各位炼丹道友在阅读本文前,贫道先简要介绍下文章内容:本系列适用于利用mmseg算法库法宝做语义分割毕业设计及写研究论文的本科生及研一道友,在本系列中,炼丹代师我会介绍全新无伤的使用mmsegmentation算法库法宝方法,以及一些常见的改进方法(包括但不限于backbone改进:更换backbone/使用空洞卷积/插入即插即用的各种注意力模块;分割头改进:更换分割头/设计辅助分割头;损失函数改进:多损失函数设计/损失函数按分割类别优化权重/按损失函数类别优化权重)。诚然,贫道认为这些创新还是不足以各位道友渡过小论文之劫的,请各位道友理性看待,仅供参考学习!
文章目录
mmsegmentation法宝介绍
此处借大修士宗门OpenMMLab的介绍:
MMSegmentation 是 OpenMMLab开源项目里的语义分割领域的算法工具箱,它实现了许多高质量语义分割算法模型和数据集,也为语义分割任务提供了统一的框架和基准测试。
此法器主要特性如下:
1.统一的基准平台:
将各种各样的语义分割算法集成到了一个统一的工具箱,进行基准测试。
2.模块化设计:
MMSegmentation 将分割框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的分割模型。
3.丰富的即插即用的算法和模型:
MMSegmentation 支持了众多主流的和最新的检测算法,例如 PSPNet,DeepLabV3,PSANet,DeepLabV3+ 等.
4.速度快:
训练速度比其他语义分割代码库更快或者相当。
为方便各位同道进一步了解此法宝,贫道再此附上几座传送阵:
各位道友想安装此法宝的请走这一通道:mmseg安装方法
各位道友想进一步研究此法宝的请走这一通道:mmseg文档介绍
(贫道再此认为诸位同道皆练气十层以上,懂得cuda/cudnn/pytorch的安装配置之法,如有道友在此境界之下,请移步至此传送阵查看安装配置之法)
无伤使用法宝之法
自此法宝面世之初,就有不少同道给出了祭炼之法,吾观之皆有伤于法宝本身及使用者,多数祭炼之法皆需要修改mmseg底层代码和原本的config文件,如此一来,数据集便无法通用,需一跑一改。此外,多数祭炼之法无法供使用者对所使用的网络以直观可修改的认知,以至只知道跑不知道改的无奈现状,贫道遂苦寻变通之法,在吾观B站某道友讲解mmdetection算法库工具时灵感突发,实验之,成之,遂分享于各位同道。(再次强调:仅供参考,有事无找)
1.print_config妙用之法
对mm系列算法库有一定了解的道友都知道其运行时需要调用config文件完成模型构建及模型学习策略、保存等许多重要参数的初始化,然而,因此,若能将config文件配置之法掌握于自己手中,便可将模型重要参数紧握于自己手中,如此一来,可跑可改!然而,当我们打开mmseg算法库中的config文件时,却是另一番景象。这里以FCN 的config文件为例(resnet50d为backbone):
 很明显,FCN的config文件调用了backbone、数据增广、运行策略、学习策略的config初始config文件,因此,道友们在修改模型和训练自己数据集时需要针对这些config文件一一进行修改,此法也是诸多同道祭炼之法的根本。贫道认为此乃下策,首先不说一个一个文件的改很麻烦,倘若改完后你想跑公共数据集是不是还得改回去,因此,当前mmseg算法库config文件缺少一种独立、一体的使用方法。
很明显,FCN的config文件调用了backbone、数据增广、运行策略、学习策略的config初始config文件,因此,道友们在修改模型和训练自己数据集时需要针对这些config文件一一进行修改,此法也是诸多同道祭炼之法的根本。贫道认为此乃下策,首先不说一个一个文件的改很麻烦,倘若改完后你想跑公共数据集是不是还得改回去,因此,当前mmseg算法库config文件缺少一种独立、一体的使用方法。
至此,在下向各位道友介绍print_config函数,虽然不知道此函数之前有何妙用,但当前下其功能却很适合我们跑算法和该模型,它可以对config文件夹下任意算法的config文件导出,而且导出条目很清晰,其运行命令如下:
python tools/ print_config.py configs/fcn/fcn_r50-d8_512x512_20k_voc12aug.py(原始config文件地址)
my_config/fcn.py(目标config地址)
其效果如下:
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=dict(type='SyncBN', requires_grad=True),
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='FCNHead',
in_channels=2048,
in_index=3,
channels=512,
num_convs=2,
concat_input=True,
dropout_ratio=0.1,
num_classes=2,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=2,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
train_cfg=dict(),
test_cfg=dict(mode='whole'))
dataset_type = 'PascalVOCDataset'
classes = ('background', 'leaky oil')
palette = [[128, 0, 0]]
data_root = 'data/VOCdevkit/VOC2012'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
classes=('background', 'leaky oil'),
palette=[[128, 0, 0]],
ann_dir=['SegmentationClass'],
split=[
'ImageSets/Segmentation/train.txt'
],
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]),
val=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
classes=('background', 'leaky oil'),
palette=[[128, 0, 0]],
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='PascalVOCDataset',
data_root='data/VOCdevkit/VOC2012',
img_dir='JPEGImages',
classes=('background', 'leaky oil'),
palette=[[128, 0, 0]],
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
log_config = dict(
interval=100, hooks=[dict(type='TextLoggerHook', by_epoch=False)])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = 'checkpoints/fcn_r50-d8_512x512_20k_voc12.pth'
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
lr_config = dict(policy='poly', power=0.9, min_lr=0.0001, by_epoch=False)
runner = dict(type='IterBasedRunner', max_iters=10000)
checkpoint_config = dict(by_epoch=False, interval=1000)
evaluation = dict(
interval=1000, metric=['mIoU', 'mDice', 'mFscore'], pre_eval=True)
work_dir = 'work_dir/fcn'
gpu_ids = range(0, 2)
auto_resume = False
各位道友可以清楚的看到在一个文件中就集成了模型、数据加载、学习策略、运行策略等多个重要的config,而且其独立于mmseg算法库自带的config文件,不会影响底层代码。
至此,使用自己数据集跑mmseg算法库及做改进的任务就实现了一大步!
2.具体训练方法
这里以VOC数据集为例讲解,不知道将自己数据集转化成VOC数据集的道友请移步至贫道的博客:快速制作自己的VOC语义分割数据集
2.1 数据集准备
在准备好VOC2012数据集之后,其文件格式如下:

在mmsegmentation算法库目录下创建data文件夹,在data文件夹下创建VOCdevkits文件夹,在VOCdevkits文件夹将VOC2012复制拷贝过去,至此,完成数据集准备工作。
2.2 配置文件导出
在mmsegmentation文件夹下创建my_config文件夹用于存放自己的配置文件,找到自己想跑的模型的配置文件地址,使用如下指令完成配置文件导出:(以fcn为例)
python tools/ print_config.py configs/fcn/fcn_r50-d8_512x512_20k_voc12aug.py
>my_config/fcn.py
2.3 配置文件修改
1)删除第一行config:
2)修改decode head中的num_class和auxiliary head中的num_class为自己的训练类别数
3)增加classes和palette(在train/val/test下都要加)
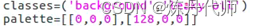
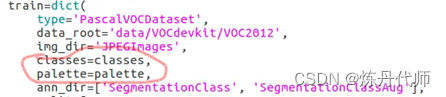
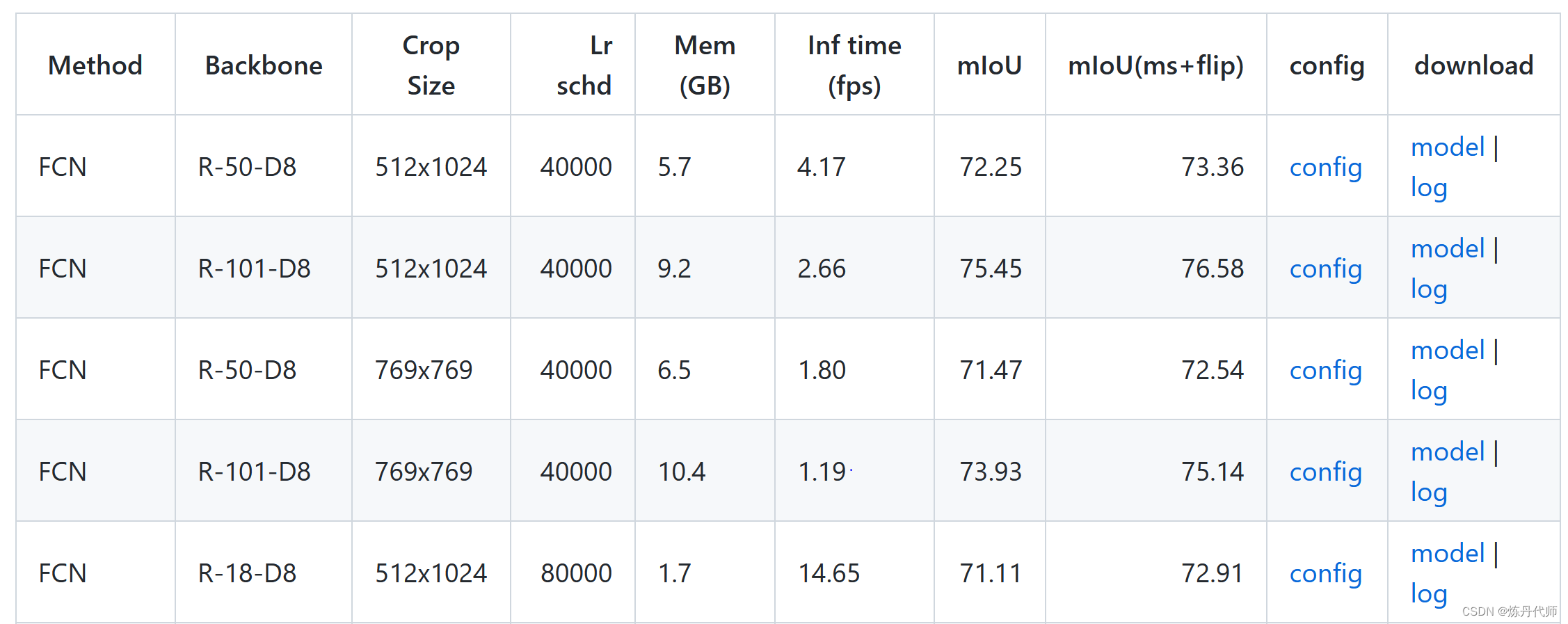
4)修改学习率,在mmseg的github中有log日志,打开后使用ctrl+F搜索nGPU,对比自己的GPU数量对学习率做缩放;在页面上点击model项下载预训练权重(log地址和下载地址)

 5)预训练权重加载
5)预训练权重加载
在mmsegmentation文件夹下新建checkpoint文件夹,将下载的预训练权重放在此文件夹下,在config文件中修改load_from参数:
 6)增加评价指标:
6)增加评价指标:

注意:对于新增类别,注意在mmseg/dataset/下对应的数据集管理文件voc.py补充类别及对应的配色,注意类别与配色要一一对应
至此完成所有配置文件修改工作
2.4 训练测试可视化命令
训练命令:
bash tools/dist_train.sh 1.py(对应配置文件地址) 2 –work-dir work_dir(模型保存地址)
测试命令:
bash tools/dist_test.sh my_config/fcn.py work_dir/fcn/latest.pth –show-dir work_dir/fcn/out --eval mIoU --out result.pkl
可视化
python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
python tools/analyze_logs.py log.json --keys loss --legend loss
FPS指标
python ./tools/benchmark.py my_config/fcn.py work_dir/fcn/latest.pth
总结
以上就是今天要讲的内容,本文仅仅介绍了无伤使用mmsegmentation算法库,下期介绍模型改进方法。
往期回顾:
(1)CBAM论文解读+CBAM-ResNeXt的Pytorch实现
(2)ShuffleNet-V1论文理解及代码复现
(3) ShuffleNet-V2论文理解及代码复现
(4)GhostNet论文理解及代码复现
(5)PS才是真科研利器,助力快速分割标注工作
(6)快速制作自己的VOC语义分割数据集
下期预告:
mmsegmentation算法库任意语义分割算法改进方法