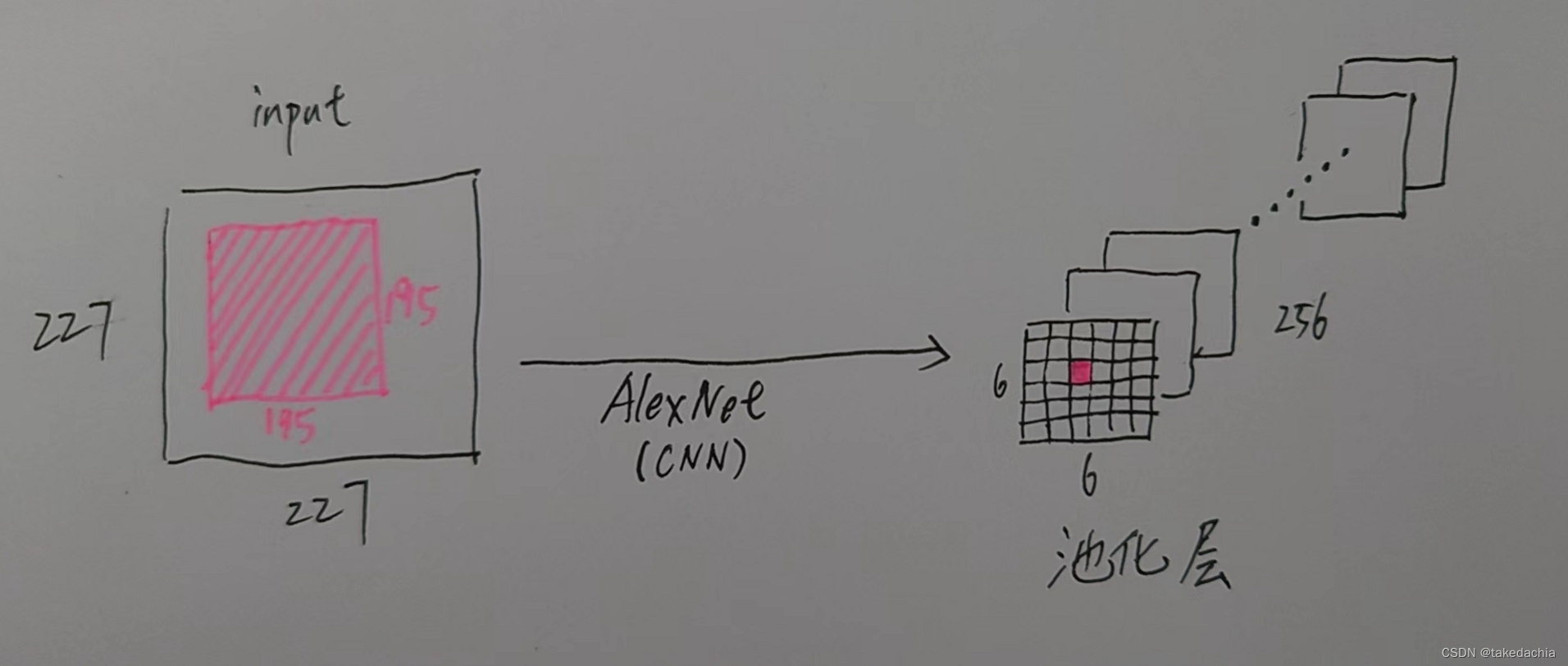
那么,在池化层输出的第1个通道上(3,3)处的激活值越高,意味着原感受野处“光晕”特征的可能性越大。
于是我们就可以根据池化层输出的各个通道上,某个指定神经元的激活值的大小,来分析原图感受野中提起到的特征是否正确、合理。这样就可以对卷积神经网络提取到的特征进行可视化了!
③作者的做法
作者是怎么做的呢?
作者将整个数据集的所有的候选框(大约有1000万个)喂入卷积神经网络,提取到池化层输出的特征(6×6×256)。
各通道中,每个6×6的feature map中选取(3,3)处的激活值代表原图的大部分感受野。对该通道的激活值进行横向的从大到小排序,找激活值排名靠前的候选框,展示出感受野的部分。
这样,每个通道类别中,那些激活值高的,可以可视化出一组提取得很棒的特征。
那么这个通道类别就可以进行可解释性分析了。
我们看论文原图中,第1行就是那些激活值排名最高的通道单元,对应原图候选框的感受野,这里提取到的是people的高级语义特征。
第2行提取到的是dot(点阵)的高级特征,其中我们可以发现狗的脸部也被归类为了点阵信息,因为狗的两只眼睛和鼻子也像是点阵。

fine tuning的作用、全连接层的意义(消融对照实验)
作者对比了带和不带fine tuning的训练对模型性能的评估。
并且依次去掉AlexNet最后两个全连接层,观察对性能的影响。
结果如下图(注解摘自b站up“同济子豪兄”):
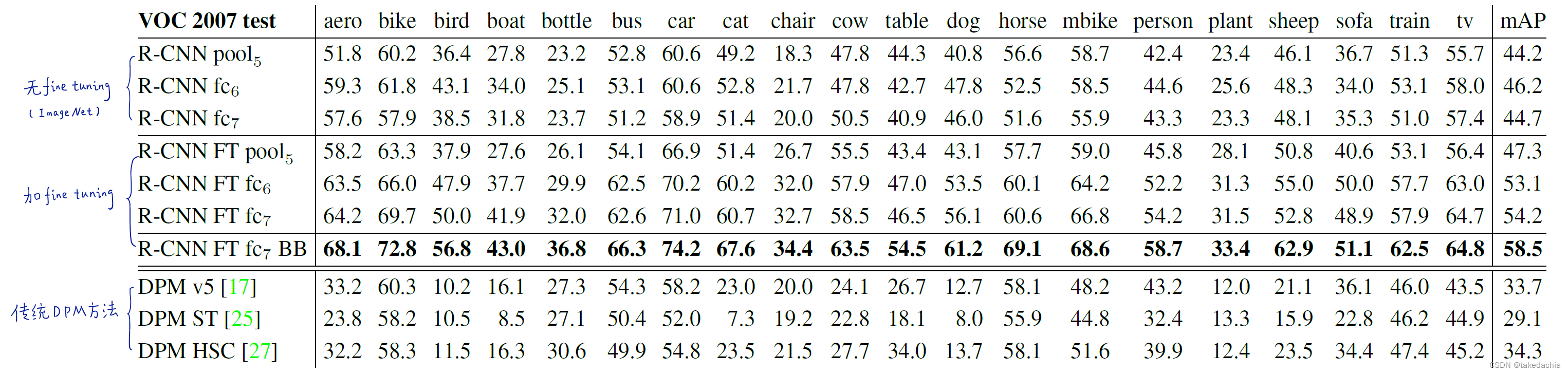
图中显示,使用fine tuning训练的模型,性能提升显著。
并且在使用fine tuning训练的时,全连接层的作用很明显(图中mAP 47.3提升至54.2);相比不带fine tuning训练的模型,全连接层的作用并不明显(图中mAP 44.2到44.7提升不明显)。
这可能说明,在使用预训练模型进行迁移学习时,CNN提取的是通用的特征,而全连接层fc完成的是特定领域的任务。
文中最后提到,“supervised pre-training/domain-specific fine-tuning”(先监督式预训练,后在特定领域微调)这一范式,对数据量相对较少的计算机视觉领域是一个解决问题的趋势。
参考资料:
https://academic.hep.com.cn/foe/article/2019/2095-2759/2095-2759-12-3-324.shtml
https://towardsdatascience.com/deep-learning-method-for-object-detection-r-cnn-explained-ecdadd751d22
https://aman.ai/cs231n/visualization/#visualizing-internal-representationsactivations