
众所周知,在暗光增强任务中,要获取到适合的成对的暗光/正常曝光训练图像是非常困难的,甚至是不存在唯一的定义良好的正常曝光ground truth图片。如果用正常曝光的图像去合成带噪点的暗光图像作为训练集,很可能导致最终应用在真实世界中的测试出的图片人工伪影严重,泛化性差。
所以作者利用无监督的GAN技术,设计了暗光增强领域中第一个训练数据不成对的无监督网络,称为EnlightenGAN,创新主要在于全局-局部鉴定结构(global-local discriminator structure)、自正则感知loss函数(self-regularized perceptual loss fusion) 和 注意力机制。

EnlightenGAN利用注意力引导的U-Net作为生成器,用双鉴别器(global和local)来平衡全局和局部微光增强。此外,由于缺少ground truth,论文提出了一种自适应的也包含了global和local的perceptual loss来约束微光输入图像与其增强版本之间的特征距离,并与用于训练EnlighttenGAN的adversarial loss一起组成最终的loss,下面详细介绍:
Global-Local Discriminators
global-local discriminators可以获取到全局-局部信息,综合全局-局部来考虑,能够针对性地优化需要优化的区域,例如暗部进行提亮,亮部不会过曝。
global-local discriminatorys两者都使用PatchGAN进行真假鉴别。这里的PatchGAN是在全局上即整张输出图片与真实正常曝光图片对比是否为真;在局部上则是将输出图像进行裁剪成一块块小的patch,与真实正常曝光图片的小的patch进行对比是否为真。论文称此方法是避免过度增强或者增强不足的关键。
对于global discriminator,论文修改了标准的relativistic discriminator,创建了新的loss:
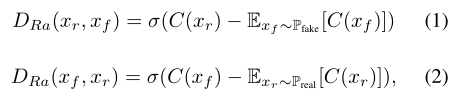
上是标准的relativistic discriminator,其中C表示鉴别器的网络,Xr和Xf是从真实分布和伪分布中抽样的,σ表示Sigmoid函数,用最小二乘GaN(LSGAN) loss代替Sigmoid函数。最后,全局鉴别器D和生成器G的loss 是:

对于local discriminator,每次从输出图像和真实图像中随机裁剪5个patches,采用未加修改的LSGAN作为对抗性损失:

Self Feature Preserving Loss
Perceptual losses for real-time style transfer and super-resolution是perceptual loss的出处。perceptual loss被广泛应用于许多低层视觉任务,例如去噪、超分辨率、去模糊等等(在我上一个博文的工作也用了perceptual loss)。作用是限制所提取的输出图像与其ground truth之间的特征距离,即计算两者的语义相似性。
不过有一点需要明确,常规的perceptual loss是计算输出和ground truth的特征距离,但是在EnlightenGAN中,数据是unpaired的,并没有成对的训练图像,同时也不存在真正的ground truth。
所以,作者将perceptual loss改为计算原始low light input图像和其被增强过后的图像的特征距离。
原因是基于作者的经验所得,在调整输入图像的像素强度范围时,VGG分类模型结果并不十分敏感。
作者这里的理解也被另一个研究所赞同:Psyphy: a psychophysics driven evaluation framework for visual recognition
这里加一下博主自己的理解:作者的调整图像像素强度范围用词为we manipulate the input pixel intensity range,其中的强度范围intensity range应该为亮度范围,即修改输入图像的亮度范围,对VGG的分类模型并没有产生多少影响;但是本工作最敏感的就是亮度信息,所以使用原生态的perceptual loss的效果欠佳。
关于上面的理解,博主自己没有看过引申出的那个论文,理解可能也有偏差,但是自己感觉应该就是这样,如果有错希望读者能够提出。
LSFP 是修改后的全局Self Feature Preserving Loss:
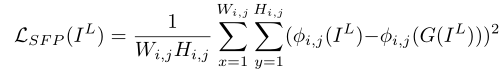
IL表示输入微光图像,G(IL)表示生成器的增强输出。φi,表示从在ImageNet上预先训练的VGG-16型提取的特征图。i表示它的第i个最大池化层,j表示它在第i个最大池层之后的第j个卷积层。Wi,j和Hi,j是提取的特征图的维度。默认情况下,选择i=5,j=1。
local 的SFP loss和global的一致,同时,在计算LSFP前加入了一个instance normalization来稳定训练,
最终的总的loss为:
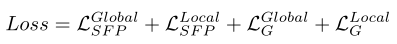
U-Net Generator Guided with Self-Regularized Attention
使用U-Net是因为其在语义分割、图像恢复等领域取得了不错的效果。
论文取输入rgb图像的光照通道I,将其归一化为[0,1],然后做1−I(逐元素差分)计算,得到self-regularized attention map。然后,修改attention map的大小以适应每个特征图,并将其与所有中间特征图以及输出图像相乘。
消融实验、与其他方法的对比和质量评估


质量评估

现实图片对比以及领域适配实验
因为EnlightenGAN的unpaired数据类型,以及无监督方法,所以能够很好地适配新的领域下的图片,得到不错的增强效果,下面EnlightenGAN-N是领域适配版本:

博主总结
- EnlightenGAN首创地在暗光增强领域使用GAN技术,利用unpaired数据,很好地解决了暗光增强领域(实际上是几乎所有底层图像处理)的没有真实的成对训练数据和ground truth的难题
- 利用U-Net设计的注意力机制提升了网络性能
- 升级了传统perceptual loss,使其更适应unpaired输入数据类型的网络
- 通过实验,验证了EnlightenGAN能够比其他方法更容易适配现实其他领域的暗光图片