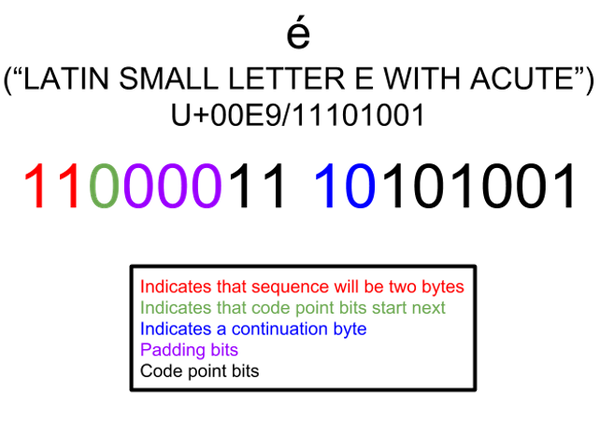分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请点击http://www.captainbed.net
UTF-8 is a variable-width character encoding standard that uses between one and four eight-bit bytes to represent all valid Unicode code points.
UTF-8 Basics
UTF-8 (Unicode Transformation–8-bit) is an encoding defined by the International Organization for Standardization (ISO) in ISO 10646. It can represent up to 2,097,152 code points (2^21), more than enough to cover the current 1,112,064 Unicode code points.
Instead of characters, it is actually more correct to refer to code points when discussing encoding systems. Code points allow abstraction from the term character and are the atomic unit of storage of information in an encoding. Most code points represent a single character, but some represent information such as formatting.
UTF-8 is a “variable-width” encoding standard. This means that it encodes each code point with a different number of bytes, between one and four. As a space-saving measure, commonly used code points are represented with fewer bytes than infrequently appearing code points.
Backward compatibility with ASCII
UTF-8 uses one byte to represent code points from 0-127. These first 128 Unicode code points correspond one-to-one with ASCII character mappings, so ASCII characters are also valid UTF-8 characters.
How UTF-8 works: an example
The first UTF-8 byte signals how many bytes will follow it. Then the code point bits are “distributed” over the following bytes. This is best explained with an example:
Unicode assigns the French letter é to the code point U+00E9. This is 11101001 in binary; it is not part of the ASCII character set. UTF-8 represents this eight-bit number using two bytes.
The leading bits of both bytes contain meta-data. The first byte begins with 110. The 1s indicate that this is a two-byte sequence, and the 0 indicates that the code point bits will follow. The second byte begins with 10 to signal that it is a continuation in a UTF-8 sequence.
This leaves 11 “slots” for the code point bits. Remember that the U+00E9 code point only requires eight bits. UTF-8 pads the leading bits with three 0s to fully “fill out” the remaining spaces.
The resulting UTF-8 representation of é (U+00E9) is 1100001110101001.